V8 是 Google 发布的开源的高性能 JavaScript 和 WebAssembly 引擎,采用 C++ 编写。它被使用在 Chrome 浏览器,Node.js 等环境中。V8 可以独立运行,也可以嵌入在任何 C++ 应用中运行。
V8 引擎内部有许多小的模块组成。这里我们只需要了解其中最常用的四个模块即可。
- Parser(解析器)
- Ignition(解释器)
- TurboFan(编译器)
- Orinoco(垃圾回收)
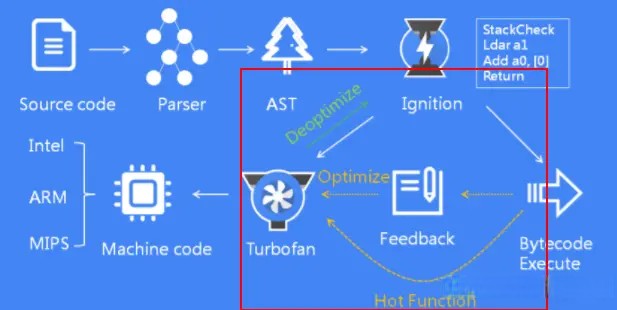
下图展示了 V8 引擎工作的基本流程:
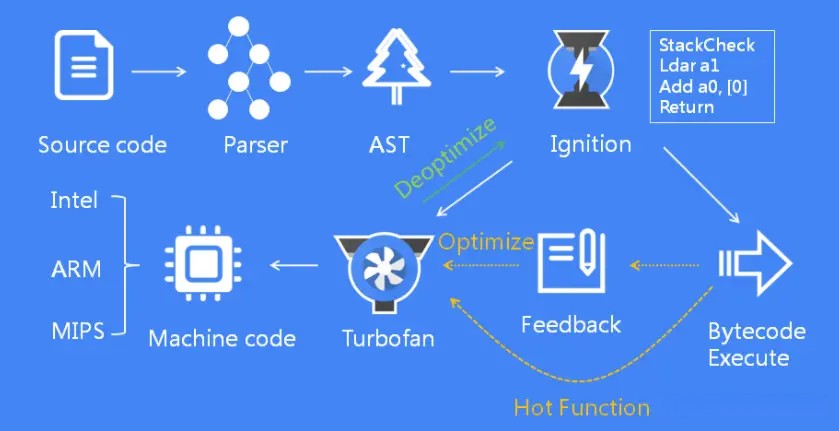
- 首先 V8 引擎会扫描所有的源代码,进行词法分析,生成 Tokens;
- Parser 解析器根据 Tokens 生成 AST;
- Ignition 解释器将 AST 转换为字节码,并解释执行;
- TurboFan 编译器负责将热点函数优化编译为机器指令执行;
什么是词法分析?
词法分析(Tokenizing/Lexing)其作用是将一行行的源码拆解成一个个 token。所谓词法单元 token,指的是语法上不可能再分的、最小的单个字符或字符串。
ECMAScript 中明确定义了 Token 包含的内容。
-
IdentifierName
-
Punctuator
-
NunericLiteral
-
StringLiteral
-
Template
我们来看下var a = 2; 这句代码经过词法分析后会被分解出哪些 tokens ?
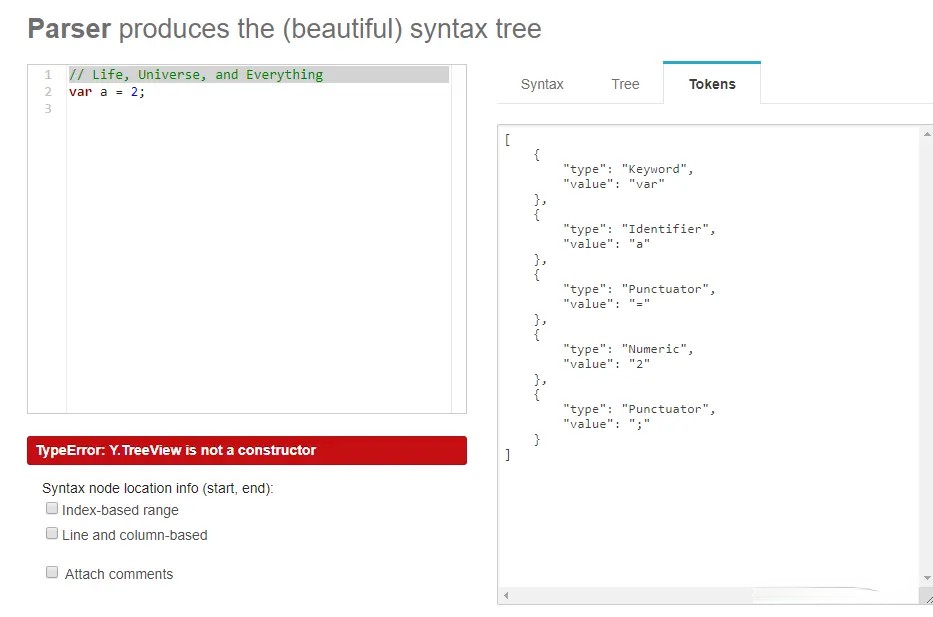
从上图中可以看到,这句代码最终被分解出了五个词法单元:
var关键字a标识符=运算符(符号)2数值;分号(符号)
Tokens 在线查看网站:esprima.org/demo/parse.…
Parser 是 V8 的解析器,负责根据生成的 Tokens 进行语法分析。Parser 的主要工作包括:
-
分析语法错误:遇到错误的语法会抛出异常;
-
输出 AST:将词法分析输出的词法单元流(数组)转换为一个由元素逐级嵌套所组成的代表了程序语法结构的树——抽象语法树(Abstract Syntax Tree, AST);
-
确定词法作用域;
-
生成执行上下文;
什么是抽象语法树(Abstract Syntax Tree, AST)?
还是上面的例子,我们来看下 var a = 2; 经过语法分析后生成的 AST 是什么样子的:
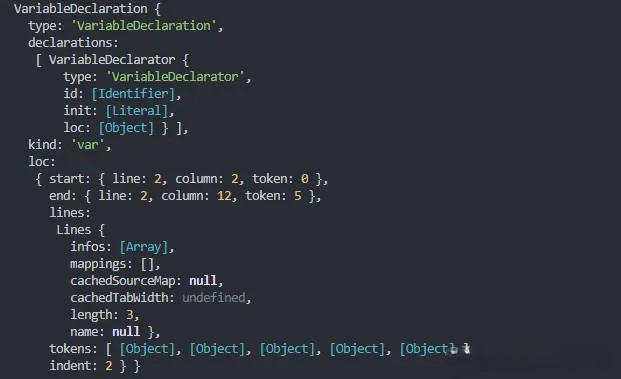
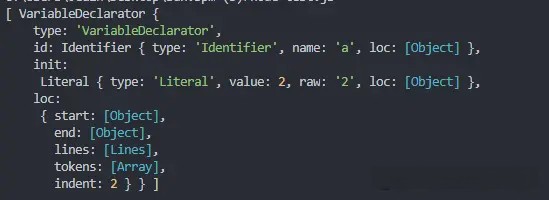
可以看到这段程序的类型是 VariableDeclaration,也就是说这段代码是用来声明变量的。
AST 在线查看网站:astexplorer.net/
AST 的结构和代码的结构非常相似,其实你也可以把 AST 看成代码的结构化表示,编译器或者解释器后续的工作都需要依赖于 AST,而不是源代码。
AST 是非常重要的一种数据结构,在很多项目中有着广泛的应用。其中最著名的一个项目就是 Babel。Babel 是一个被广泛使用的代码转码器,可以将 ES6 代码转为 ES5 代码,这意味着你可以现在就用 ES6 编写程序,而不用担心现有环境是否支持 ES6。Babel 的工作原理就是先将 ES6 源码转换为 AST,然后再将 ES6 语法的 AST 转换为 ES5 语法的 AST,最后利用 ES5 的 AST 生成 JavaScript 源代码。 除了 Babel 外,还有 ESLint 也使用 AST。ESLint 是一个用来检查 JavaScript 编写规范的插件,其检测流程也是需要将源码转换为 AST,然后再利用 AST 来检查代码规范化的问题。
什么是预解析 Pre-Parser?
我们先来看看下面这段代码:
function foo () {
console.log('function foo')
}
function bar () {
console.log('function bar')
}
foo()上面这段代码中,如果使用 Parser 解析后,会生成 foo 函数 和 bar 函数的 AST。然而 bar 函数并没有被调用,所以生成 bar 函数的 AST 实际上是没有任何意义且浪费时间的。那么有没有办法解决呢?此时就用到了 Pre-Parser 技术。
在 V8 中有两个解析器用于解析 JavaScript 代码,分别是 Parser 和 Pre-Parser 。
- Parser 解析器又称为 full parser(全量解析) 或者 eager parser(饥饿解析)。它会解析所有立即执行的代码,包括语法检查,生成 AST,以及确定词法作用域。
- Pre-Parser 又称为惰性解析,它只解析未被立即执行的代码(如函数),不生成 AST ,只确定作用域,以此来提高性能。当预解析后的代码开始执行时,才进行 Parser 解析。
我们还是以示例来说明:
function foo() {
console.log('a');
function inline() {
console.log('b')
}
}
(function bar() {
console.log('c')
})();
foo();- 当 V8 引擎遇到 foo 函数声明时,发现它未被立即执行,就会采用 Pre-Parser 对其进行解析(inline 函数同)。
- 当 V8 遇到
(function bar() {console.log(c)})()时,它会知道这是一个立即执行表达式(IIFE),会立即被执行,所以会使用 Parser 对其解析。 - 当 foo 函数被调用时,会使用 Parser 对 foo 函数进行解析,此时会对 inline 函数再进行一次预解析,也就是说 inline 函数被预解析了两次。如果嵌套层级较深,那么内层的函数会被预解析多次,所以在写代码时,尽可能避免嵌套多层函数,会影响性能。
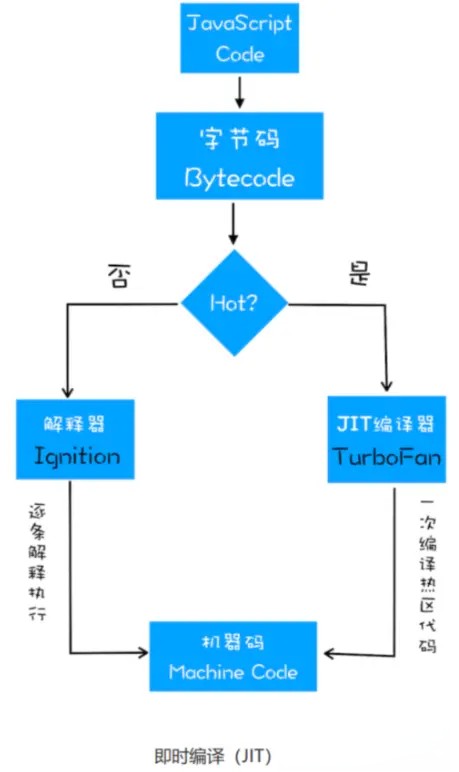
Ignition 是 V8 的解释器,它负责的工作包括:
- 将 AST 转换为中间代码(字节码 Bytecode)
- 逐行解释执行字节码:在该阶段,就已经可以开始执行 JavaScript 代码了。
什么是字节码?
字节码(Bytecode)是介于 AST 和机器码之间的一种中间码,它比机器码更抽象,也更轻量,需要直译器转译后才能成为机器码。
早期版本的 V8 ,并没有生成中间字节码的过程,而是直接将 AST 转换为机器码,由于执行机器码的效率是非常高效的,所以这种方式在发布后的一段时间内运行效果是非常好的。但是随着 Chrome 在手机上的广泛普及,特别是运行在 512M 内存的手机上,内存占用问题也暴露出来了,因为 V8 需要消耗大量的内存来存放转换后的机器码。为了解决内存占用问题,V8 团队大幅重构了引擎架构,引入字节码,并且抛弃了之前的编译器,最终花了将进四年的时间,实现了现在的这套架构。


从图中可以看出,机器码所占用的空间远远超过了字节码,所以使用字节码可以减少系统内存的占用。
TurboFan 是 V8 的优化编译器,负责将字节码和一些分析数据作为输入并生成优化的机器代码。
上面我们说到,当 Ignition 将 JavaScript 代码转换为字节码后,程序就可以执行了,那么 TurboFan 还有什么用呢?
我们再来看下 V8 的工作流程图:
我们主要关注 Ignition 和 TurboFan 的交互:
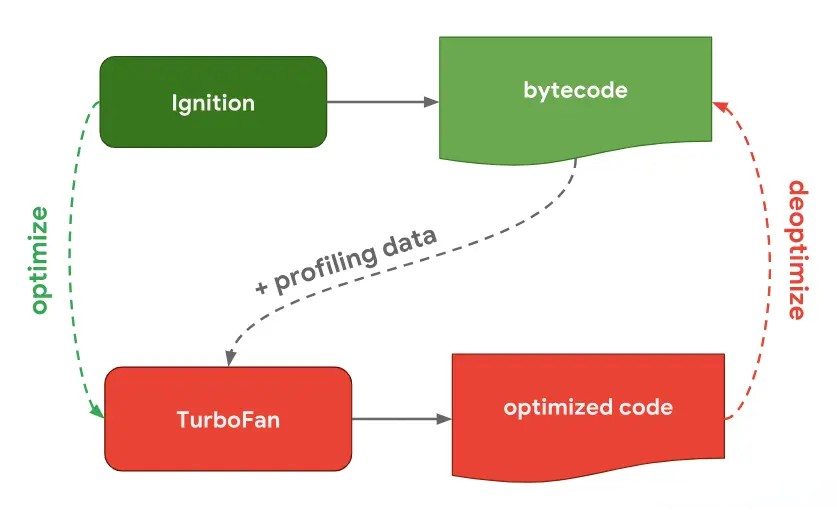
当 Ignition 开始执行 JavaScript 代码后,V8 会一直观察 JavaScript 代码的执行情况,并记录执行信息,如每个函数的执行次数、每次调用函数时,传递的参数类型等。
如果一个函数被调用的次数超过了内设的阈值,监视器就会将当前函数标记为热点函数(Hot Function),并将该函数的字节码以及执行的相关信息发送给 TurboFan。TurboFan 会根据执行信息做出一些进一步优化此代码的假设,在假设的基础上将字节码编译为优化的机器代码。如果假设成立,那么当下一次调用该函数时,就会执行优化编译后的机器代码,以提高代码的执行性能。
V8 的解释器和编译器的取名也很有意思。解释器 Ignition 是点火器的意思,编译 TurboFan 是涡轮增压的意思,寓意着代码启动时通过点火器慢慢发动,一旦启动,涡轮增压介入,其执行效率随着执行时间越来越高效率,因为热点代码都被编译器 TurboFan 转换了机器码,直接执行机器码就省去了字节码“翻译”为机器码的过程。我们把这种技术称为即时编译(JIT)
那如果假设不成立呢?不知道你们有没有注意到上图中有一条由 optimized code 指向 bytecode 的红色指向线。此过程叫做 deoptimize(优化回退),将优化编译后的机器代码还原为字节码。
读到这里,你可能有些疑惑:这个假设是什么假设呢?以及为什么要优化回退?我们来看下面的例子。
function sum (a, b) {
return a + b;
}我们都知道 JavaScript 是基于动态类型的,a 和 b 可以是任意类型数据,当执行 sum 函数时,Ignition 解释器会检查 a 和 b 的数据类型,并相应地执行加法或者连接字符串的操作。
如果 sum 函数被调用多次,每次执行时都要检查参数的数据类型是很浪费时间的。此时 TurboFan 就出场了。它会分析监视器收集的信息,如果以前每次调用 sum 函数时传递的参数类型都是数字,那么 TurboFan 就预设 sum 的参数类型是数字类型,然后将其编译为机器指令。
但是当某一次的调用传入的参数不再是数字时,表示 TurboFan 的假设是错误的,此时优化编译生成的机器代码就不能再使用了,于是就需要进行优化回退。
Orinoco 是 V8 的垃圾回收模块(garbage collector),负责将程序不再需要的内存空间回收(标记清除法);