- 목차
- 운영 체에의 역할
- 시분활 시스템 멀티 태스킹
- CPU Protection Rings
- 멀티 프로그래밍
- 스케쥴러 알고리즘
- 프로세스 상태
- 인터럽트
- 컨텍스트 스위칭
- 프로세스간 커뮤니케이션
- 쓰레드
- 가상 메모리
- 페이징 시스템
- 파일 시스템
- 부팅의 이해
- Operating System 또는 OS 라고 부릅니다.
- 시스템 자원(System Resource) = 컴퓨터 하드웨어
- CPU(중앙처리장치), Memory(DRAM, RAM)
- I/O Devices (입출력 장치)
- Moinitor, Mouse, Keyboard, Network
- 저장 매체 : SSD, HDD (하드디스크)
컴퓨터 하드웨어는 스스로 할 수 있는 것이 없습니다.
- CPU: 각 프로그램이 얼마나 CPU를 사용할지를 CPU가 결정 할 수 없습니다.
- Memory: 각 프로그램어 어느주소에 저장을 하는지, 어느 정도 메모리 공간을 확보해줘야 하는지를 결정 할 수 없습니다.
- 저장매체(HDD, SDD): 어떻게, 어디에 저장할지 결정할 수 없습니다.
- 키보드/마우스 : 스스로 표시 할 수 없습니다
이 모든 것들을 운영체제가 진행합니다.
- 프로그램 = 소프트웨어
- 소프트웨어 = 운영체제, 응용 프로그램
- 응용 프로그램이 CPU를 사용하는 시간을 잘개 쪼개서, 여러 개의 응용 프로그램이 동시에 실행사는 기법
- 시분할 시스템 : 다중 사용자를 지원하고, 컴퓨터 응답 시간을 최소하하는 시스템
- 멀티 태스킹
- 가능한 CPU를 많이 활용하도록 하는 기능(시간대비 CPU사용율을 높이자)
- 단일 CPU에서, 여러 응용 프로그램의 병렬 실행을 가능케 하는 시스템
- 멀티 프로그래밍 : 최대한 CPU를 많이 활용 하도록 하는 시스템(시간대비, CPU 활용도를 높이자)
- I/O 작업이 일어나면 CPU가 대기 상태로 넘어가는 것을 비동기 방식으로 CPU를 다른 작업을 진행 할 수 있게 진행
- CPU도 권한 모드라는 것을 가지고 있습니다.
- 사용자 모드
- 커널 모드 : 특권 명령어 실행과 원하는 작업 수행을 위한 자원 접근을 가능케 하는 모드
- 커널 모드에서만 실행 가능한 기능들이 있음
- 커널 모드로 실행 하려면, 반드시 시스템 콜(커널모드)을 해야함
- 시스템 콜은 운영체제 제공
- 함부로 응용 프로그램이 전체 컴퓨터 시스템을 헤치지 못함
- 운영체제는 시스템 콜을 제공
- 프로그래밍 언어 별로 운영체제 기능을 활요하기 위해, 시스템 콜을 기반으로 API 제공
- 응용 프로그램은 운영체제 기능 필요시, 해당 API를 사용해서 프로그램을 작성
- 응용 프로그램이 실행되서, 운영체제 기능이 필요한 API를 호출하면, 시스템 콜이 호출되서, 다시 커널 모드 변경되어 OS 내부에 해당 명령이 실행되고, 다시 응용 프로그램으로 돌아간다.
- 최대한 CPU를 많이 활용하도록 하는 시스템
- 시간 대비 CPU 활용도를 높이자
- 응용 프로그램 짧은 시간안에 실행 완료를 시킬 수 있음
- 응용 프로그램은 온전히 CPU를 쓰기보다, 다른 작업을 중간에 필요로 하는 경우가 많음
- 응용 프로그램이 실행되다가 파일을 읽는다.
- I/O 작업이 일어나면 시스템이 Blocking 된다
- 응용 프로그램이 실행되다가 프린팅을 한다.
- 마찬 가지로 I/O 작업이 일어나면 Blocking 된다
- 응용 프로그램이 실행되다가 파일을 읽는다.
- 시분할 시스템 : 다중 사용자 지원, 컴퓨터 응답시간을 최소화 하는 시스템
- 멀티 캐스팅: 단일 CPU에서 여러 응용 프로그램을 동시에 실행하는 것처럼 보이게 하는 시스템
- 멀티 프로세싱 : 여러 CPU에 하나의 응용 프로그램을 병렬로 실행하게 해서, 실행속도를 높이는 기법
- 멀티 프로그래밍 : 최대한 CPU를 일정 시간당 많이 활용하는 시스템
이미지 출처 [OS] 프로세스와 스레드의 차이
- 실행 중인 프로그램은 프로세스라고 함
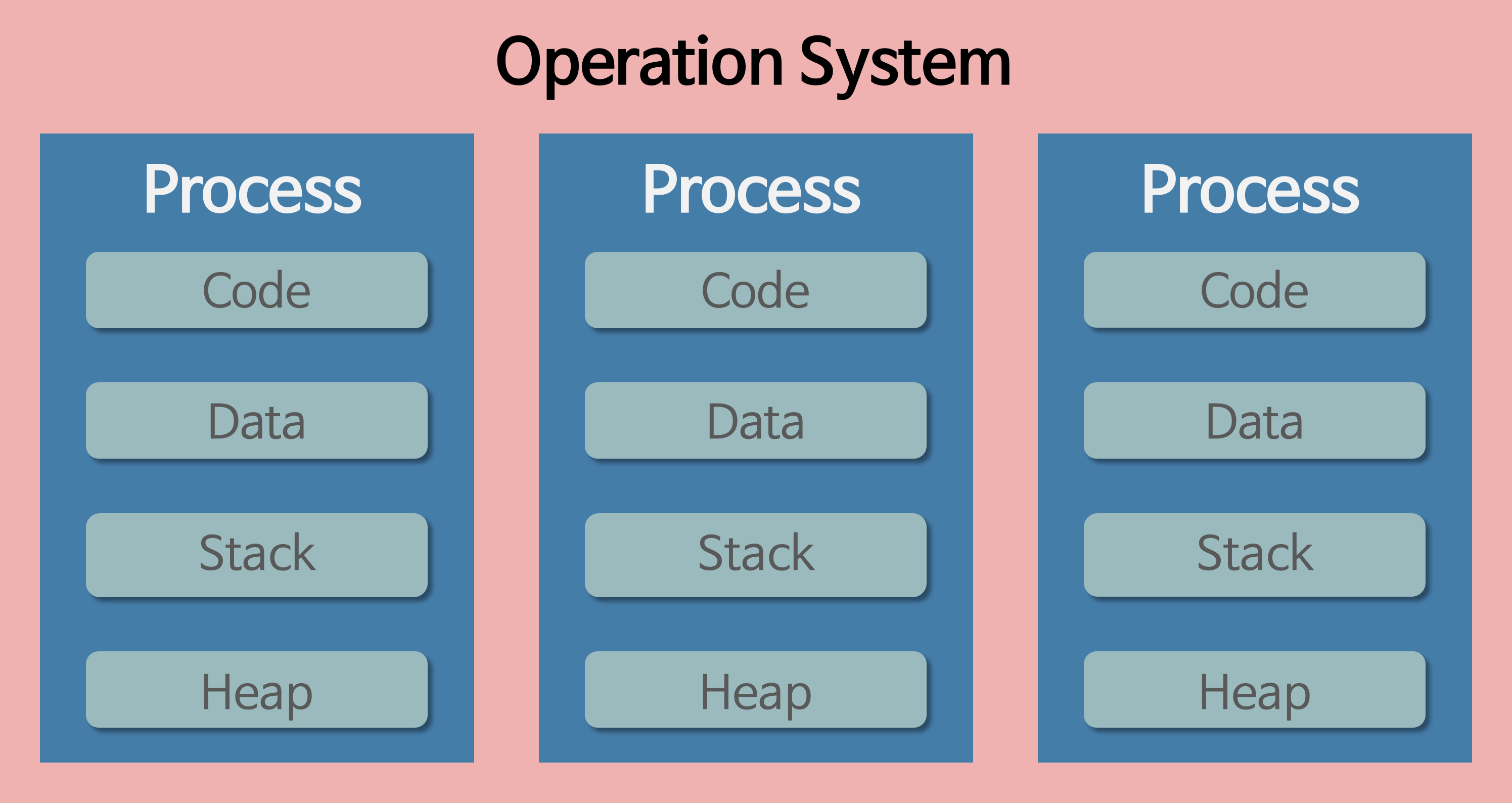
- 프로세스 : 메모리에 올려져서, 실행 중인 프로그램
- 코드 이미지(바이너리): 실행 파일, 예
- 메모리에 올라와 실행되고 있는 프로그램의 인스턴스(독립적인 개체 위 이미지 처럼 각각의 프로세스는 Code, Data, Stack, Heap 영역으로 독립적 이다)
- 프로세스는 각각 독립된 메모리 영역을 할당 받는다 (Code, Data, Stack, Heap)
- 기본적으로 프로세스당 최소 1개의 스레드(메인 스레드)를 가지고있다.
- 각 프로세스는 별도의 주소 공간에 실행되며, 한 프로세스는 다른 프로세스의 변수나 자료구조에 접근할 수 없다.
- 프로세스 간의 자원을 공유를 하기 위해서는 IPC(InterProcess Communication) 기법을 이용해야한다.
- 프로세스 실행을 관리하는 것이 스케쥴러
- 목표
- 시분할 시스템 예: 프로세스 응답 시간을 가능한 짧게
- 멀티 프로그래밍 예: CPU 활용도를 최대로 높혀서, 프로세스를 빨리 실행
- SJF 스케쥴러
- 가장 프로세스 실행 시간이 짧은 프로세스 부터 먼저 실행 시키는 알고리즘
- priority-based 스케쥴러
- 정적 우선순위
- 프로세스마다 우선순위를 미리 지정
- 동적 우선순위 : 스케쥴러가 상황에 따라 우선순위를 동적으로 변경
- 큐에 쌓아 놓고 일정 시간이 지나면 다시 대기 큐로 돌려 보낸다. 그 뒤에 있는 작업을 진행한다.
- FIFO 스케쥴링 알고리즘 : 배치 시스템
- 최단 작업 우선 스케쥴링 알고리즘
- 우선순위 기반 스케쥴링 알고리즘
- 정적 순위, 동적 우선 순위
- Round Robin 스케쥴링 알고리즘
- 시분할 시스템 기반

- running state: 현재 CPU에서 실행 상태
- ready state: CPU에서 실행 가능 상태 (실행 대기 상태)
- block state: 특정 이벤트 발생 대기 상태

- Process blocks for input : 특정 이벤트 대기
- Scheduler picks another process
- Scheduler picks this process
- Process Becomes avaliable
CPU가 프로그램을 실행하고 있을때, 입출력 하드웨어 등 의 장치(이벤트 발생)나 또는 예외상횡이 발생하여 처리가 필요한 경우 CPU에 알려준 처리 기술
어느 한순간 CPU가 실행하는 명령은 단 하나, 다른 장치와 어떻게 커뮤니케이션을 할까요?
- 선점형 알고리즘
- 프로그램이 실행중에 어떠한 이유(Blocking 되는 작업 등)로 중간에 멈춰야 할때
- 예외 상황 핸들링
- CPU가 프로그램을 실행하고 있을 때, 입출력 하드웨어 등의 장치나 또는 예외상황이 발생할 경우, CPU가 해당 처리를 할 수 있도록 CPU에 알려줘야함
- 내부 인터럽트
- 주로 소프트웨어 인터럽트라고 함
- 주로 프로그램 내부에서 잘못된 명령 또는 잘못된 데이터 사용시 발생
- 0 으로 나눴을 때
- 사용자 모드에서 허용되지 않은 명령 또는 공간 접근시
- 계산 결과가 Overflow/Underflow 날 때
- 외부 인터럽트
- 주로 하드웨어 인터럽트라고 함
- 주로 하드웨어 발생되는 이벤트 (프로그램 외부)
- 전원 이상
- 기계문제
- 키보드등 IO 관련 이벤트
- Timer 이벤트
- 인터럽트는 미리 정의되어 각 번호와 실행코드를 가리키는 주소가 기록되어 있음
- IDT(Interrupt Descriptor Table)에 기록
- 컴퓨터 부팅시 운엥체제가 기록
- 리눅스 경우
- 0 ~ 31 : 예외상황 인터럽트 (내부 인터럽트, 소프트웨어 인터럽트)
- 32 ~ 37: 하드웨어 인터럽트 주변 장치 (외부 인터럽트)
- 128 : 시스템콜
- 프로세스 구조
- Stack, Heap, Data(BSS, DATA), Code
- PCG
- 프로세스 정보 상티
- PC, SP : 컨텍스트 스위칭
- 메모리
- 스케쥴링
- 프로세스 정보 상티
- Context Switching(문맥 교환)
- CPU에 실행할 프로세스를 교체하는 기술
- 실행 중지할 프로세스 정보를 해당 프로세스의 PCB에 업데이트해서, 메인 메모리에 저장
- 다음 실행할 프로세스 정보를 메인 메모리에 있는 해당 PCB 정보를 CPU에 넣고 실행

- 실행 중지할 프로세스 정보를 해당 프로세스의 PCB에 업데이트해서, 메인 메모리에 저장
- 다음 실행할 프로세스 정보를 메인 메모리에 있는 해당 PCB 정보(PC, SP)를 CPU의 레지스터리에 넣고 실행
- 프로세스는 다른 프로세스의 공간을 접근할 수 없다.
- 프로세스들이 서로의 공간을 쉽게 접근할 수 있다면 프로세스 데이터/코드가 바뀔수 있으니 위험하다.
- 프로세스간 통신이 필요한이유 ?
- 성능을 높이기 위해 여러 프로세르를 만들어 동시에 실행할 경우 이때 프로세스 간 상태 확인 및 데이터 송수신이 필요
- 프로세스간의 통신 방법을 제공함
- IPC: InterProcess Communication
- Message Queue
- Shared Memory
- Pipe
- Signal
- Semaphore
- Socket
- 기본 파이프는 단방향 통신
- fork()로 자식 프로세스 만들었을때, 부모와 자식간의 통신

- 부모 프로세스에서 fd[1]을 기반으로 데이터를 생성
- 자식 프로세스에서 fd[0]을 기반으로 데이터를 읽을 수 있음
- 단방향 통신이다
- 실제 데이터가 전달되는 pipe는 커널 영역에 존재한다.
- 큐 정책 그대로 FIFO 정책으로 데이터 전송
- 먼저 넣은 데이터가 먼저 읽혀진다.
- 메시지큐는 양방향이 가능
- mesage queue는 부모/자식이 아니라, 어느 프로세스간에더라도 데이터 송수신이 가능
- 먼저 넣은 데이터가

- 노골적으로 kernel space에 메모리 공간을 만들고, 해당 공간을 변수처럼 쓰는 방식
- message queue 처럼 FIFO 방식이 아니라. 해당 메모리 주소를 마치 변수처럼 접근하는 방식
- 공유 메모리 key를 가지고, 여러 프로세스가 접근 가능
- 커널 또는 프로세스에서 다른 프로세스에 어떤 이벤트가 발생되었는지를 알려주는 기법
- 시그널은 미리 정의된 이벤트이다.
- 서로 다른 프로세스들이 시그널 이벤트를 이용해서 프로세스간의 통신이 가능하다.
- 미리 정의된 시그널 중에서 아무 동작도 하지 않은 시그널을 통해서 시그널을 정의해서 사용 한다.
- 프로세스 관련 코드에 관련 시그널 핸들러를 등록해서, 해당 시그널 처리 실행
- 시그널 무시
- 시그널 블록(블록을 푸는 순간, 프로세스에 해당 시그널 전달)
- 등록된 시그널 핸들러로 특정 동작 수행
- 등록된 시그널 핸들러가 없다면, 커널에 기본 동작 수행
- 소켈은 네트워크 통신을 위한 기술
- 기본적으로는 클라이언트와 서버등 두 개의 다른 컴퓨터간의 네트워크 기반 통신을 위한 기술
- 소켓을 하나의 컴퓨터 안에서, 두 개의 프로세스 간에 통신 기법으로 사용 가능
- 여러 프로세스 동시 실행을 통한 성능 개선, 복잡한 프로그램을 위해 프로세스간 통신 필요
- 프로세스간 공간이 완전분리
- 프로세스간 통신을 위한 특별한 기법 IPC 지원
- 대부분의 IPC 기법은 커널 커널 공간을 활용
- 이유: 커널 공간은 프로세스간의 공유가 가능
이미지 출처 [OS] 프로세스와 스레드의 차이
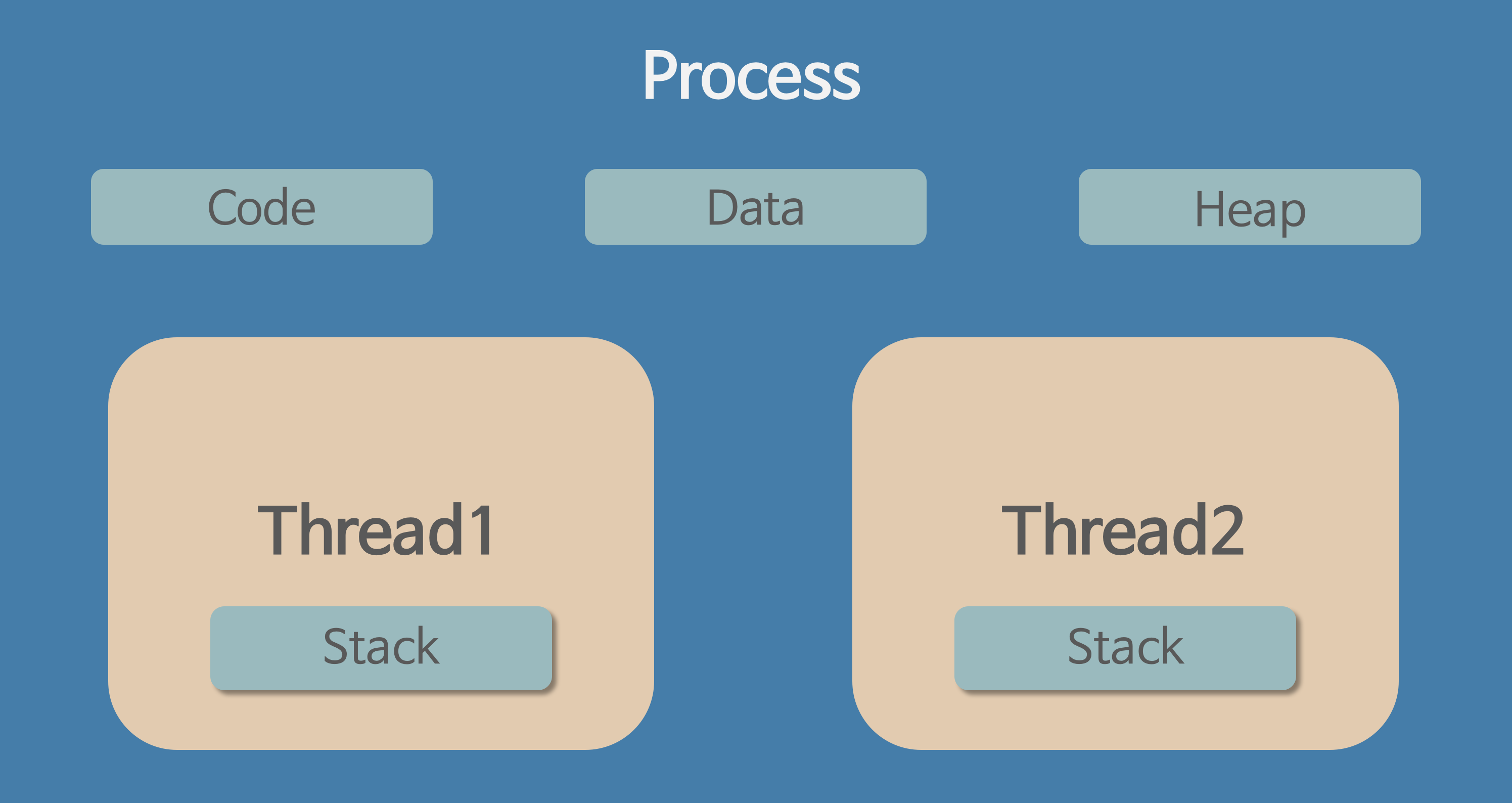
- 스레드는 프로세스 내에서 실행되는 여러 흐름의 단위 라고 할 수있음
- 프로세스가 할당받은 자원을 이용하는 실행의 단위
- 스레드는 프로세스 내에서 각각 Stack만 따로 할당받고 Code, Data, Heap 영역은 공유한다.
- 프로세스 간의 자원공유는 IPC를 사용해야 하지만 스레드는 Stack 영역을 제외하고 Code, Data, Heap 영역을 공유해서 사용하기 때문에 자원 공유의 이점을 갖는다.
- 스레드는 한 프로세스 내에서 동작되는 여려 실행의 프름으로, 프로세스 내의 주소 공간이나 자원들을 같은 프로세스 내에서 스레드끼리 공유하면서 실행된다.
- 같은 프로스세 안에 있는 여러 스레들을 같은 힙 공간을 유지한다. (프로세스 간의 데이터 공유는 IPC를 통해서만 가능하다)
- 한 스레드가 프로세스 자원을 변경하면, 다른 이웃 스레드(Siblind thread)도 그 결과를 즉시 볼 수 있다.
- 하나의 프로세스에 여러개의 스레드 생성 및 실행이 가능하다.
- 스레드를 Ligh Weigh Process 라고함
- 사용자에 대한 응답성 향상
- 자원 공유 효율
- IPC 기법과 같이 프로세스간 자원 공유를 위해 번거로운 작업이 필요 없음
- 프로세스 안에 있으므로, 프로세스의 데이터를 모두 접근 가능
- 작업이 분리되어 코드가 간결, 사실 작성하기 나름
- 스레드 중 한 스레드만 문제가 있어도, 전체 프로세스가 영향을 받음
- 스레드를 많이 생성하면, Context Switching이 많이 일어나, 성능 저하
- 리눅스에서는 Thread를 Process와 같이 다룸
- 스레드를 많이 생성하면, 모든 스레드를 스케쥴링해야 하므로, Context Switching이 빈번하게 발생할 수 있다.
- 프로세스는 독립적, 스레드는 프로세스의 서브넷
- 프로세스는 각각 독립적인 자원을 가짐, 스레드는 프로세스 자원 공유
- 프로세스는 자신만의 주소영역을 가짐, 스레드는 주소영역을 공유
- 프로세스간에는 IPC 기법으로 통신해야함, 스레드는 필요 없음
- 스레드간 전역 변수를 공유하다 보면 동기화 이슈가 발생한다.
- Mutual exclusion (상호 배제)
- 스레드는 프로세스의 모든 데이터를 접근할 수 있음
- 여러 스레드가 변경하는 공유 변수에 대해서는 Exclusive Access 필요
- 어느 한 스레드가 공유 변수를 갱신하는 동안 다른 스레드가 동시 접근하지 못하도록 막아야한다.
- Critical Section(임계 영역)에 대한 접근을 막기 위해 LOCKING 메커니즘이 필요
- Mutex(Binary Semaphore)
- 임계영역에 하나의 스레드만 들어 갈 수 있음
- Semaphore
- 임계영역에 여러 스레드가 들어 갈 수 있음
- counter를 두어 동시에 리소스에 접근 할 수 있는 허용 가능한 스레드 수를 제어
- Mutex(Binary Semaphore)
- P : 검사 (임계영역에 들어 갈 때)
- S값이 1 이상이면, 임계 영역 진입 후, S값 1차감 (S값이 0이면 대기)
- V : 증가 (임계영역에서 나올 때)
- S값을 1더하고, 임계영역을 나옴
- S : 세마포어 값(초기 값만큼 여러 프로세스가 동시 임계영역 접근 가능)
- 무한 대기 상태 : 두 개 이상의 작업이 서로 상대방의 작업이 끝나기 만을 기달리고 있기 때문에, 다음 단계로 진행하지 못하는 상태
다음 네 가지 조건이 모두 성립될 때, Deadlock이 발생 가능성이 있음 Deadlock이 발생하면 아래 조건중 하나만 해결하면 Deadlock이 해결된다.
- 상호배제 : 프로세스들이 필요로 하는 자원에 대해 배타적인 통제권을 요구한다
- 점유대기 : 프로세스가 할당된 자원을 가진 상태에서 다른 자원을 기다린다.
- 비선점 : 프로세스가 어떤 자원의 사용을 끝낼 때까지 그 자원을 뺏을 수 없다
- 순환대기 : 각 프로세스는 순환적으로 다음 프로세스가 요구하는 자원을 가지고 있다.
- 특정 프로세스의 우선순위가 낮아서 원하는 자원을 계속 할당 받지 못하는 상태
- 교착상태와 기아상태
- 교착상태와 기아상태
- 교착상태는 여러 프로세스가 동일 자원을 점유를 요청할 때 발생
- 기아상태는 여러 프로세스가 부족한 자원을 점유하기 위해 경졍할 때, 특정 프로세스는 영원히 자원 할당이 안되는 경우를 주로 의미함
- 교착상태와 기아상태
- 우선순위 변경
- 프로세스 우선순위를 수시로 변경해서, 각 프로세스가 높은 우선순위를 기회주기
- 오래 기다린 프로세스의 우선순위를 높여주기
- 우선순위가 아닌, 요청 순서대로 처리하기 FIFO 기반 요청큐 사용
실제 각 프로세스 마다 충분한 메모리를 할당하기에는 메모리 크기가 한계가 있음
- 리눅스는 하나의 프로세스가 4GB
- 통상 메모리는 8GB. 16GB
폰노이만 구조 기반이므로, 코드는 메모리에 반드시 있어야 함
- 가상 메모리: 메모리가 실제로 메모리보다 많아 보이게 하는 기술
- 실제 사용하는 메모리는 작다는 점에 착안해서 고안된 기술
- 프로세스간 공간 분리로, 프로레스 이슈가 전체 시스템에 영향을 주지 않을 수 있음
- 가상 메모리 기본 아이디어
- 프로세스는 가상 주소를 사용하고, 실제 해당 주소에 데이터를 읽고/쓸때만 물리 주소로 바꿔즈면 된다.
- 가상 주소: 프로레스가 참조하는 주소
- 물리 주소 : 실제 메모리 주소
- MMU (Memory Management Unit : 하드웨어 칩)
- CPU에 코드 실행시, 가상 주소 메모리 접근이 필요할 때, 해당 주소를 물리 주소 값으로 변환해주는 하드웨어 장치
- CPU는 가상 메모리를 다루고, 실제 해당 주소 접근시 MMU 하드웨어 장치를 통해 물리 메리로 접근
- 하드웨어 장치를 이용해야 주소 변환이 빠르기 때문에 별도의 장치를 둠
- 크키가 동일한 페이지로 가상 주소 공간과 이에 매칭하는 물리 주소 공간을 관리
- 하드웨어 지원이 필요
- 예 Intel x86 시스템(32)에서는 4KB, 2MB, 1GB 지원
- 리눅스에서는 4KB로 paging
- 페이지 번호를 기반으로 가상 주소/ 물리주소 매핑 정보를 기록 사용
- 가상 주소와 페이지 번호로 해당 데이터 또는 코드를 찾는다
- page table
- 물리 주소에 있는 페이지 번호와 해당 페이지 첫 물리 주소를 정보를 매핑한 표
- 가상주소 v = (p, d) 라면
- p: 페이지 번호
- d: 페이지 처음부터 얼마 떨어진 위치 인지
- paging system
- 해당 프로세스에서 특정 가상 주소 엑세스를 하려면
- 해당 프로세스의 page table에 해당 가상 주소가 포함된 page 번호가 있는지 확인
- page 번호가 있으면 이 page가 매핑된 첫 물리 주소를 알아내고
- p` + d 가 실제 물리 주소가 됨
- 해당 프로세스에서 특정 가상 주소 엑세스를 하려면
| 페이지 번호 | 가상 주소 | 물리주소 | vaild-invalid bit |
|---|---|---|---|
| page1 | 000000h | 0000h | v |
| page2 | 000005sh | 2000h | i |
| page3 | 000000hh | 1000h | i |
- CPU는 가상 주소 접근시 MMU 하드웨어 장치를 통해 물리 메모리 접근
- 프로세스 생성시, 페이징 테이블 정보 생성
- PCB등에서 해당 페이지 테이블 접근 가능하고, 관련된 정보를 물리 메모리에 적재
- 프로세스 구동시, 해당 페이지 테이블 base 주소가 별도 레지스터에 저장(CR3)
- CPU가 가상 주소 접근시, MMU가 페이지 테이블 base 주소를 접근해서, 물리 주소를 가져옴
- 3bit, 시스템에서 4KB 페이지를 위한 페이징 시스템
- 하위 12bit는 오프셋
- 상위 20bit가 페이징 번호 이므로, 2의 20승(1048576) 개의 페이지 정보가 필요함
- 페이징 정보를 단계를 나눠 생성
- 필요없는 페이지는 생성하지 않아 공간 절약
- 어떤 페이지가 실제 물리 메모리에 없을 때 일어나는 인터럽트
- 운영체제가 page fault가 일어나면, 해당 페이지를 물리 메모리에 올림

- CPU가 가상 주소를 요청
- MMU는 TLB에서 캐싱이 되있다면 메모리에서 바로 CPU에서 넘겨줌, 만약 없다면 CR3 레지스터리를 이용해서 페이지 테이블로 간다
- Valid, In-Valid bit를 확인하고
- Valid 하다면 해당 페이지의 데이터를 CPU에게 전달
- In-Valid 하다면 3번 수행
- 운영체제에게 Page fault interrupt가 발생
- 프로세스 저장 공간에 가져옴
- 가져온 데이터를 메모리에 적재시킴
- 적재된 메모리를 페이지 테이블에 올림
- CPU에게 다시 실행 시켜 가상 주소를 요청하면 MMU를 호출해서 가상 주소를 얻어 온다.
- 프로세스 모든 데이터를 메모리로 적재하지 않고, 실행 중 필요한 시점에서만 메모리로 적재함
- 선행 페이징의 반대 개념: 미리 프로세스 관련 모든 데이터를 메모리에 놀려놓고 실행하는 개념
- 더 이상 필요하지 않은 페이지 프레임은 다시 저장 매체에 저장 (페이지 교체 알고리즘 필요)
- LRU - 가장 오래전에 사용된 페이지를 교체
- LFU - 가장 적게 사용되는 페이지를 교체
- NUR - NRU와 마찬가지로 최근에 사용하지 않은 페이지부터 교체하는 기법
- 각 페이지마다 참조 비트(R), 수정 비트(M)을 둠(R, M)
- (0,0), (0,1), (1,0), (1,1) 순으로 페이지 교체 (READ, WRITE)
- 반복적으로 페이지 폴트가 발생해서, 과도하게 페이지 교체 작업이 일어나, 실제로 아무일도 하지 못하는 상황
- 가상 메모리를 서로 크기가 다른 논리적 단위인 세그먼트로 분할
- 페이징 기법에서는 가상 메모리를 같은 크키의 블록으로 분할
- 파일 스시템 : 운영체제가 저장매체에 파일을 쓰기 위한 자료구조 또는 알고리즘
- 동일한 시스템콜을 사용해서 다양한 파일 시스템 지원 가능토록 구현
- read/write 시스템 콜 호출시, 각 기기 및 파일 시스템에 따라 실질적인 처리를 담당하는 함수 구현
- 파일을 실제 어떯게 저장할지를 다를 수 있음
- 리눅스의 경우 ext4, NTFS, FAT32 파일 시스템 지원
- 파일 시스템 기본 구조
- 슈퍼 블록: 파일 시스템 정보 및 파티션 정보 포함
- 아이노드 블록: 파일 상세 정보
- 데이터 블록 : 실제 데이터
- 컴퓨터를 켜서 동작시키는 절차
- Boot 프로그램
- 운영체제 커널을 Storage에서 특정 주소의 물리 메모리로 복사하고 커널의 처음 실행 위치로 PC를 가져다 놓는 프로그램
- 컴퓨터 부팅시
- BIOS가 특정 Storage 읽어와 bootstrap loader를 메모리에 올리고 실행함
- bootstrap loader 프로그램이 있는 곳을 찾아서 실행 시킴