
事情(事故)是这样的,突然收到报警,线上某个应用里业务逻辑没有执行,导致的结果是数据库里的某些数据没有更新。
虽然是前人写的代码,但作为 Bug maker&killer 只能咬着牙上了。
因为之前没有接触过出问题这块的逻辑,所以简单理了下如图:
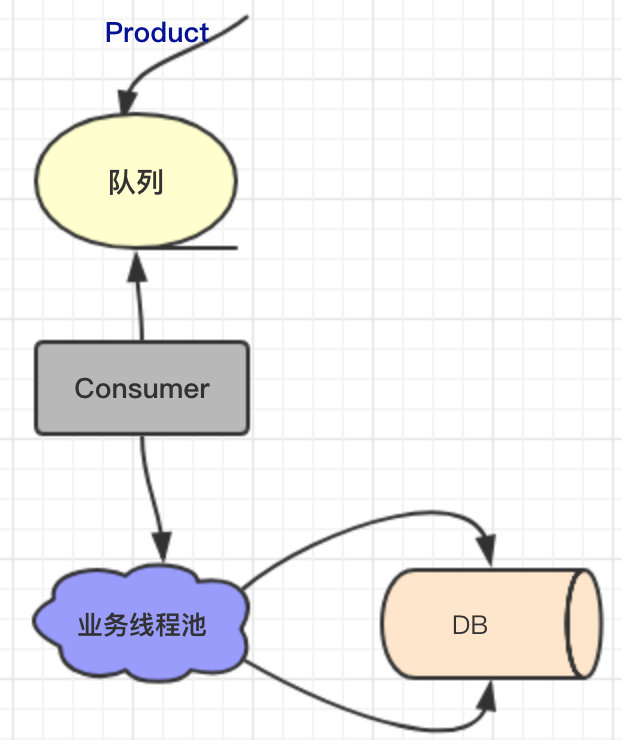
- 有一个生产线程一直源源不断的往队列写数据。
- 消费线程也一直不停的取出数据后写入后续的业务线程池。
- 业务线程池里的线程会对每个任务进行入库操作。
整个过程还是比较清晰的,就是一个典型的生产者消费者模型。
接下来便是尝试定位这个问题,首先例行检查了以下几项:
- 是否内存有内存溢出?
- 应用 GC 是否有异常?
通过日志以及监控发现以上两项都是正常的。
紧接着便 dump 了线程快照查看业务线程池中的线程都在干啥。
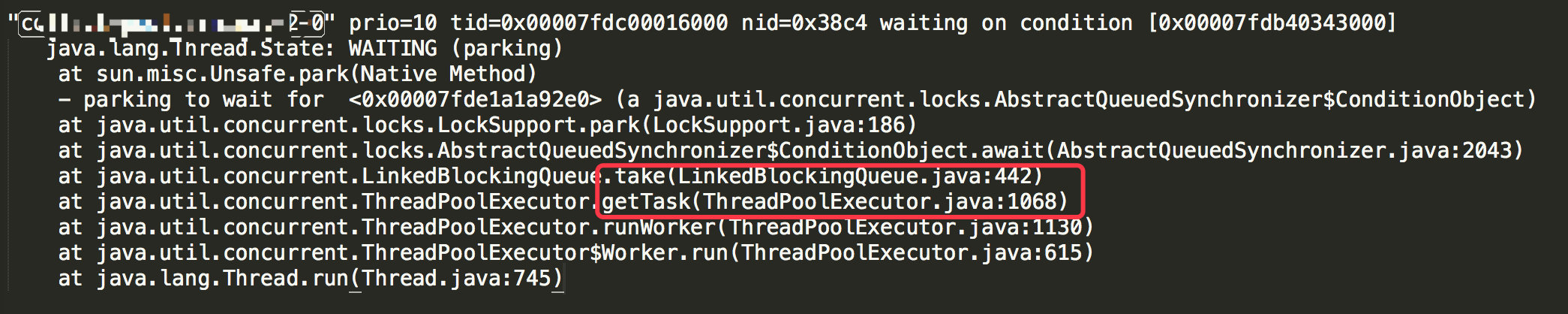
结果发现所有业务线程池都处于 waiting 状态,队列也是空的。
同时生产者使用的队列却已经满了,没有任何消费迹象。
结合上面的流程图不难发现应该是消费队列的 Consumer 出问题了,导致上游的队列不能消费,下有的业务线程池没事可做。
于是查看了消费代码的业务逻辑,同时也发现消费线程是一个单线程。

结合之前的线程快照,我发现这个消费线程也是处于 waiting 状态,和后面的业务线程池一模一样。
他做的事情基本上就是对消息解析,之后丢到后面的业务线程池中,没有发现什么特别的地方。
但是由于里面的分支特别多(switch case),看着有点头疼;所以我与写这个业务代码的同学沟通后他告诉我确实也只是入口处解析了一下数据,后续所有的业务逻辑都是丢到线程池中处理的,于是我便带着这个前提去排查了(埋下了伏笔)。
因为这里消费的队列其实是一个 disruptor 队列;它和我们常用的 BlockQueue 不太一样,不是由开发者自定义一个消费逻辑进行处理的;而是在初始化队列时直接丢一个线程池进去,它会在内部使用这个线程池进行消费,同时回调一个方法,在这个方法里我们写自己的消费逻辑。
所以对于开发者而言,这个消费逻辑其实是一个黑盒。
于是在我反复 review 了消费代码中的数据解析逻辑发现不太可能出现问题后,便开始疯狂怀疑是不是 disruptor 自身的问题导致这个消费线程罢工了。
再翻了一阵 disruptor 的源码后依旧没发现什么问题后我咨询对 disruptor 较熟的@咖啡拿铁,在他的帮助下在本地模拟出来和生产一样的情况。
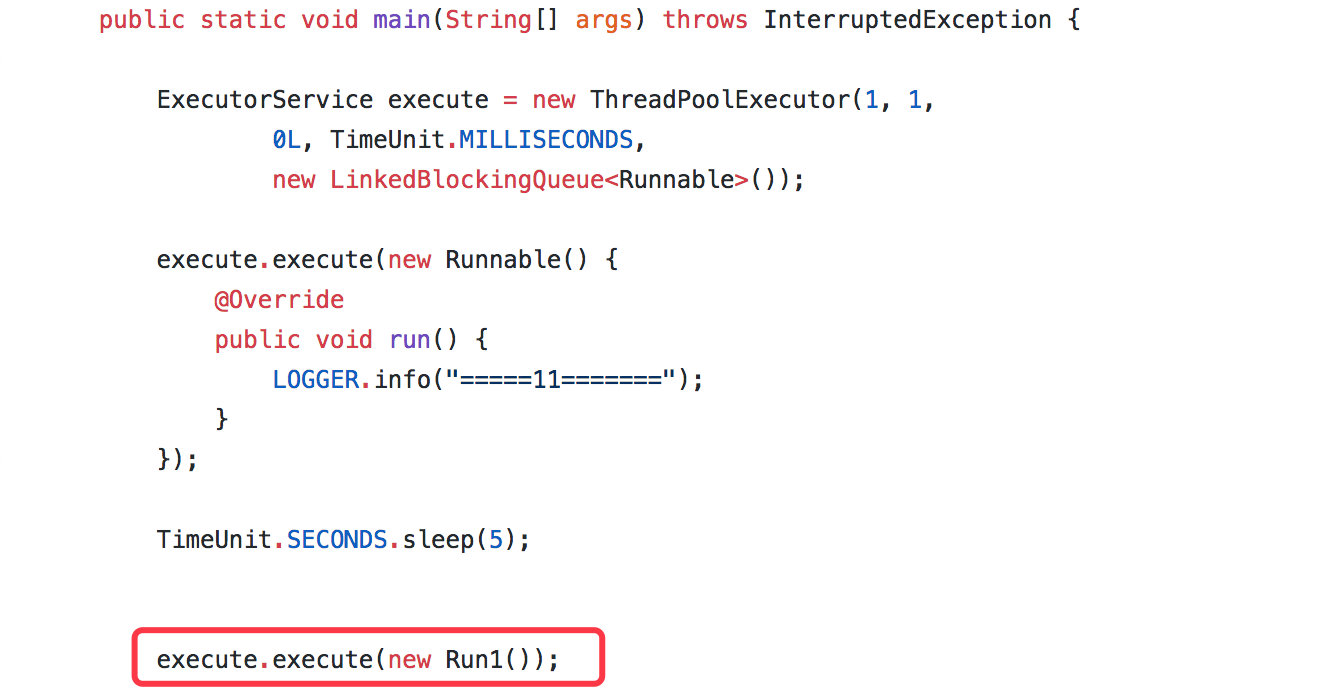
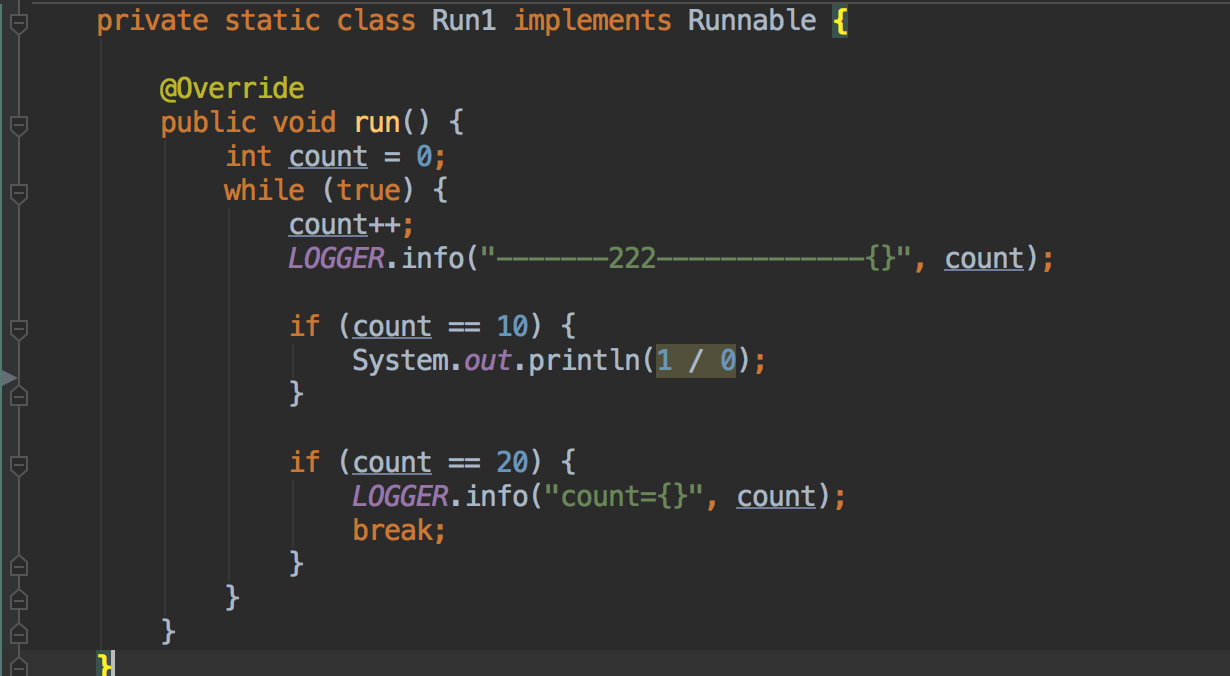
本地也是创建了一个单线程的线程池,分别执行了两个任务。
- 第一个任务没啥好说的,就是简单的打印。
- 第二个任务会对一个数进行累加,加到 10 之后就抛出一个未捕获的异常。
接着我们来运行一下。
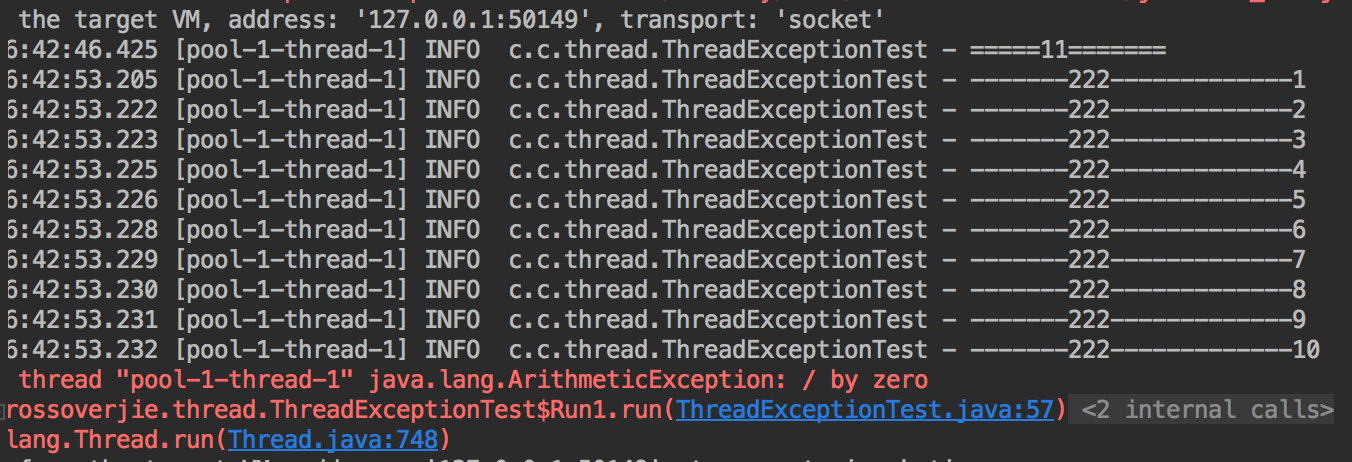

发现当任务中抛出一个没有捕获的异常时,线程池中的线程就会处于 waiting 状态,同时所有的堆栈都和生产相符。
细心的朋友会发现正常运行的线程名称和异常后处于 waiting 状态的线程名称是不一样的,这个后续分析。
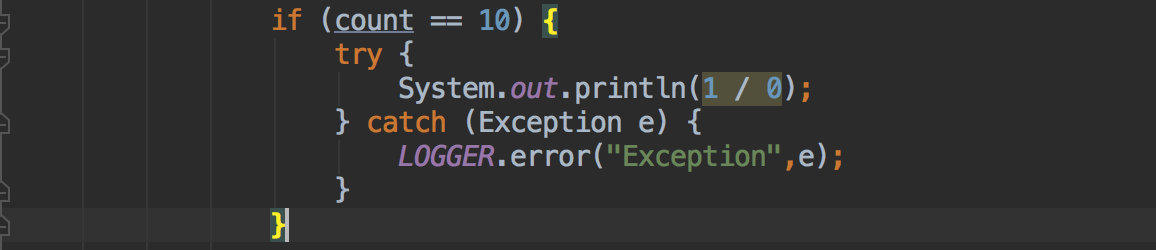
当加入异常捕获后又如何呢?
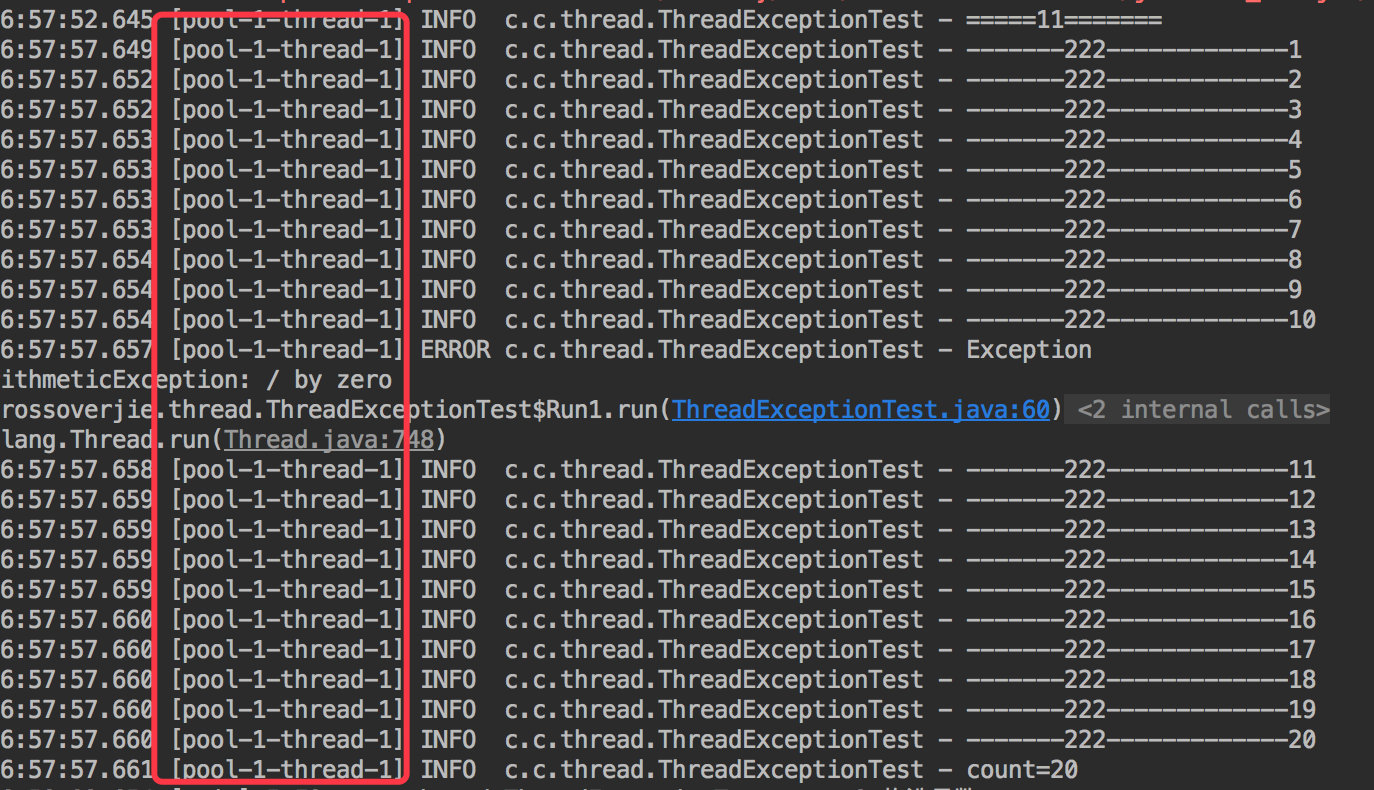
程序肯定会正常运行。
同时会发现所有的任务都是由一个线程完成的。
虽说就是加了一行代码,但我们还是要搞清楚这里面的门门道道。
于是只有直接 debug 线程池的源码最快了;

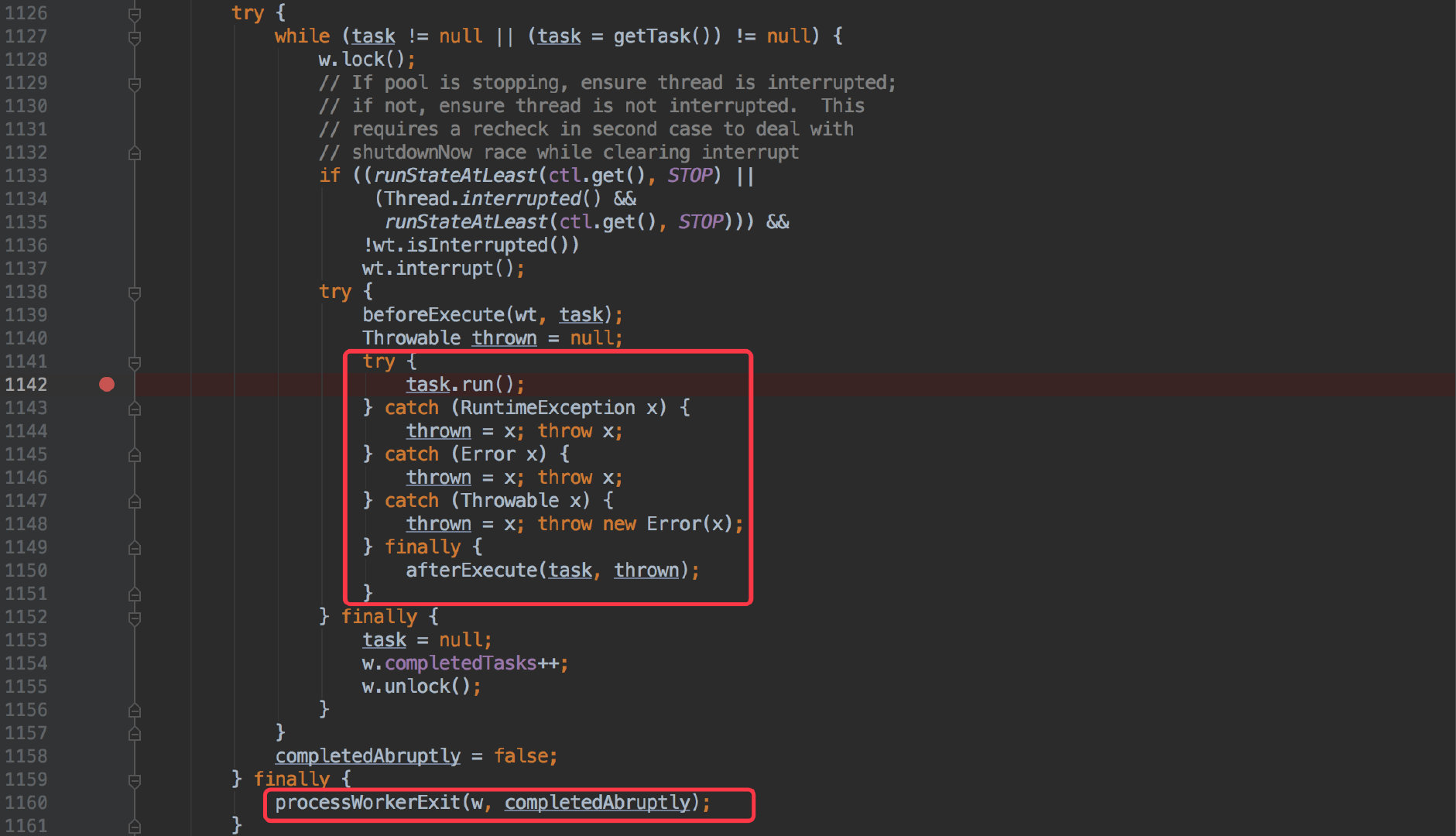
通过刚才的异常堆栈我们进入到 ThreadPoolExecutor.java:1142 处。
- 发现线程池已经帮我们做了异常捕获,但依然会往上抛。
- 在
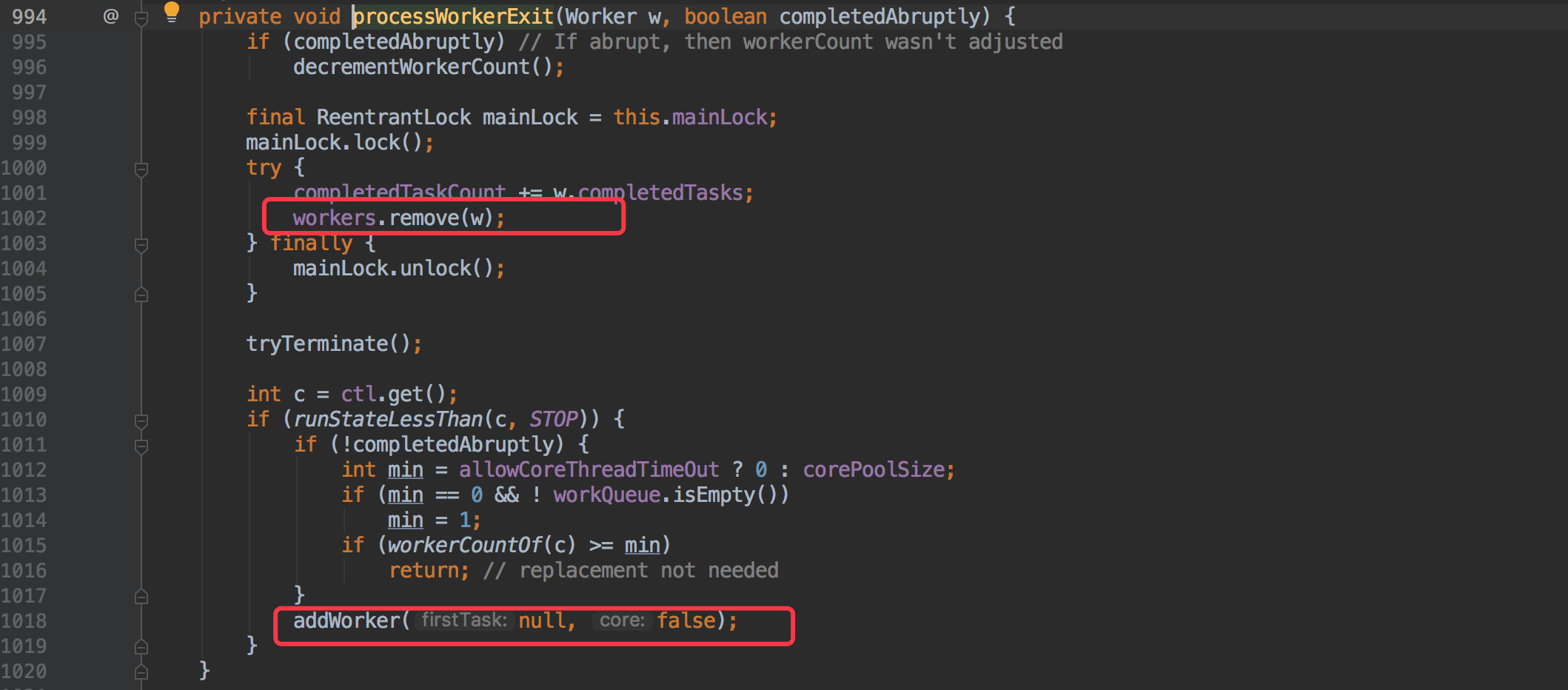
finally块中会执行processWorkerExit(w, completedAbruptly)方法。
看过之前《如何优雅的使用和理解线程池》的朋友应该还会有印象。
线程池中的任务都会被包装为一个内部 Worker 对象执行。
processWorkerExit 可以简单的理解为是把当前运行的线程销毁(workers.remove(w))、同时新增(addWorker())一个 Worker 对象接着处理;
就像是哪个零件坏掉后重新换了一个新的接着工作,但是旧零件负责的任务就没有了。
接下来看看 addWorker() 做了什么事情:
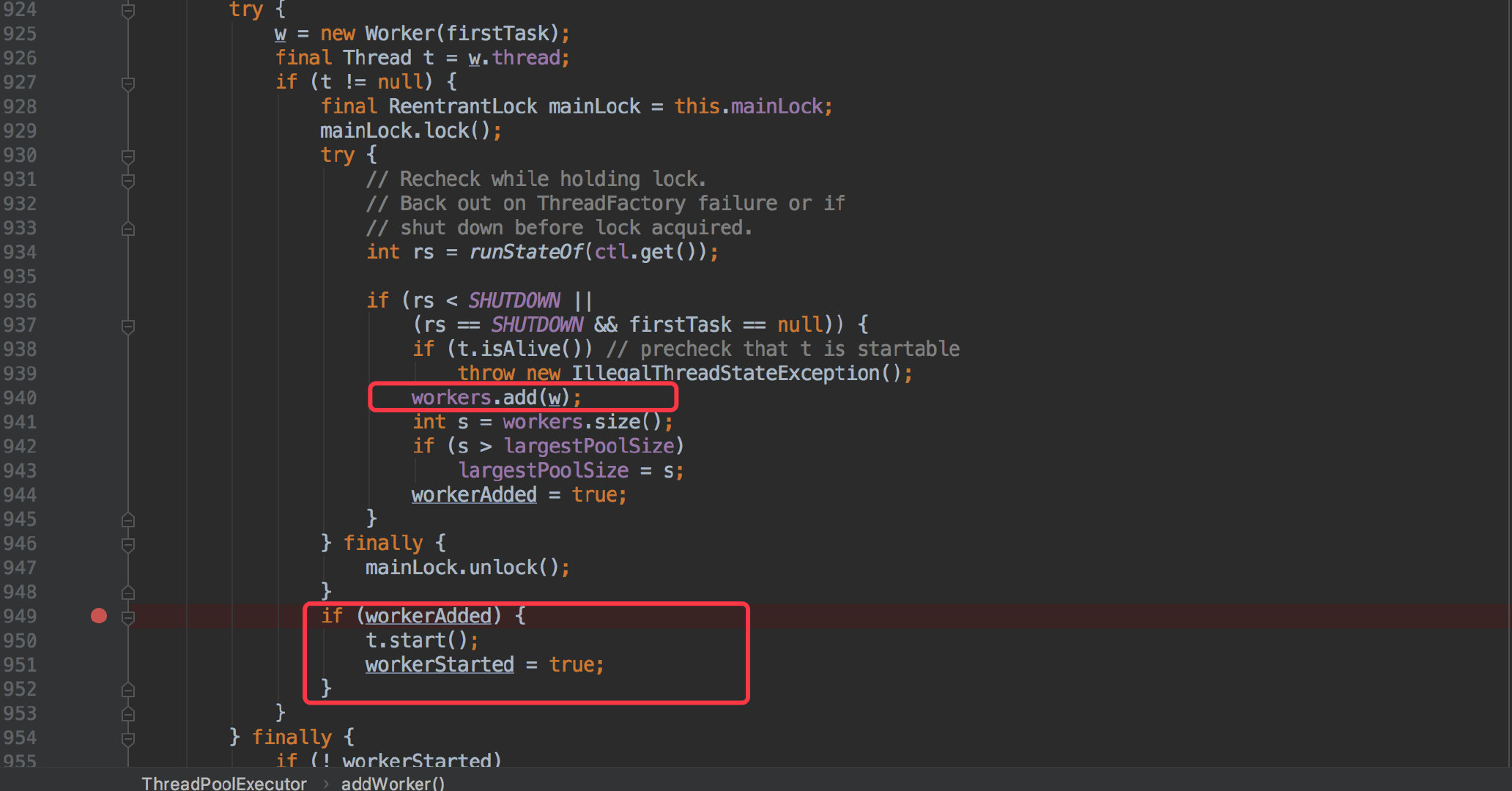
只看这次比较关心的部分;添加成功后会直接执行他的 start() 的方法。
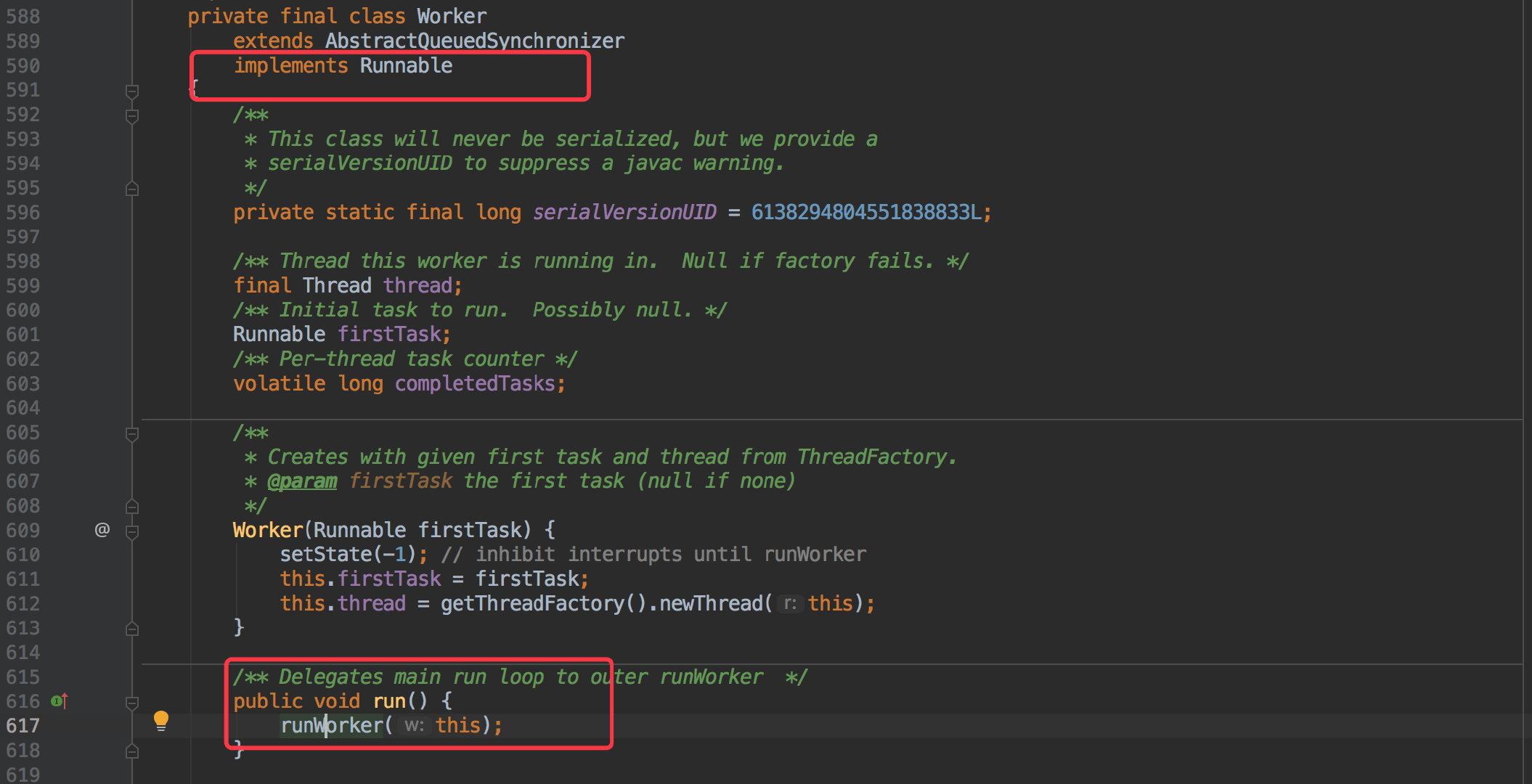
由于 Worker 实现了 Runnable 接口,所以本质上就是调用了 runWorker() 方法。
在 runWorker() 其实就是上文 ThreadPoolExecutor 抛出异常时的那个方法。
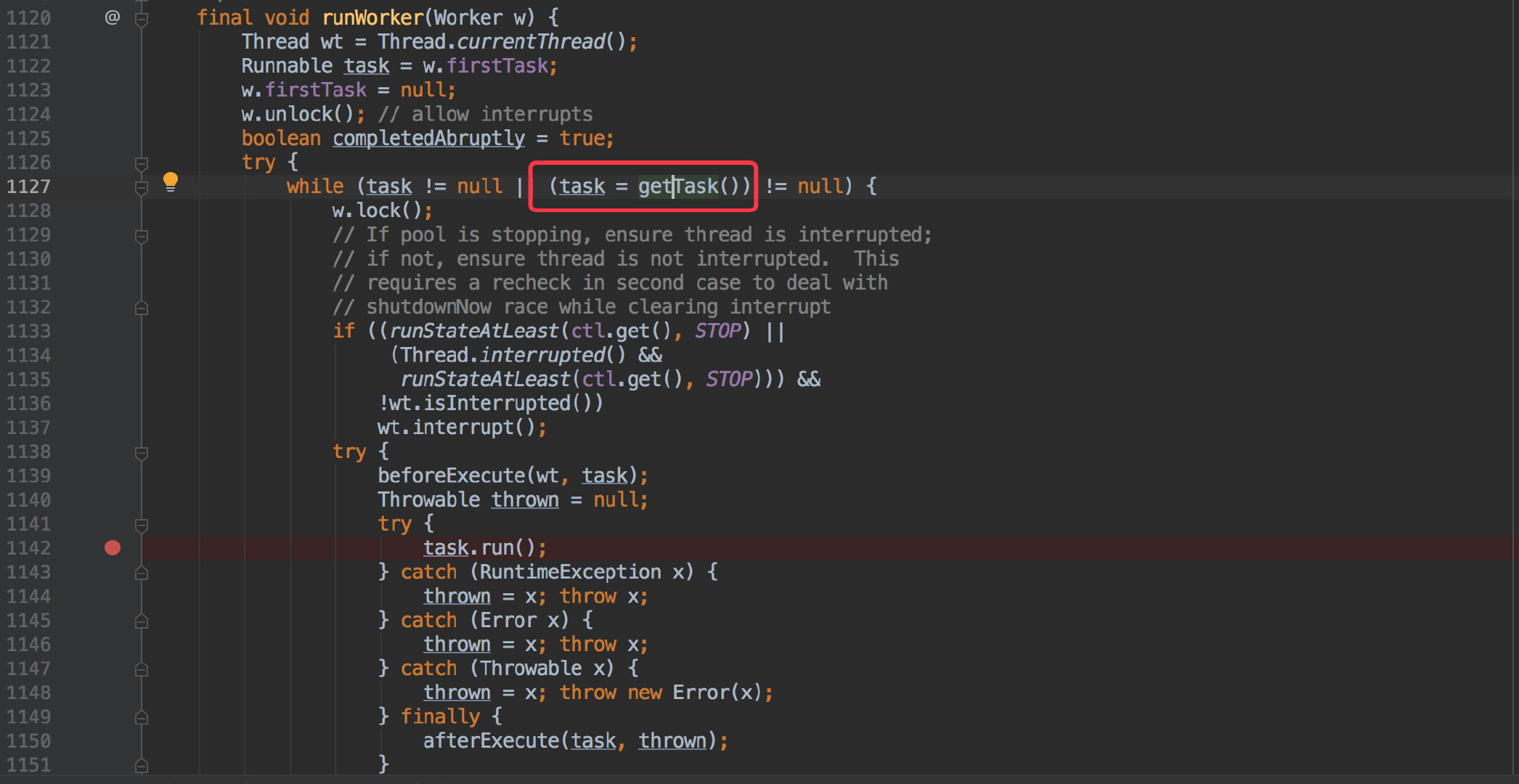
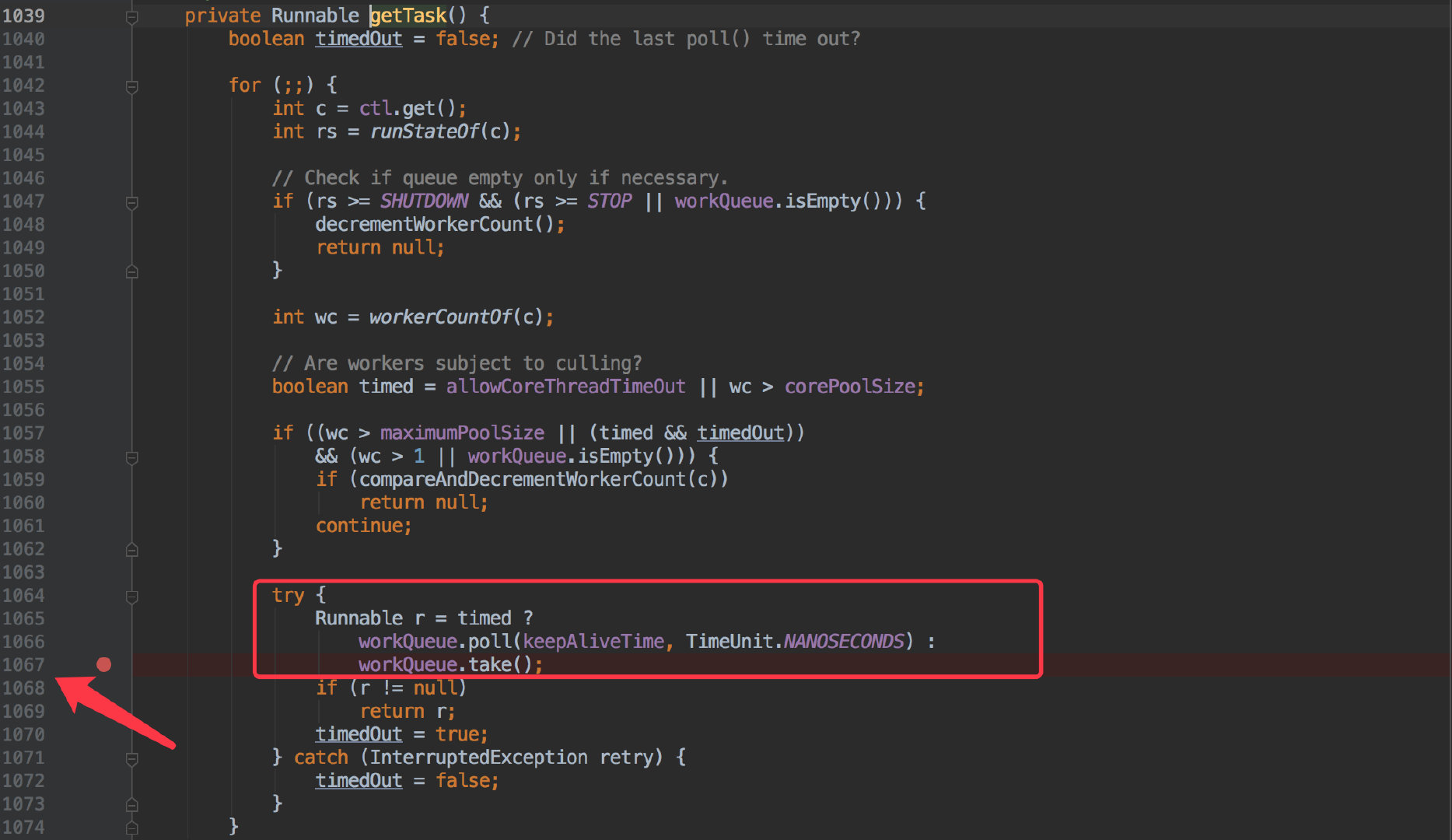
它会从队列里一直不停的获取待执行的任务,也就是 getTask();在 getTask 也能看出它会一直从内置的队列取出任务。
而一旦队列是空的,它就会 waiting 在 workQueue.take(),也就是我们从堆栈中发现的 1067 行代码。
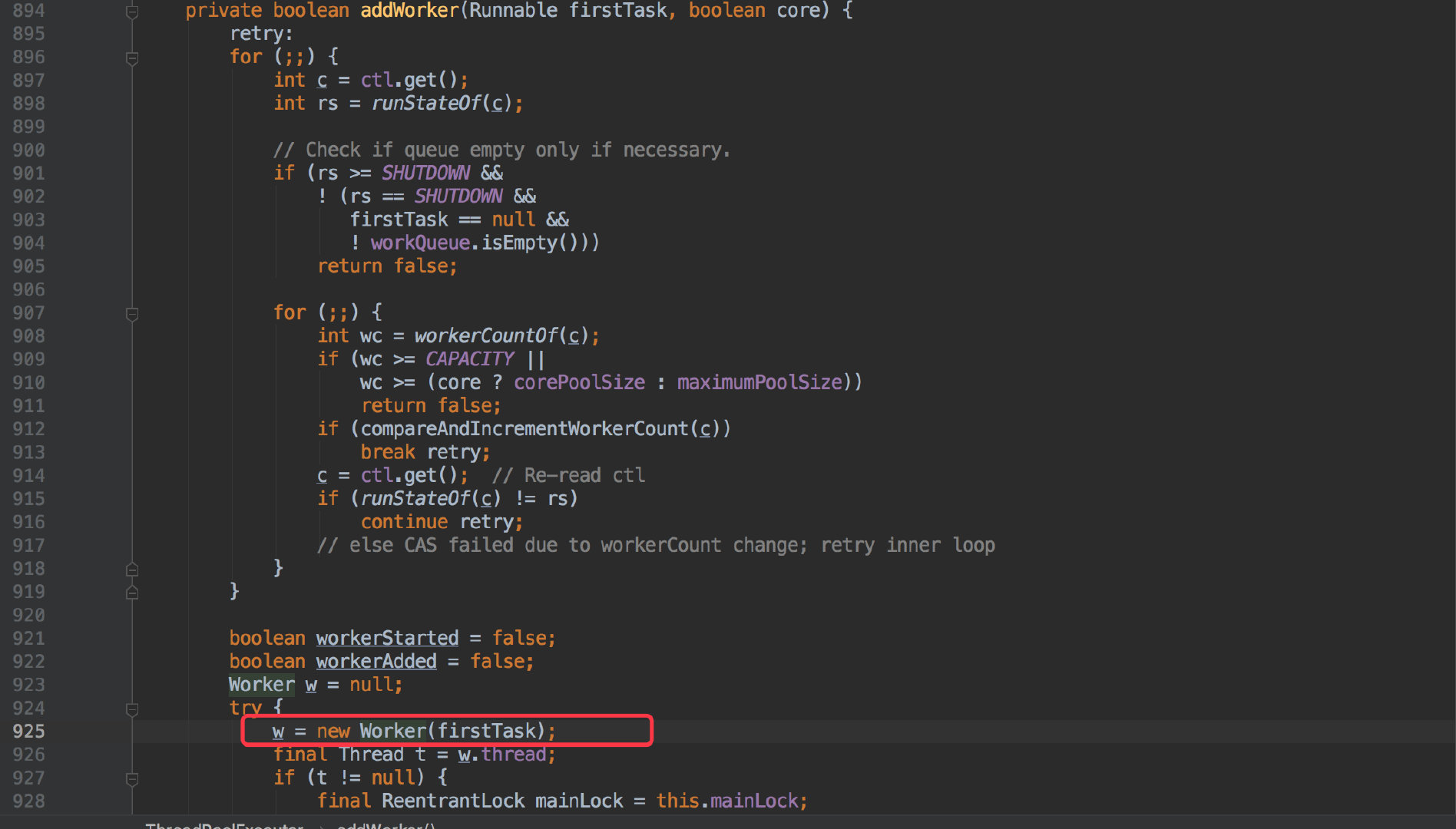


上文还提到了异常后的线程名称发生了改变,其实在 addWorker() 方法中可以看到 new Worker()时就会重新命名线程的名称,默认就是把后缀的计数+1。
这样一切都能解释得通了,真相只有一个:
在单个线程的线程池中一但抛出了未被捕获的异常时,线程池会回收当前的线程并创建一个新的
Worker; 它也会一直不断的从队列里获取任务来执行,但由于这是一个消费线程,根本没有生产者往里边丢任务,所以它会一直 waiting 在从队列里获取任务处,所以也就造成了线上的队列没有消费,业务线程池没有执行的问题。
所以之后线上的那个问题加上异常捕获之后也变得正常了,但我还是有点纳闷的是:
既然后续所有的任务都是在线程池中执行的,也就是纯异步了,那即便是出现异常也不会抛到消费线程中啊。
这不是把我之前储备的知识点推翻了嘛?不信邪!之后我让运维给了加上异常捕获后的线上错误日志。
结果发现在上文提到的众多 switch case 中,最后一个竟然是直接操作的数据库,导致一个非空字段报错了🤬!!
这事也给我个教训,还是得眼见为实啊。
虽然这个问题改动很小解决了,但复盘整个过程还是有许多需要改进的:
- 消费队列的线程名称竟然和业务线程的前缀一样,导致我光找它就花了许多时间,命名必须得调整。
- 开发规范,防御式编程大家需要养成习惯。
- 未知的技术栈需要谨慎,比如
disruptor,之前的团队应该只是看了个高性能的介绍就直接使用,并没有深究其原理;导致出现问题后对它拿不准。
实例代码:
你的点赞与分享是对我最大的支持