This repository contains the code for MENet (Merging-and-Evolution networks), a new family of compact networks which alleviate the loss of inter-group information in ShuffleNet.
The key idea of MENet is to utilize a merging operation and an evolution operation on the feature map generated from a group convolution for leveraging the inter-group information. The merging and evolution operations encode features across all channels into a narrow feature map, and combine it with the original network for better representation.
MENet is composed of ME modules, whose structure is illustrated in Figure 1.
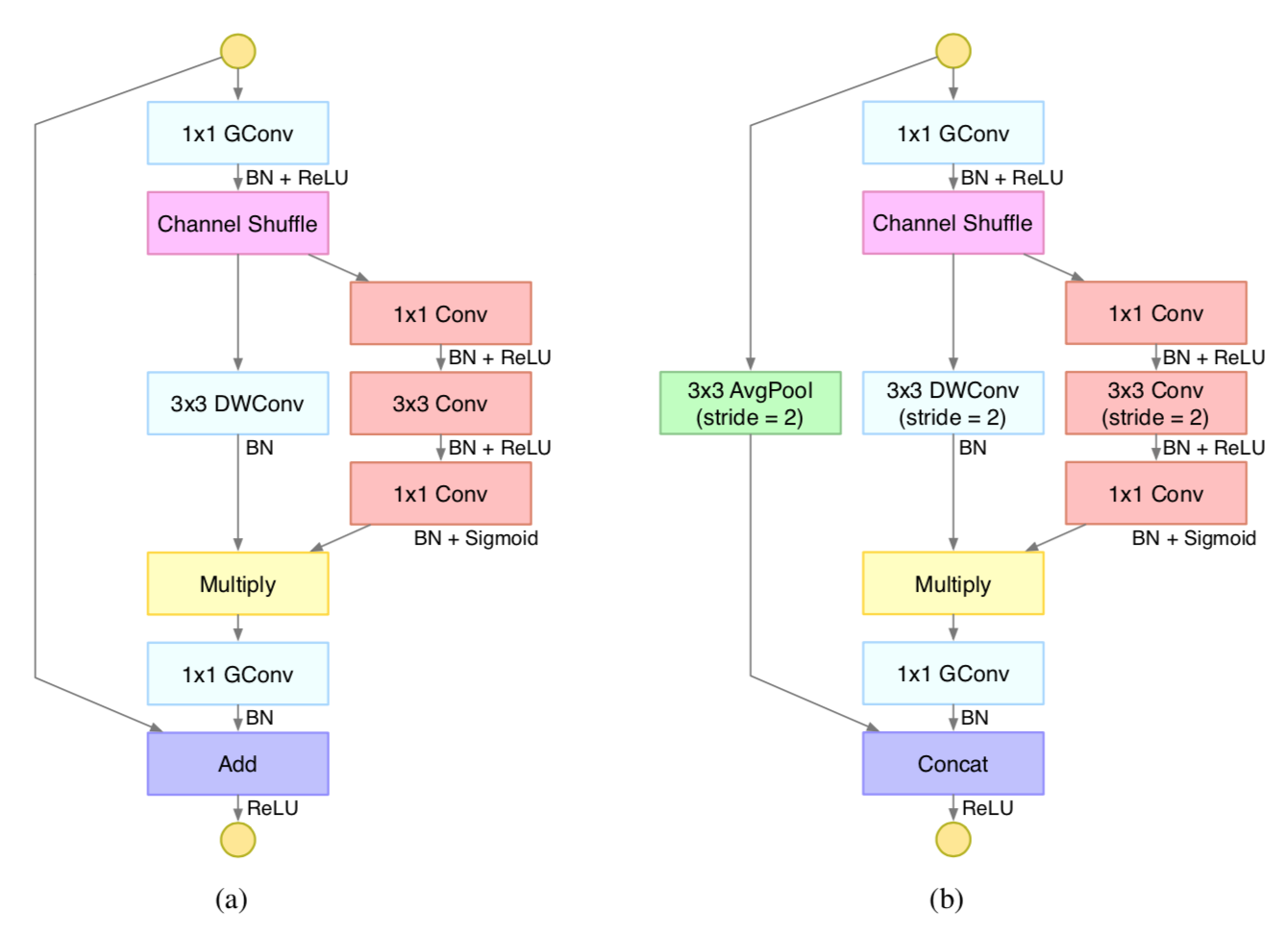 Figure 1. The structure of ME module. (a): Standard ME module. (b): Downsampling ME module. GConv: Group convolution. DWConv: Depthwise convolution.
Figure 1. The structure of ME module. (a): Standard ME module. (b): Downsampling ME module. GConv: Group convolution. DWConv: Depthwise convolution.
Our paper (arXiv) has been accepted as a conference paper by IJCNN 2018.
- pytorch >= 0.2.0, torchvision >= 0.2.0
- graphviz >= 0.8.0
Before starting, modify the data directory in config/imagenet/data-config/*.json to your data path.
To train a model:
python -u main.py \
--data /path/to/data/config \
--model /path/to/model/config \
--optim /path/to/optim/config \
--sched /path/to/sched/config \
--label model_label \
[--print-freq N] \
[--resume] \
[--evaluate]where model_label is the name of the checkpoint to be saved or resumed. For example:
python -u main.py \
--data config/imagenet/data-config/imagenet-aggressive.json \
--model config/imagenet/model-config/menet/228-MENet-12x1-group-3.json \
--optim config/imagenet/optim-config/SGD-120-nesterov.json \
--sched config/imagenet/sched-config/StepLR-30-0.1.json \
--label 228-MENet-12x1-group-3For simplicity, we train models and save checkpoints in multi-GPU models (using torch.nn.DataParallel), which means the keys in the state_dict saved have the prefix module.. To convert a multi-GPU model to single-GPU model, run convert_model.py:
python -u convert_model.py \
--data /path/to/data/config \
--model /path/to/model/config \
--label model_label \
--input /path/to/checkpoint/file \
--output /path/to/output/fileOur pre-trained models are single-GPU models (without prefix). To evaluate single-GPU models, run evaluate.py:
python -u evaluate.py \
--data /path/to/data/config \
--model /path/to/model/config \
--checkpoint /path/to/checkpoint/file \
[--print-freq N]main.py is modified from the pytorch example.
The models are trained on 4 Tesla K80 GPUs using SGD for 120 epochs. We use a batch size of 256 and Nesterov momentum of 0.9. The weight decay is set to 4e-5. The learning rate starts from 0.1, and decreases by a factor of 10 every 30 epochs.
| Model | MFLOPs | Top-1 Acc. (%) | Top-5 Acc. (%) |
|---|---|---|---|
| 108-MENet-8$\times$1 (g=3) | 38 | 56.08 | 79.24 |
| 228-MENet-12$\times$1 (g=3) | 144 | 66.43 | 86.72 |
| 256-MENet-12$\times$1 (g=4) | 140 | 66.59 | 86.74 |
| 352-MENet-12$\times$1 (g=8) | 144 | 66.69 | 86.92 |
| 348-MENet-12$\times$1 (g=3) | 299 | 69.91 | 89.08 |
| 456-MENet-24$\times$1 (g=3) | 551 | 71.60 | 90.07 |