-
Accuracy: Number of points classified correctly / total number of points on the scatter plot.
-
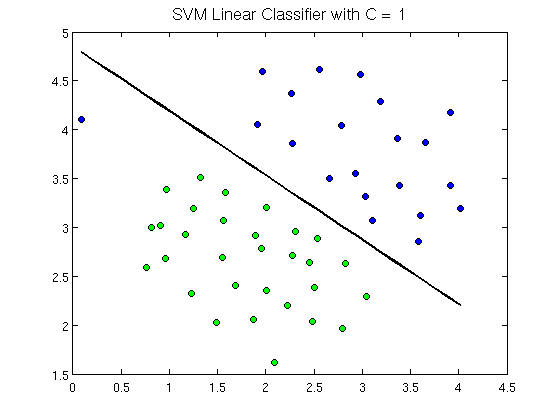
Linear decision surface: In a scatter plot graph, sets of data (classes) can be separated in difference decision surfaces by a decision boundary. If this decision boundary is a straight line, it is called a Linear Decision Surface.
Example:
- Gradient descent: Optimization algorithm to find the values of parameters of a function that minimizes a cost function. (see: cost function)
Example:
A random position on the surface of the bowl is the cost of the current value of the coefficients.
The bottom of the bowl is the cost of the best set of coefficitents, the mininum of the function.
The goal is to continue to try different values for the coefficients, evaluate their cost and select the new coefficients that have a better (lower) cost.
Repeating this process enough times will lead to the bottom of the bowl and you will know the values of the coefficients that result in a minimum cost.
-
Cost function: coming later
-
Differentiable plasticity: Neural networks are usually trained to a stopping point through gradient descent, which incrementally adjusts the connections of a network based on its perfomance over many trials. Once the training is complete, the network is fixed and the connections can no longer change; barring any later re-training. The network stops learning at the moment the training ends. Biological brains, however, have plasticity, the ability for connections between neurons to change continually and automatically throughout life. Differentiable plasticity is a method that lets us train the behavior of plastic connections through gradient descent.
-
If using very large data sets, Naive Bayes is better than SVM.