GNN Encoder #1
Comments
|
Hi @legohyl, thank you for your interest!
It is possible to additionally use the euclidean distances among the coordinates to instantiate the edge features, following this work by the same team via an nn.Linear() projection. I used this formulation during my experiments. You can compute the pairwise distances either during data loading or within the model's forward pass via something like this (off the top of my head): ...and then pass this to nn.Linear() to make use of the distance along with the connectivity when encoding via the GNN. I believe that the GNNs, when receiving the coordinates as node features, can also implicitly build an approximation of the pairwise distances during message-passing.
Great catch! I believe this must have slipped by in the editing iteration cycles by multiple authors of the paper. I will make the discrepancy clear in the next version. I don't think this ordering of using Hope it helps! |
|
Thanks for the response! I looked through the original paper and got a better idea of the Gated GCN you were using. I seem to be running into this issue went trying to run your code, it seems like your BatchBeam class has some clashes. It appears your
|

|
@chaitjo I've also found this rather perplexing error in the code. It appears that a few of your
|

|
Hi @legohyl, I'll look into these issues and get back asap. Meanwhile, it would be helpful if you can provide your hardware and system information: GPUs, CUDA version, Python version, PyTorch version, anything else worth mentioning. |
|
Thanks! I noticed that this is also the same implementation in your Sure, here's the following information |
|
Is it possible to run with |
|
Hmm it's not very convenient for me to revert back to older versions, so I was just looking at the errors and it doesn't seem to be package related. But I could try and give it a shot. |
|
@chaitjo I installed using |
|
@legohyl Do you mean it works upon downgrading? I will check your issues from my side as soon as possible. Off the top of my head, there may be discrepancy across package versions about how int and float divisions are handled. In the NAR beam search method, For AR beam search methods, I am confident that the issue may be due to Python version mismatch. Is it critical for you to use Python 3.8? |
|
Yes, it works with your intended set of versions. I do think it's because of the Float/Long tensors. I found myself having to convert things back to Well, as I'm using a EC2 instance from my company, it's kind of the default. Though I think it can be avoided by just doing the tensor checks as asserts and return accordingly, instead of redeclaring with super. Because either way, we should not be receiving non-tensor inputs. |
|
@chaitjo it seems to be resolved by calculating |
Hello, I was looking through the code and comparing with what you shared in the paper, and it appears like theres some discrepancies. For example, I was interested in the GNN Encoder module. In the paper, it was presented as:
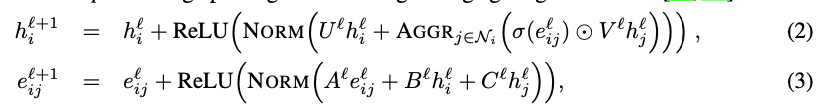
But in the code, in the
gnn_encoder.py, it was modelled differently. Firstly, in theGNNEncoderclass, you have an embedding (or dictionary) of size 2 to map an edge in the adjacency matrix (I presume here since it's of size 2, the adjacency matrix should be a binary matrix indicating connections and not weight). Why is this so though? In the paper, it was mentioned that you initialized the edge features using a Euclidean distance between points, and not just the connectivity. Also, we can see that this is passed onto theGNNLayer, which takes it as it is. This means that the initialization of the network will only ever have 2 different embeddings, and hence doesn't take into account the Euclidean distance between two nodes.In the
GNNLayer, the edge embedding gets updated different as opposed to the equation. Here's the code snippet:As you can see, you first updated the edge features by transforming them with the current layer representation followed by creating a gating mechanism with the
sigmoidfunction. This is then used to update the node information. However, in the paper, you wrote that the node features get updated bye_{ij}^{(l)}and not this new updatede_{ij}^{(l+1)}.The text was updated successfully, but these errors were encountered: