Cloud Drive Architecture
For normal computers, Google or Dropbox drive can be mounted as a network folder. The remote files are cached to local disks and synchronized with the cloud in the background. So it is very fast to read and write, and there are no repeated downloads.
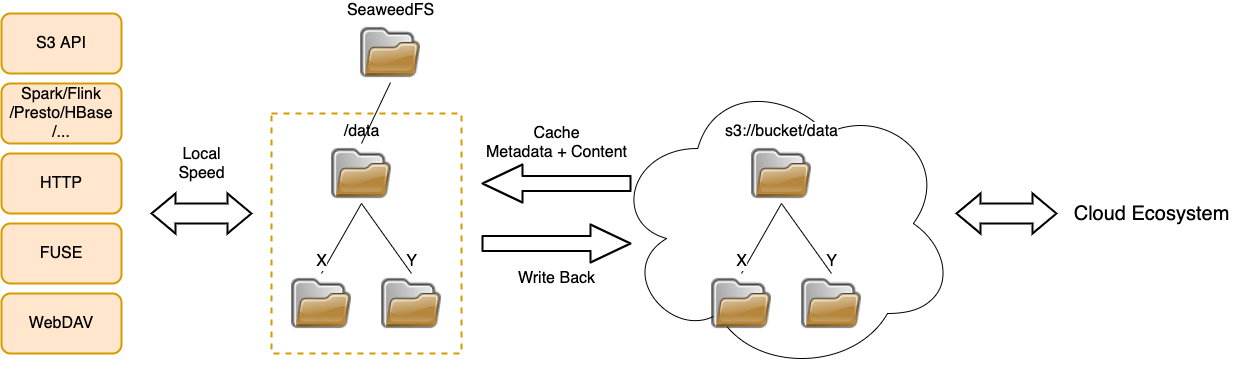
Similarly, SeaweedFS Cloud Drive can mount cloud storage to the local cluster. The cloud files can be cached to the local cluster and synchronized with the cloud in the background. So the read and write speed is of course very fast. Besides faster speed, the cost is also much lower. Since the existing cloud files are downloaded only once, the egress transfer cost to is minimized. And the local updates are uploaded for free. API accesses are also reduced to minimum.
So, faster and cheaper!
| SeaweedFS Cloud Drive | Google / Dropbox Drive | |
|---|---|---|
| Cache To | Local Cluster | Local Disk |
| Speed | Fast | Fast |
| Data Read | Download Once | Download Once |
| Data Write | Async Write Back | Async Write Back |
| Management | Selectively Cache/Uncache | N/A |
SeaweedFS Cloud Drive can also optionally cache or uncache specific files according to directory, file names, file size, file age, etc, to speed up access or reduce local storage cost.
With this feature, SeaweedFS can cache data that is on cloud. It can cache both metadata and file content. Given SeaweedFS unlimited scalability, the cache size is actually unlimited. Any local changes can be write back to the cloud asynchronously.
[HDFS|Mount|HTTP|S3|WebDAV] <== Filer / Volume Server <== `remote.mount` <== Cloud
(metadata/data cache) remote.meta.sync
remote.cache
remote.uncache
[HDFS|Mount|HTTP|S3|WebDAV] ==> Filer / Volume Server ==> `weed filer.remote.sync` ==> Cloud
(metadata/data cache)
There are no directory or file format changes to existing data on the cloud. So you do not need to change all existing workflows to read or write cloud files.
The remote storage, e.g., AWS S3, can be configured and mounted directly to an empty folder in SeaweedFS.
# in "weed shell"
> remote.configure -name=cloud1 -type=s3 -s3.access_key=xyz -s3.secret_key=yyy
> remote.mount -dir=/path/to/xxx -remote=cloud1/bucket
On mount, all the metadata will be pulled down and cached to the local filer store.
The metadata will be used for all metadata operations, such as listing, directory traversal, read file size, compare file modification time, etc, which will be free and fast as usual, without any API calls to the cloud.
To fetch metadata changes in the remote storage, just sync the whole mounted directory or any sub directories:
# in "weed shell"
> remote.meta.sync -dir=/path/to/xxx
> remote.meta.sync -dir=/path/to/xxx/sub/folder
The latest cloud metadata will be saved(except deletions). It is a light weight process and you can run it regularly.
By default, the file content is cached to local volume servers on the first read.
Sometimes you may want to fetch all file content for a set of files. But trying to warm up the cache by open and read all files is not fun.
Here you can run command remote.cache -dir=/path/to/xxx/cacheNeeded in weed shell, which will cache all files under the specified directory. You can also cache by file name, size, age, etc.
To purge local cache, you can run remote.uncache -dir=/path/to/xxx/cacheNeeded in weed shell.
Local changes are write back by the weed filer.remote.sync process, which is asynchronous and will not slow down any local operations.
If not starting weed filer.remote.sync, the data changes will not be propagated back to the cloud.