Architecture Overview
ChakraCore supports a multi-tiered architecture – one which utilizes an interpreter for very fast startup, parallel JIT compilers to generate highly optimized code for high throughput speeds, and a concurrent background GC to reduce pauses and deliver great UI responsiveness for apps and sites. Once the JavaScript source code for an app or site hits the JavaScript subsystem, ChakraCore performs a quick parse pass to check for syntax errors. After that, all other work in ChakraCore happens on an as-needed-per-function basis. Whenever possible, ChakraCore defers the parsing and generation of an abstract syntax tree (AST) for functions that are not needed for immediate execution, and pushes work, such as JIT compilation and GC, off the main thread, to harness the available power of the underlying hardware while keeping your apps and sites fast and responsive.
When a function is executed for the first time, ChakraCore’s parser creates an AST representation of the function’s source. The AST is then converted to bytecode, which is immediately executed by ChakraCore’s interpreter. While the interpreter is executing the bytecode, it collects data such as type information and invocation counts to create a profile of the functions being executed. This profile data is used to generate highly optimized machine code (a.k.a. JIT’ed code) as a part of the JIT compilation of the function. When ChakraCore notices that a function or loop-body is being invoked multiple times in the interpreter, it queues up the function in ChakraCore’s background JIT compiler pipeline to generate optimized JIT’ed code for the function. Once the JIT’ed code is ready, ChakraCore replaces the function or loop entry points such that subsequent calls to the function or the loop start executing the faster JIT’ed code instead of continuing to execute the bytecode via the interpreter.
ChakraCore’s background JIT compiler generates highly optimized JIT’ed code based upon the data and infers likely usage patterns based on the profile data collected by the interpreter. Given the dynamic nature of JavaScript code, if the code gets executed in a way that breaks the profile assumptions, the JIT’ed code “bails out” to the interpreter where the slower bytecode execution restarts while continuing to collect more profile data. To strike a balance between the amounts of time spent JIT’ing the code vs. the memory footprint of the process, instead of JIT compiling a function every time a bailout happens, ChakraCore utilizes the stored JIT’ed code for a function or loop body until the time bailouts become excessive and exceed a specific threshold, which forces the code to be re-JIT’ed and the old JIT code to be discarded.

ChakraCore has a two-tier JIT compiler. On the same concurrent background thread, ChakraCore has a Full JIT Compiler, which generates highly optimized code, and a Simple JIT Compiler, which is essentially a less optimizing version of the Full JIT. In the execution pipeline, ChakraCore first switches over from executing a function in the interpreter to executing simple JIT’ed code, then to fully optimized JIT’ed code once generated by Full JIT. In most cases, simple JIT compilation costs less time than full JIT compilation, therefore helps ChakraCore deliver a faster startup for apps and sites as compared to a single-tier JIT architecture. The other inherent advantage of having a Simple JIT tier is that in case a bailout happens, the function execution can utilize the faster switchover from interpreter to Simple JIT, till the time the fully optimized re-JIT’ed code is available. The simple JIT’ed code execution pipeline also continues to collect profile data which is used by the Full JIT compiler to generate optimized JIT’ed code.
ChakraCore also has the ability to spawn multiple concurrent background threads for JIT compilation whenever ChakraCore determines the underlying hardware to be potentially underutilized. For cases where more than one concurrent background JIT thread is spawned, Chakra’s JIT compilation payload for both the Simple JIT and the Full JIT is split and queued for compilation across multiple JIT threads. This helps reduce the overall JIT compilation latency – in turn making the switch over from the slower interpreted code to a simple or fully optimized version of JIT’ed code substantially faster at times.
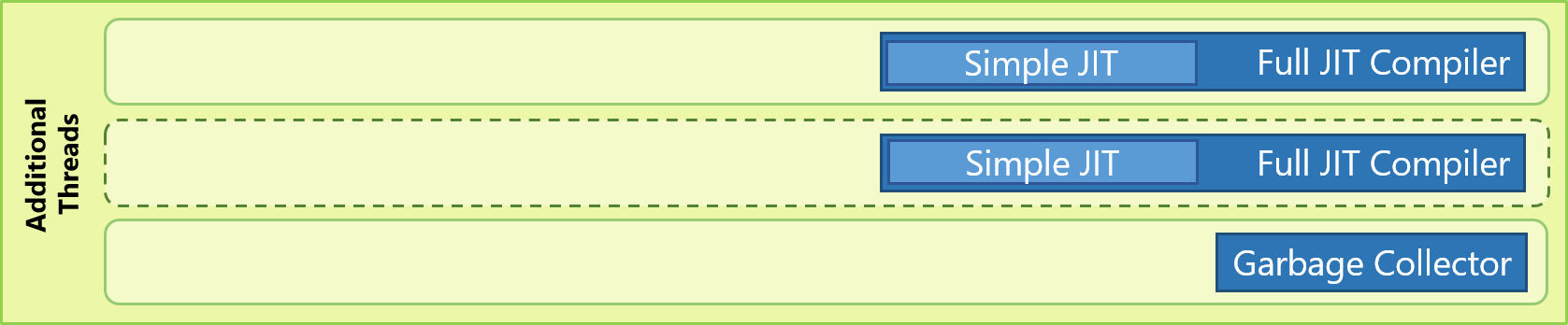
ChakraCore has a generational mark-and-sweep garbage collector that supports concurrent and partial collections. When a full concurrent GC is initiated, ChakraCore’s background GC would perform an initial marking pass, rescan to find objects that are modified by main thread execution while the background GC thread is marking, and perform a second marking pass to mark objects found during the rescan. Once the second marking pass is complete, the main thread is stopped for a final rescan, followed by a final marking pass that is split between the main thread and the dedicated GC thread is performed. After that, a sweep is performed mostly by the background GC thread to find unreachable objects and add them back to the allocation pool.
