Note: This project is replaced with https://github.com/coreos/etcdlabs

etcd-play is a playground for exploring the etcd distributed key-value database. Try it out live at play.etcd.io.
etcd uses the Raft consensus algorithm to replicate data on distributed machines in order to gracefully handle network partitions, node failures, and even leader failures. The etcd team extensively tests failure scenarios in the etcd functional test suite. Real-time results from this testing are available at the etcd test dashboard.
In Raft, followers are passive, only responding to incoming RPCs. Clients can make requests to any node, follower or leader. Followers, in turn, forward requests to their leader. Last, the leader appends those requests (commands) to its log and sends AppendEntries RPCs to all of its followers.
What if followers fail?
The leader retries RPCs until they succeed. As soon as a follower recovers, it will catch up with the leader.
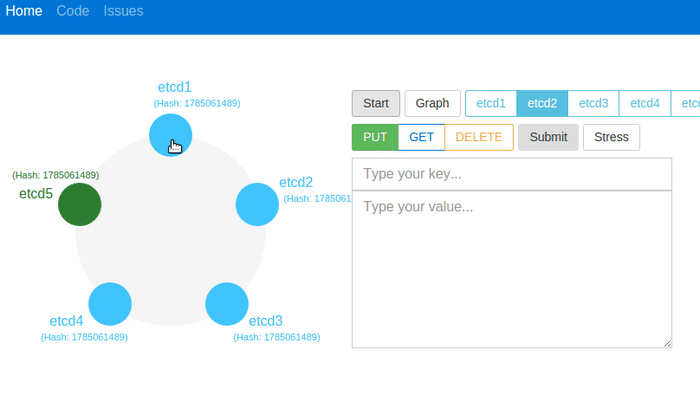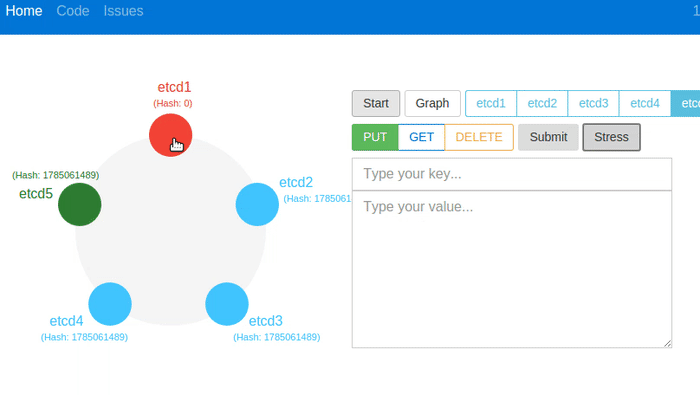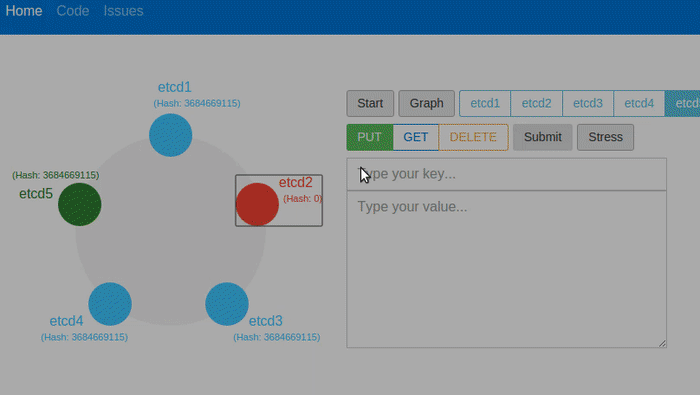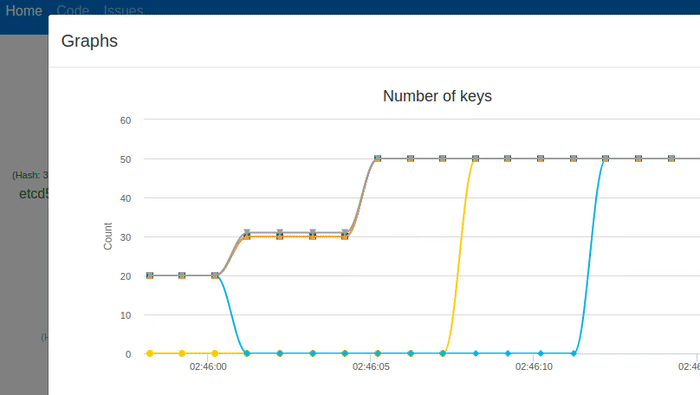
In the animation above, notice the stress on the remaining nodes while two of followers (etcd1 and etcd2) are down. Nevertheless, notice that all data is replicated across the cluster, except those two failed ones. Immediately after the nodes recover, the followers sync their data from the leader, looping on this process until all hashes match.
What if a leader fails?
A leader sends periodic heartbeat messages to its followers to maintain its authority. If a follower has not received heartbeats from a valid leader within the election timeout, it assumes that there is no current leader in the cluster, and becomes a candidate to start a new election. Each node includes its last term and last log index in its RequestVote RPC, so that Raft can choose the candidate that is most likely to contain all committed entries. When the old leader recovers, it will retry to commit log entries of its own. The Raft term is used to detect these stale leaders: Followers deny RPCs if the sender's term is older, and then the sender (often the old leader) reverts back to follower state and updates its term to the latest cluster term.
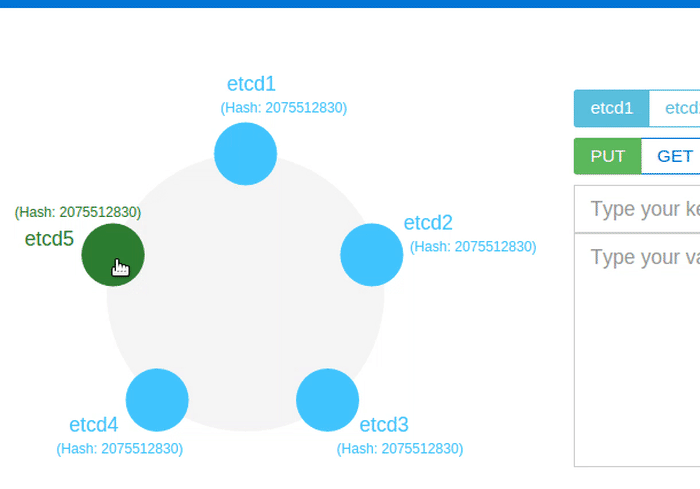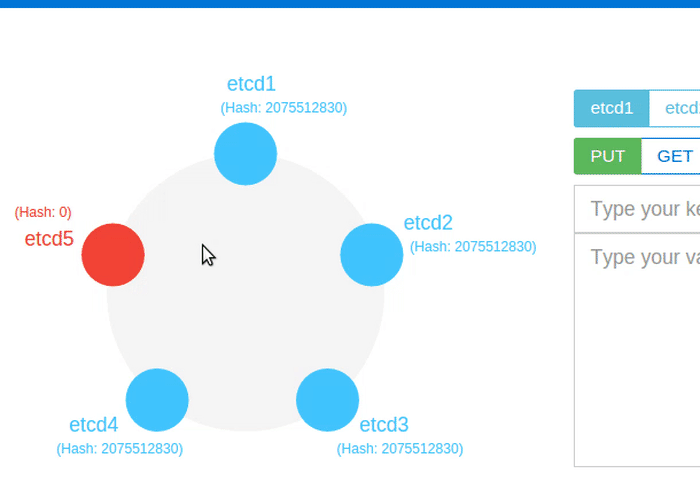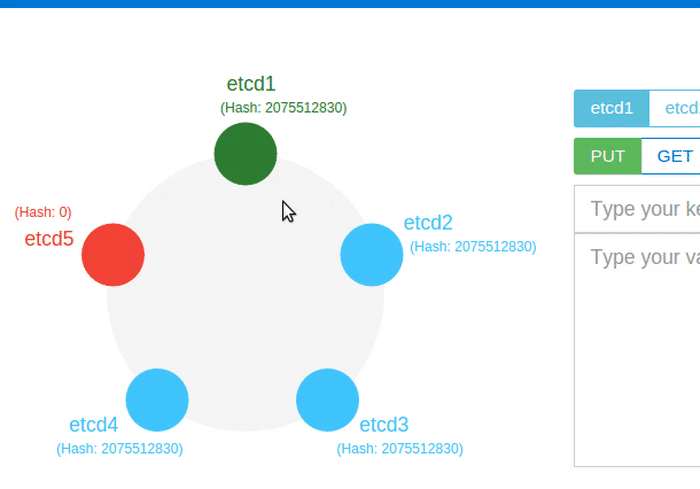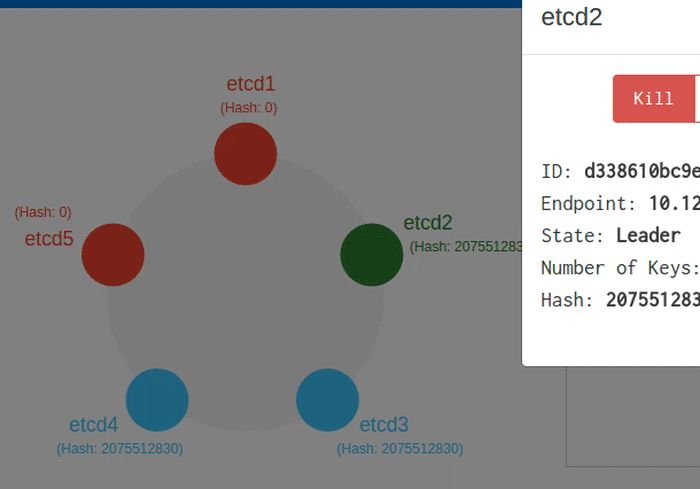
The animation above shows the Leader going down, and shortly a new leader is elected.
etcd is highly available as long as a quorum of cluster members are operational and can communicate with each other and with clients. 5-node clusters can tolerate failures of any two members. Data loss is still possible in catastrophic events, like all nodes failing. etcd persists enough information on stable storage so that members can recover safely from the disk and rejoin the cluster. In particular, etcd stores new log entries onto disk before committing them to the log to prevent committed entries from being lost on an unexpected restart.
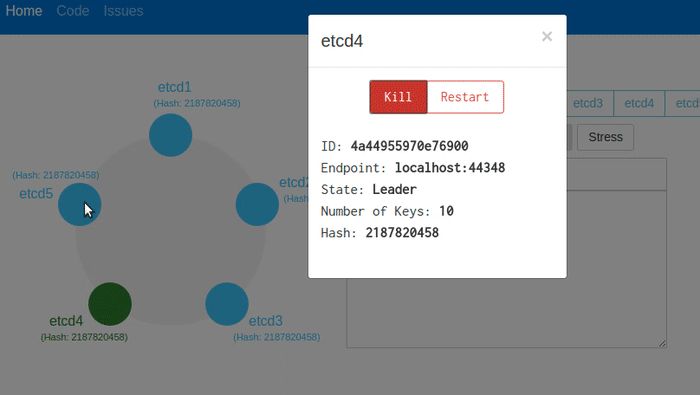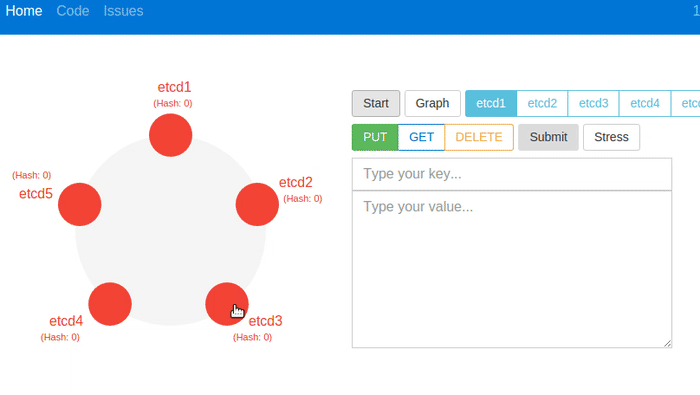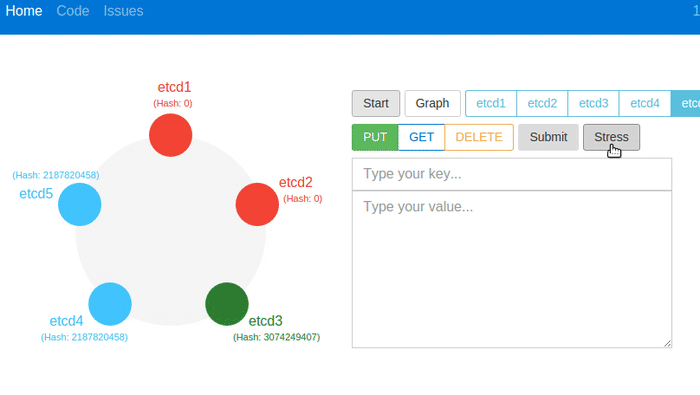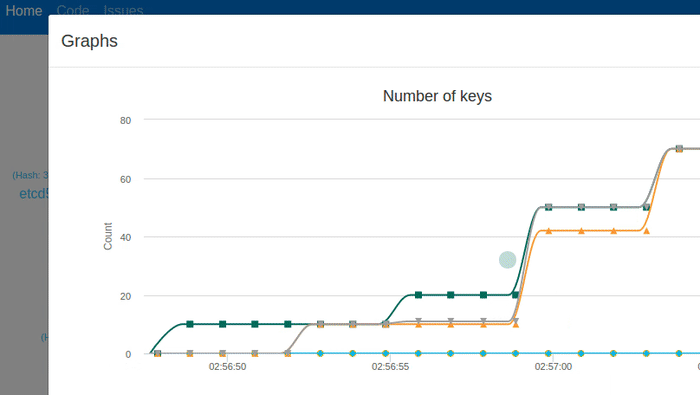
The animation above shows all nodes being terminated with the Kill button. etcd recovers the data from stable storage. You can see the number of keys and hash values match, before and after. The cluster can handle client requests immediately after recovery with a new leader.