Go的Web框架大致可以分为这么两类:
- Router框架
- MVC类框架
Go的net/http包提供的就是这样的基础功能,写一个简单的http echo server只需要30s默认的net/http包中的mux不支持带参数的路由。
简单地来说,只要你的路由带有参数,并且这个项目的API数目超过了10,就尽量不要使用net/http中默认的路由。在Go开源界应用最广泛的router是httpRouter,很多开源的router框架都是基于httpRouter进行一定程度的改造的成果。
开源界有这么几种框架,第一种是对httpRouter进行简单的封装,然后提供定制的中间件和一些简单的小工具集成比如gin,主打轻量,易学,高性能。第二种是借鉴其它语言的编程风格的一些MVC类框架,例如beego,方便从其它语言迁移过来的程序员快速上手,快速开发。还有一些框架功能更为强大,除了数据库schema设计,大部分代码直接生成,例如goa。
在常见的Web框架中,router是必备的组件。Go语言圈子里router也时常被称为http的multiplexer。
RESTful是几年前刮起的API设计风潮,在RESTful中除了GET和POST之外,还使用了HTTP协议定义的几种其它的标准化语义。具体包括:
const (
MethodGet = "GET"
MethodHead = "HEAD"
MethodPost = "POST"
MethodPut = "PUT"
MethodPatch = "PATCH" // RFC 5789
MethodDelete = "DELETE"
MethodConnect = "CONNECT"
MethodOptions = "OPTIONS"
MethodTrace = "TRACE"
)来看看RESTful中常见的请求路径:
GET /repos/:owner/:repo/comments/:id/reactions
POST /projects/:project_id/columns
PUT /user/starred/:owner/:repo
DELETE /user/starred/:owner/:repoRESTful风格的API重度依赖请求路径。会将很多参数放在请求URI中。除此之外还会使用很多并不那么常见的HTTP状态码。
较流行的开源go Web框架大多使用httprouter,或是基于httprouter的变种对路由进行支持。
因为httprouter中使用的是显式匹配,所以在设计路由的时候需要规避一些会导致路由冲突的情况,例如:
conflict:
GET /user/info/:name
GET /user/:id
no conflict:
GET /user/info/:name
POST /user/:id简单来讲的话,如果两个路由拥有一致的http方法(指 GET/POST/PUT/DELETE)和请求路径前缀,且在某个位置出现了A路由是wildcard(指:id这种形式)参数,B路由则是普通字符串,那么就会发生路由冲突。路由冲突会在初始化阶段直接panic。
# panic: wildcard route ':id' conflicts with existing children in path '/user/:id'还有一点需要注意,因为httprouter考虑到字典树的深度,在初始化时会对参数的数量进行限制,所以在路由中的参数数目不能超过255,否则会导致httprouter无法识别后续的参数。不过这一点上也不用考虑太多,毕竟URI是人设计且给人来看的,相信没有长得夸张的URI能在一条路径中带有200个以上的参数。
除支持路径中的wildcard参数之外,httprouter还可以支持*号来进行通配,不过*号开头的参数只能放在路由的结尾,例如下面这样:
Pattern: /src/*filepath
/src/ filepath = ""
/src/somefile.go filepath = "somefile.go"
/src/subdir/somefile.go filepath = "subdir/somefile.go"这种设计在RESTful中可能不太常见,主要是为了能够使用httprouter来做简单的HTTP静态文件服务器。
除了正常情况下的路由支持,httprouter也支持对一些特殊情况下的回调函数进行定制,例如404的时候:
r := httprouter.New()
r.NotFound = http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("oh no, not found"))
})或者内部panic的时候:
r.PanicHandler = func(w http.ResponseWriter, r *http.Request, c interface{}) {
log.Printf("Recovering from panic, Reason: %#v", c.(error))
w.WriteHeader(http.StatusInternalServerError)
w.Write([]byte(c.(error).Error()))
}目前开源界最为流行(star数最多)的Web框架gin使用的就是httprouter的变种。
httprouter和众多衍生router使用的数据结构被称为压缩字典树(Radix Tree)。
典型的字典树结构:
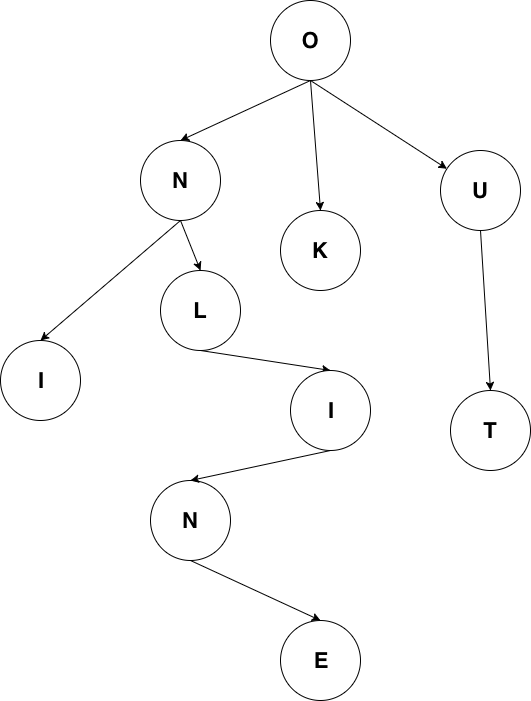
字典树常用来进行字符串检索,例如用给定的字符串序列建立字典树。**对于目标字符串,只要从根节点开始深度优先搜索,即可判断出该字符串是否曾经出现过,时间复杂度为O(n),n可以认为是目标字符串的长度。**为什么要这样做?字符串本身不像数值类型可以进行数值比较,两个字符串对比的时间复杂度取决于字符串长度。如果不用字典树来完成上述功能,要对历史字符串进行排序,再利用二分查找之类的算法去搜索,时间复杂度只高不低。可认为字典树是一种空间换时间的典型做法。
**普通的字典树有一个比较明显的缺点,就是每个字母都需要建立一个孩子节点,这样会导致字典树的层数比较深,压缩字典树相对好地平衡了字典树的优点和缺点。**是典型的压缩字典树结构:
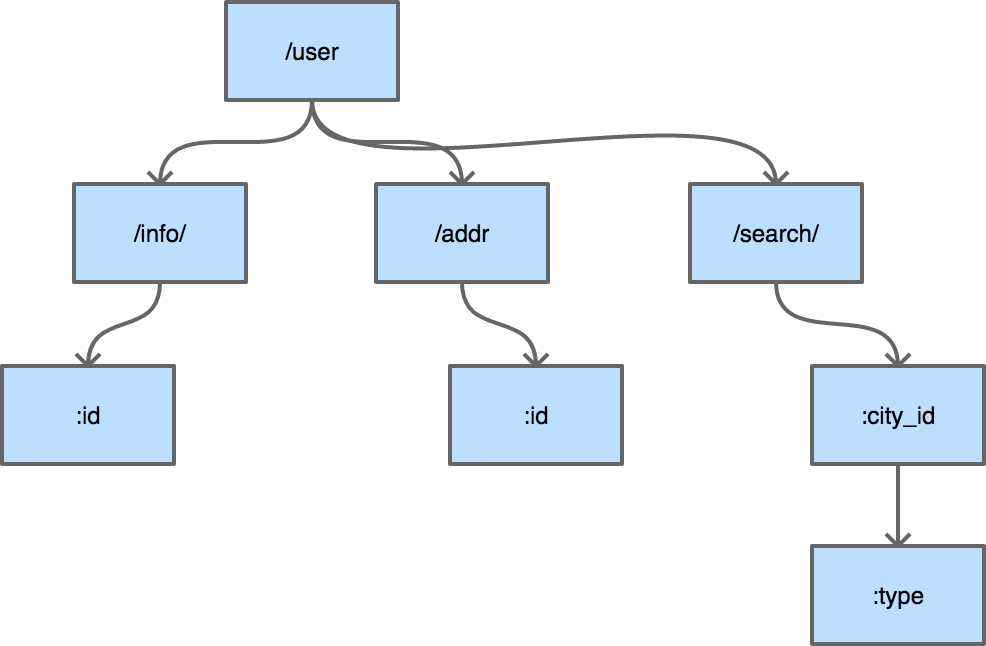
每个节点上不只存储一个字母了,这也是压缩字典树中“压缩”的主要含义。使用压缩字典树可以减少树的层数,同时因为每个节点上数据存储也比通常的字典树要多,所以程序的局部性较好(一个节点的path加载到cache即可进行多个字符的对比),从而对CPU缓存友好。
跟踪httprouter中一个典型的压缩字典树的创建过程,路由设定如下:
PUT /user/installations/:installation_id/repositories/:repository_id
GET /marketplace_listing/plans/
GET /marketplace_listing/plans/:id/accounts
GET /search
GET /status
GET /supporthttprouter的Router结构体中存储压缩字典树使用的是下述数据结构:
// 略去了其它部分的 Router struct
type Router struct {
// ...
trees map[string]*node
// ...
}trees中的key即为HTTP 1.1的RFC中定义的各种方法GET/HEAD/OPTIONS/POST/PUT/PATCH/DELETE。
**每一种方法对应的都是一棵独立的压缩字典树,这些树彼此之间不共享数据。**具体到我们上面用到的路由,PUT和GET是两棵树而非一棵。
radix的节点类型为*httprouter.node,为了说明方便,我们留下了目前关心的几个字段:
path: 当前节点对应的路径中的字符串
wildChild: 子节点是否为参数节点,即 wildcard node,或者说 :id 这种类型的节点
nType: 当前节点类型,有四个枚举值: 分别为 static/root/param/catchAll。
static // 非根节点的普通字符串节点
root // 根节点
param // 参数节点,例如 :id
catchAll // 通配符节点,例如 *anyway
indices:子节点索引,当子节点为非参数类型,即本节点的wildChild为false时,会将每个子节点的首字母放在该索引数组。说是数组,实际上是个string。插入GET /marketplace_listing/plans时,结构如下:

因为第一个路由没有参数,path都被存储到根节点上了。所以只有一个节点。
然后插入GET /marketplace_listing/plans/:id/accounts,新的路径与之前的路径有共同的前缀,且可以直接在之前叶子节点后进行插入,那么结果也很简单,插入后的树结构如下:
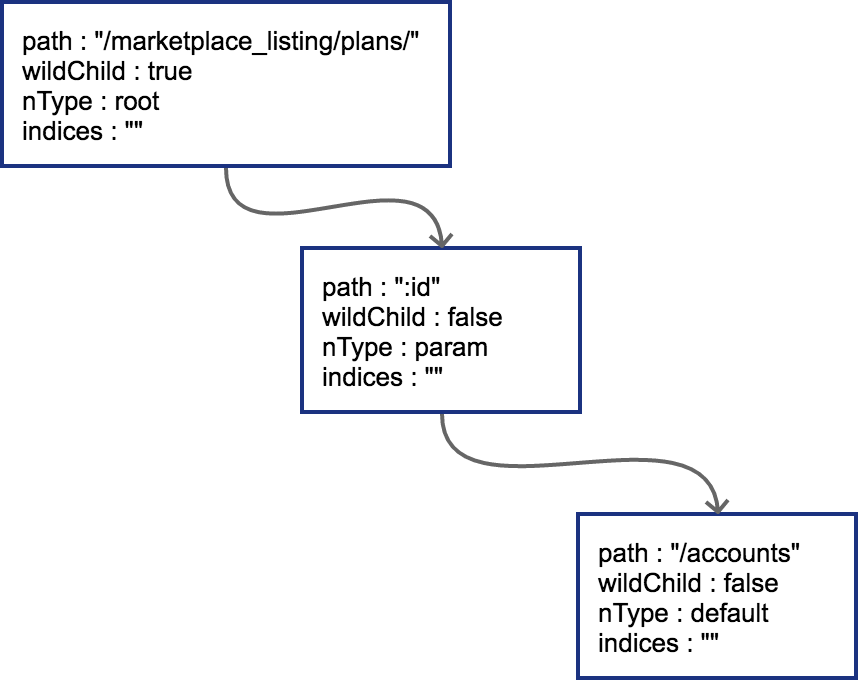
由于:id这个节点只有一个字符串的普通子节点,所以indices还依然不需要处理。
上面这种情况比较简单,新的路由可以直接作为原路由的子节点进行插入。
接下来我们插入GET /search,这时会导致树的边分裂,插入后的树结构如下:
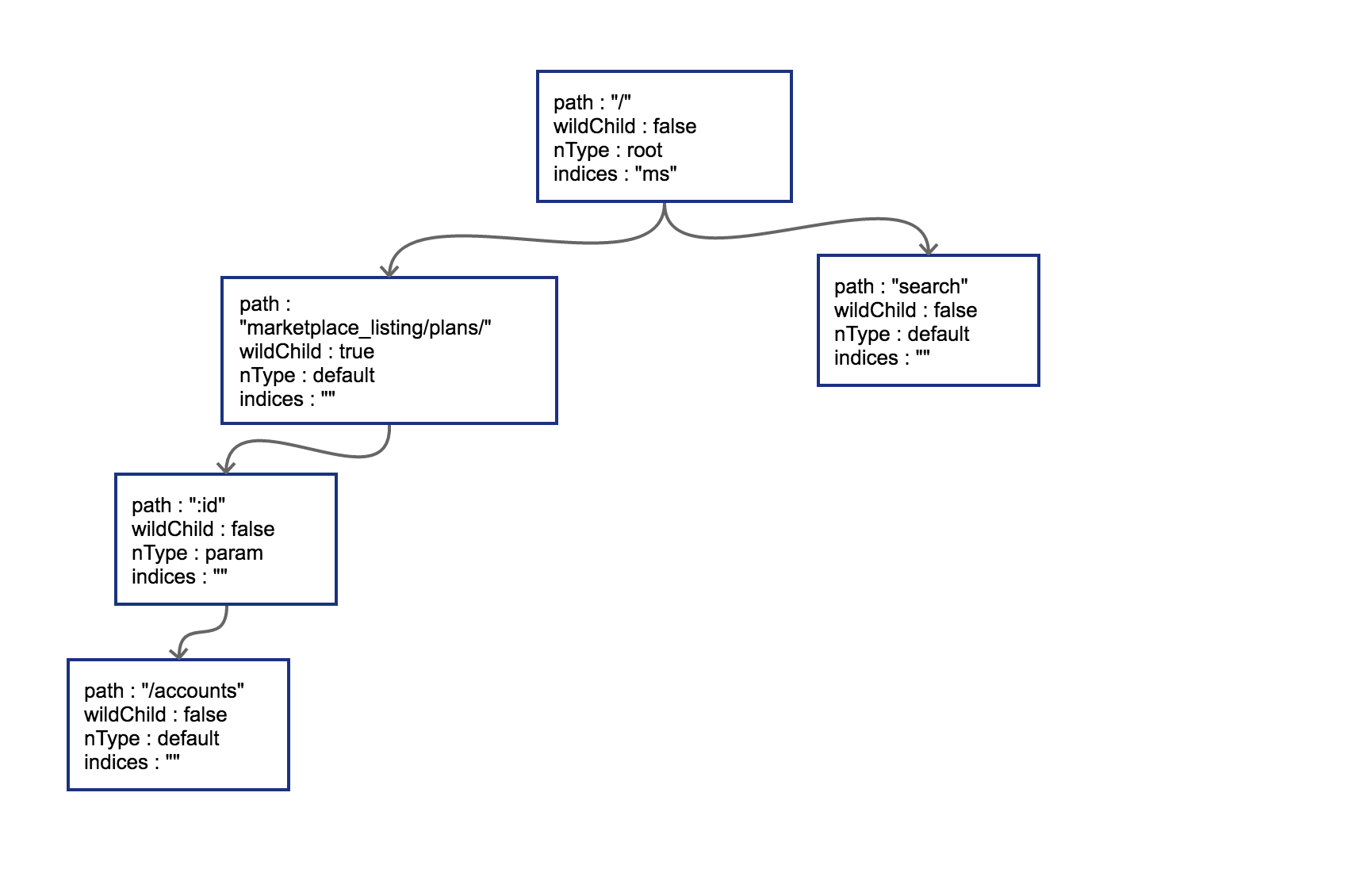
原有路径和新的路径在初始的/位置发生分裂,这样需要把原有的root节点内容下移,再将新路由 search同样作为子节点挂在root节点之下。这时候因为子节点出现多个,root节点的indices提供子节点索引,这时候该字段就需要派上用场了。"ms"代表子节点的首字母分别为m(marketplace)和s(search)。
我们一口作气,把GET /status和GET /support也插入到树中。这时候会导致在search节点上再次发生分裂,最终结果如下:
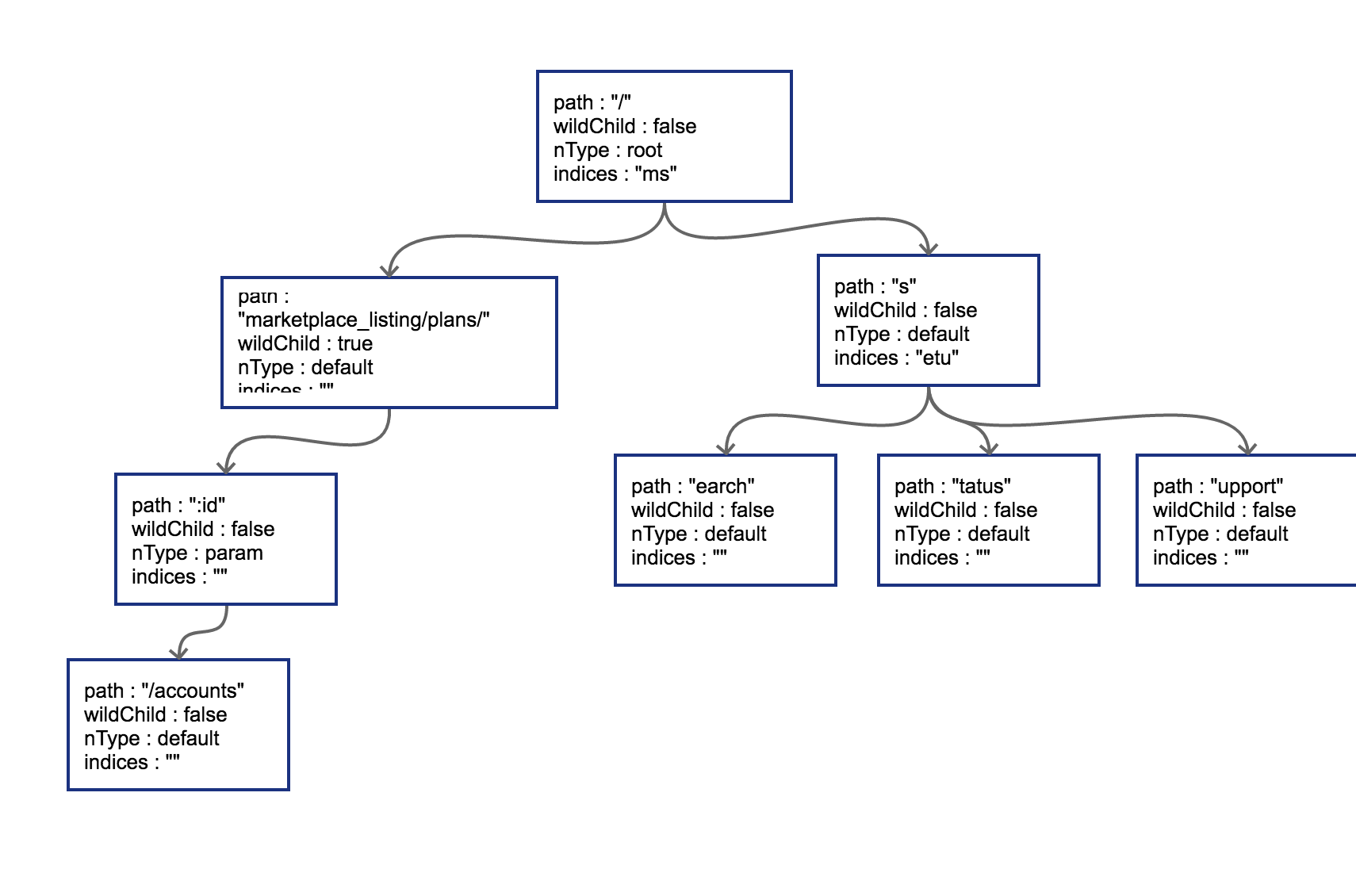
在路由本身只有字符串的情况下,不会发生任何冲突。只有当路由中含有wildcard(类似 :id)或者catchAll的情况下才可能冲突。这一点在前面已经提到了。
子节点的冲突处理很简单,分几种情况:
- 在插入wildcard节点时,父节点的children数组非空且wildChild被设置为false。例如:
GET /user/getAll和GET /user/:id/getAddr,或者GET /user/*aaa和GET /user/:id。 - 在插入wildcard节点时,父节点的children数组非空且wildChild被设置为true,但该父节点的wildcard子节点要插入的wildcard名字不一样。例如:
GET /user/:id/info和GET /user/:name/info。 - 在插入catchAll节点时,父节点的children非空。例如:
GET /src/abc和GET /src/*filename,或者GET /src/:id和GET /src/*filename。 - 在插入static节点时,父节点的wildChild字段被设置为true。
- 在插入static节点时,父节点的children非空,且子节点nType为catchAll。
只要发生冲突,都会在初始化的时候panic。例如,在插入我们臆想的路由GET /marketplace_listing/plans/ohyes时,出现第4种冲突情况:它的父节点marketplace_listing/plans/的wildChild字段为true。
Web框架中的中间件(middleware)技术原理。
对于大多数的场景来讲,非业务的需求都是在http请求处理前做一些事情,并且在响应完成之后做一些事情。
http.Handle("/", timeMiddleware(http.HandlerFunc(hello)))任何方法实现了ServeHTTP,即是一个合法的http.Handler,读到这里你可能会有一些混乱,我们先来梳理一下http库的Handler,HandlerFunc和ServeHTTP的关系:
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
type HandlerFunc func(ResponseWriter, *Request)
func (f HandlerFunc) ServeHTTP(w ResponseWriter, r *Request) {
f(w, r)
}只要你的handler函数签名是:
func (ResponseWriter, *Request)那么这个handler和http.HandlerFunc()就有了一致的函数签名,可以将该handler()函数进行类型转换,转为http.HandlerFunc。而http.HandlerFunc实现了http.Handler这个接口。在http库需要调用你的handler函数来处理http请求时,会调用HandlerFunc()的ServeHTTP()函数,可见一个请求的基本调用链是这样的:
h = getHandler() => h.ServeHTTP(w, r) => h(w, r)上面提到的把自定义handler转换为http.HandlerFunc()这个过程是必须的,因为我们的handler没有直接实现ServeHTTP这个接口。上面的代码中我们看到的HandleFunc(注意HandlerFunc和HandleFunc的区别)里也可以看到这个强制转换过程:
func HandleFunc(pattern string, handler func(ResponseWriter, *Request)) {
DefaultServeMux.HandleFunc(pattern, handler)
}
// 调用
func (mux *ServeMux) HandleFunc(pattern string, handler func(ResponseWriter, *Request)) {
mux.Handle(pattern, HandlerFunc(handler))
}中间件要做的事情就是通过一个或多个函数对handler进行包装,返回一个包括了各个中间件逻辑的函数链。
customizedHandler = logger(timeout(ratelimit(helloHandler)))这个函数链在执行过程中的上下文:
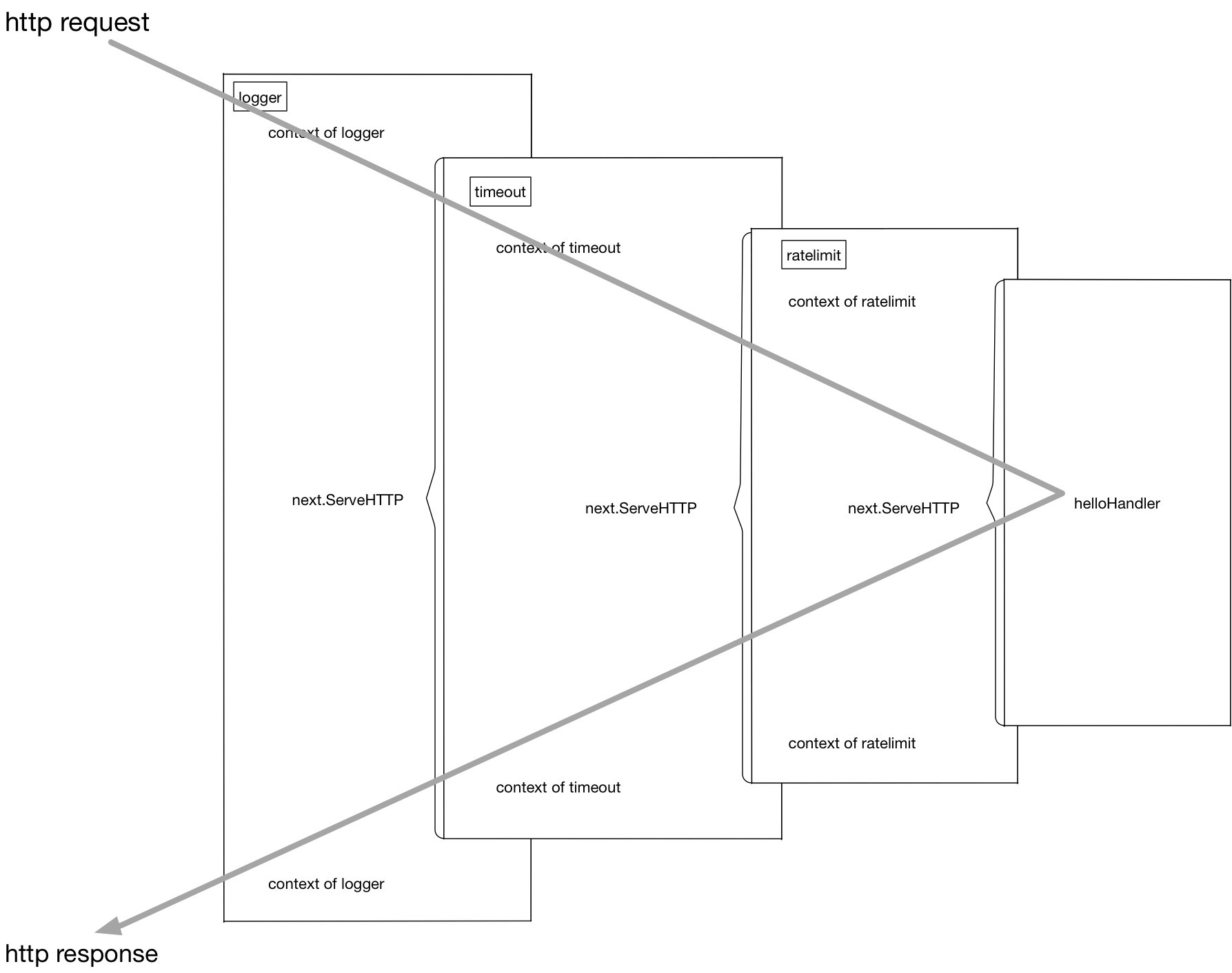
这个流程在进行请求处理的时候就是不断地进行函数压栈再出栈,有一些类似于递归的执行流:
[exec of logger logic] 函数栈: []
[exec of timeout logic] 函数栈: [logger]
[exec of ratelimit logic] 函数栈: [timeout/logger]
[exec of helloHandler logic] 函数栈: [ratelimit/timeout/logger]
[exec of ratelimit logic part2] 函数栈: [timeout/logger]
[exec of timeout logic part2] 函数栈: [logger]
[exec of logger logic part2] 函数栈: []函数套函数的用法不是很美观,同时也不具备什么可读性。
r = NewRouter()
r.Use(logger)
r.Use(timeout)
r.Use(ratelimit)
r.Add("/", helloHandler)通过多步设置,我们拥有了和上一节差不多的执行函数链。胜在直观易懂,如果我们要增加或者删除中间件,只要简单地增加删除对应的Use()调用就可以了。非常方便。
以较流行的开源Go语言框架chi为例:
compress.go
=> 对http的响应体进行压缩处理
heartbeat.go
=> 设置一个特殊的路由,例如/ping,/healthcheck,用来给负载均衡一类的前置服务进行探活
logger.go
=> 打印请求处理处理日志,例如请求处理时间,请求路由
profiler.go
=> 挂载pprof需要的路由,如`/pprof`、`/pprof/trace`到系统中
realip.go
=> 从请求头中读取X-Forwarded-For和X-Real-IP,将http.Request中的RemoteAddr修改为得到的RealIP
requestid.go
=> 为本次请求生成单独的requestid,可一路透传,用来生成分布式调用链路,也可用于在日志中串连单次请求的所有逻辑
timeout.go
=> 用context.Timeout设置超时时间,并将其通过http.Request一路透传下去
throttler.go
=> 通过定长大小的channel存储token,并通过这些token对接口进行限流定义如下的结构体:
type Nested struct {
Email string `validate:"email"`
}
type T struct {
Age int `validate:"eq=10"`
Nested Nested
}validator 树结构:
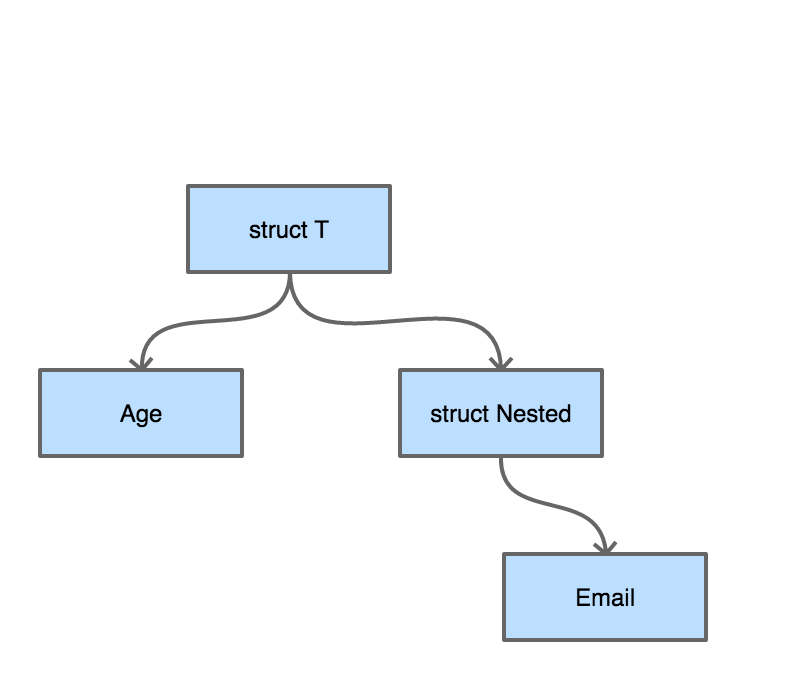
通过反射对结构体遍历。
Go官方提供了database/sql包来给用户进行和数据库打交道的工作,database/sql库实际只提供了一套操作数据库的接口和规范,例如抽象好的SQL预处理(prepare),连接池管理,数据绑定,事务,错误处理等等。官方并没有提供具体某种数据库实现的协议支持。
和具体的数据库,例如MySQL打交道,还需要再引入MySQL的驱动,像下面这样:
import "database/sql"
import _ "github.com/go-sql-driver/mysql"
db, err := sql.Open("mysql", "user:password@/dbname")import _ "github.com/go-sql-driver/mysql"这条import语句会调用了mysql包的init函数,做的事情也很简单:
func init() {
sql.Register("mysql", &MySQLDriver{})
}在sql包的全局map里把mysql这个名字的driver注册上。Driver在sql包中是一个接口:
type Driver interface {
Open(name string) (Conn, error)
}调用sql.Open()返回的db对象就是这里的Conn。
type Conn interface {
Prepare(query string) (Stmt, error)
Close() error
Begin() (Tx, error)
}对象关系映射(英语:Object Relational Mapping,简称ORM,或O/RM,或O/R mapping),是一种程序设计技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换。从效果上说,它其实是创建了一个可在编程语言里使用的“虚拟对象数据库”。
相比ORM来说,SQL Builder在SQL和项目可维护性之间取得了比较好的平衡。首先sql builder不像ORM那样屏蔽了过多的细节,其次从开发的角度来讲,SQL Builder进行简单封装后也可以非常高效地完成开发,举个例子:
where := map[string]interface{} {
"order_id > ?" : 0,
"customer_id != ?" : 0,
}
limit := []int{0,100}
orderBy := []string{"id asc", "create_time desc"}
orders := orderModel.GetList(where, limit, orderBy)无论是ORM还是SQL Builder都有一个致命的缺点,就是没有办法进行系统上线的事前sql审核。虽然很多ORM和SQL Builder也提供了运行期打印sql的功能,但只在查询的时候才能进行输出。而SQL Builder和ORM本身提供的功能太过灵活。使得你不可能通过测试枚举出所有可能在线上执行的sql。
计算机程序可依据其瓶颈分为磁盘IO瓶颈型,CPU计算瓶颈型,网络带宽瓶颈型,分布式场景下有时候也会外部系统而导致自身瓶颈。
Web系统打交道最多的是网络,无论是接收,解析用户请求,访问存储,还是把响应数据返回给用户,都是要走网络的。在没有epoll/kqueue之类的系统提供的IO多路复用接口之前,多个核心的现代计算机最头痛的是C10k问题,C10k问题会导致计算机没有办法充分利用CPU来处理更多的用户连接,进而没有办法通过优化程序提升CPU利用率来处理更多的请求。
自从Linux实现了epoll,FreeBSD实现了kqueue,这个问题基本解决了,我们可以借助内核提供的API轻松解决当年的C10k问题,也就是说如今如果你的程序主要是和网络打交道,那么瓶颈一定在用户程序而不在操作系统内核。
wrk对http服务压测,多次测试的结果在4万左右的QPS浮动,响应时间最多也就是40ms左右。压测命令:
wrk -c 10 -d 10s -t10 http://localhost:9090
# Running 10s test @ http://localhost:9090
# 10 threads and 10 connections
# Thread Stats Avg Stdev Max +/- Stdev
# Latency 334.76us 1.21ms 45.47ms 98.27%
# Req/Sec 4.42k 633.62 6.90k 71.16%
# 443582 requests in 10.10s, 54.15MB read
# Requests/sec: 43911.68
# Transfer/sec: 5.36MB对于IO/Network瓶颈类的程序,其表现是网卡/磁盘IO会先于CPU打满,这种情况即使优化CPU的使用也不能提高整个系统的吞吐量,只能提高磁盘的读写速度,增加内存大小,提升网卡的带宽来提升整体性能。而CPU瓶颈类的程序,则是在存储和网卡未打满之前CPU占用率先到达100%,CPU忙于各种计算任务,IO设备相对则较闲。
无论哪种类型的服务,在资源使用到极限的时候都会导致请求堆积,超时,系统hang死,最终伤害到终端用户。对于分布式的Web服务来说,瓶颈还不一定总在系统内部,也有可能在外部。非计算密集型的系统往往会在关系型数据库环节失守,而这时候Web模块本身还远远未达到瓶颈。
不管我们的服务瓶颈在哪里,最终要做的事情都是一样的,那就是流量限制。
流量限制的手段有很多,最常见的:漏桶、令牌桶两种:
- 漏桶是指我们有一个一直装满了水的桶,每过固定的一段时间即向外漏一滴水。如果你接到了这滴水,那么你就可以继续服务请求,如果没有接到,那么就需要等待下一滴水。
- 令牌桶则是指匀速向桶中添加令牌,服务请求时需要从桶中获取令牌,令牌的数目可以按照需要消耗的资源进行相应的调整。如果没有令牌,可以选择等待,或者放弃。
这两种方法看起来很像,不过还是有区别的。漏桶流出的速率固定,而令牌桶只要在桶中有令牌,那就可以拿。也就是说令牌桶是允许一定程度的并发的,比如同一个时刻,有100个用户请求,只要令牌桶中有100个令牌,那么这100个请求全都会放过去。令牌桶在桶中没有令牌的情况下也会退化为漏桶模型。
实际应用中令牌桶应用较为广泛,开源界流行的限流器大多数都是基于令牌桶思想的。并且在此基础上进行了一定程度的扩充,比如github.com/juju/ratelimit提供了几种不同特色的令牌桶填充方式:
func NewBucket(fillInterval time.Duration, capacity int64) *Bucket默认的令牌桶,fillInterval指每过多长时间向桶里放一个令牌,capacity是桶的容量,超过桶容量的部分会被直接丢弃。桶初始是满的。
func NewBucketWithQuantum(fillInterval time.Duration, capacity, quantum int64) *Bucket和普通的NewBucket()的区别是,每次向桶中放令牌时,是放quantum个令牌,而不是一个令牌。
func NewBucketWithRate(rate float64, capacity int64) *Bucket这个就有点特殊了,会按照提供的比例,每秒钟填充令牌数。例如capacity是100,而rate是0.1,那么每秒会填充10个令牌。
从桶中获取令牌也提供了几个API:
func (tb *Bucket) Take(count int64) time.Duration {}
func (tb *Bucket) TakeAvailable(count int64) int64 {}
func (tb *Bucket) TakeMaxDuration(count int64, maxWait time.Duration) (
time.Duration, bool,
) {}
func (tb *Bucket) Wait(count int64) {}
func (tb *Bucket) WaitMaxDuration(count int64, maxWait time.Duration) bool {}从功能上来看,令牌桶模型就是对全局计数的加减法操作过程,可以用buffered channel来完成简单的加令牌取令牌操作。
令牌桶每隔一段固定的时间向桶中放令牌,如果我们记下上一次放令牌的时间为 t1,和当时的令牌数k1,放令牌的时间间隔为ti,每次向令牌桶中放x个令牌,令牌桶容量为cap。现在如果有人来调用TakeAvailable来取n个令牌,我们将这个时刻记为t2。在t2时刻,令牌桶中理论上应该有多少令牌呢?伪代码如下:
cur = k1 + ((t2 - t1)/ti) * x
cur = cur > cap ? cap : cur我们用两个时间点的时间差,再结合其它的参数,理论上在取令牌之前就完全可以知道桶里有多少令牌了。那劳心费力地像本小节前面向channel里填充token的操作,理论上是没有必要的。只要在每次Take的时候,再对令牌桶中的token数进行简单计算,就可以得到正确的令牌数。是不是很像惰性求值的感觉?
在得到正确的令牌数之后,再进行实际的Take操作就好,这个Take操作只需要对令牌数进行简单的减法即可,记得加锁以保证并发安全。
虽然性能指标很重要,但对用户提供服务时还应考虑服务整体的QoS。QoS全称是Quality of Service,顾名思义是服务质量。QoS包含有可用性、吞吐量、时延、时延变化和丢失等指标。一般来讲我们可以通过优化系统,来提高Web服务的CPU利用率,从而提高整个系统的吞吐量。但吞吐量提高的同时,用户体验是有可能变差的。用户角度比较敏感的除了可用性之外,还有时延。虽然你的系统吞吐量高,但半天刷不开页面,想必会造成大量的用户流失。所以在大公司的Web服务性能指标中,除了平均响应时延之外,还会把响应时间的95分位,99分位也拿出来作为性能标准。平均响应在提高CPU利用率没受到太大影响时,可能95分位、99分位的响应时间大幅度攀升了,那么这时候就要考虑提高这些CPU利用率所付出的代价是否值得了。
在线系统的机器一般都会保持CPU有一定的余裕。
流行的Web框架大多数是MVC框架,MVC这个概念最早由Trygve Reenskaug在1978年提出,为了能够对GUI类型的应用进行方便扩展,将程序划分为:
- 控制器(Controller)- 负责转发请求,对请求进行处理。
- 视图(View) - 界面设计人员进行图形界面设计。
- 模型(Model) - 程序员编写程序应有的功能(实现算法等等)、数据库专家进行数据管理和数据库设计(可以实现具体的功能)。
随着时代的发展,前端也变成了越来越复杂的工程,为了更好地工程化,现在更为流行的一般是前后分离的架构。可以认为前后分离是把V层从MVC中抽离单独成为项目。这样一个后端项目一般就只剩下 M和C层了。前后端之间通过ajax来交互,有时候要解决跨域的问题,但也已经有了较为成熟的方案。下图是一个前后分离的系统的简易交互图。
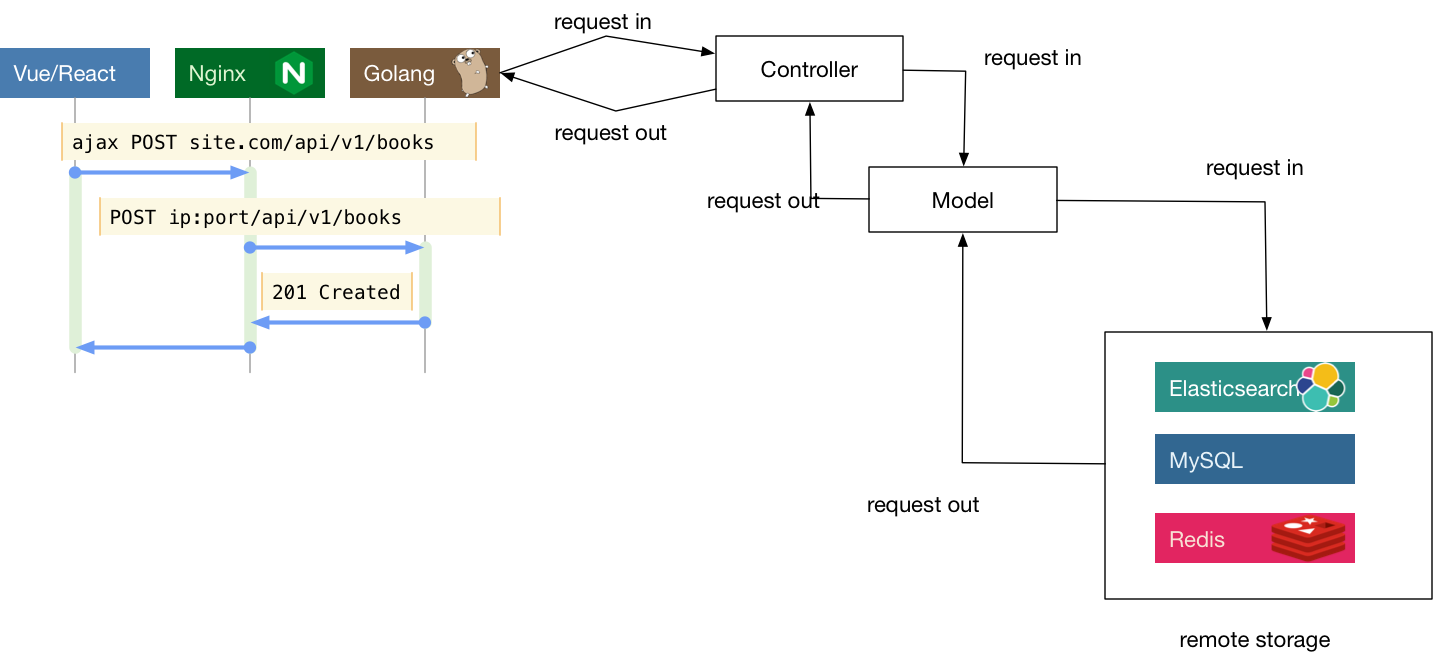
现在比较流行的纯后端API模块一般采用下述划分方法:
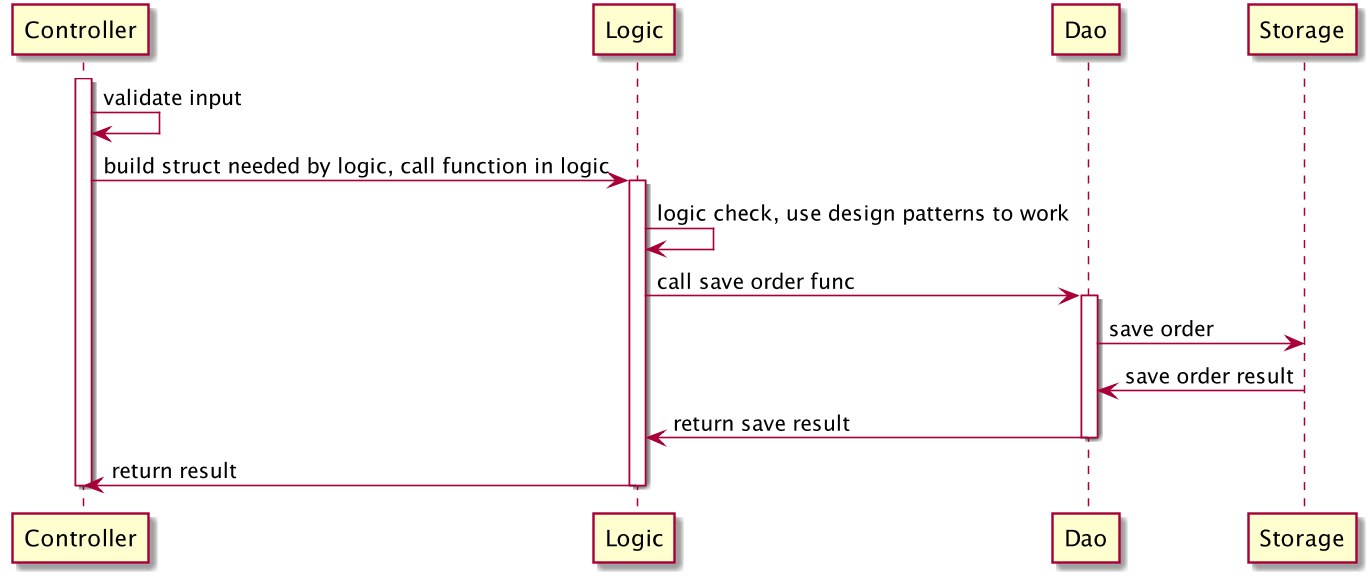
- Controller,与上述类似,服务入口,负责处理路由,参数校验,请求转发。
- Logic/Service,逻辑(服务)层,一般是业务逻辑的入口,可以认为从这里开始,所有的请求参数一定是合法的。业务逻辑和业务流程也都在这一层中。常见的设计中会将该层称为 Business Rules。
- DAO/Repository,这一层主要负责和数据、存储打交道。将下层存储以更简单的函数、接口形式暴露给 Logic 层来使用。负责数据的持久化工作。
每一层都会做好自己的工作,然后用请求当前的上下文构造下一层工作所需要的结构体或其它类型参数,然后调用下一层的函数。在工作完成之后,再把处理结果一层层地传出到入口,如下图所示。
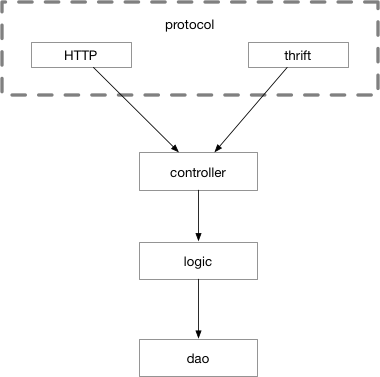
划分为CLD三层之后,在C层之前我们可能还需要同时支持多种协议。本章前面讲到的thrift、gRPC和http并不是一定只选择其中一种,有时我们需要支持其中的两种,比如同一个接口,我们既需要效率较高的thrift,也需要方便debug的http入口。即除了CLD之外,还需要一个单独的protocol层,负责处理各种交互协议的细节。这样请求的流程会变成下图所示。
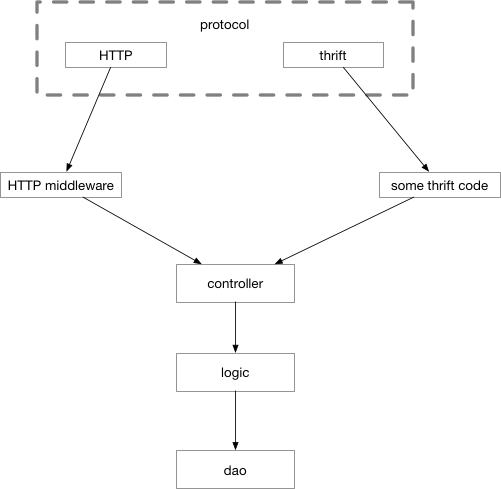
协议细节处理这一层有大量重复劳动,每一个接口在协议这一层的处理,无非是把数据从协议特定的结构体(例如http.Request,thrift的被包装过了) 读出来,再绑定到我们协议无关的结构体上,再把这个结构体映射到Controller入口的结构体上,这些代码长得都差不多。差不多的代码都遵循着某种模式,那么我们可以对这些模式进行简单的抽象,用代码生成的方式,把繁复的协议处理代码从工作内容中抽离出去。
在Web项目中经常会遇到外部依赖环境的变化,比如:
- 公司的老存储系统年久失修,现在已经没有人维护了,新的系统上线也没有考虑平滑迁移,但最后通牒已下,要求N天之内迁移完毕。
- 平台部门的老用户系统年久失修,现在已经没有人维护了,真是悲伤的故事。新系统上线没有考虑兼容老接口,但最后通牒已下,要求N个月之内迁移完毕。
- 公司的老消息队列人走茶凉,年久失修,新来的技术精英们没有考虑向前兼容,但最后通牒已下,要求半年之内迁移完毕。
互联网公司只要可以活过三年,工程方面面临的首要问题就是代码膨胀。系统的代码膨胀之后,可以将系统中与业务本身流程无关的部分做拆解和异步化。什么算是业务无关呢,比如一些统计、反作弊、营销发券、价格计算、用户状态更新等等需求。这些需求往往依赖于主流程的数据,但又只是挂在主流程上的旁支,自成体系。
这时候我们就可以把这些旁支拆解出去,作为独立的系统来部署、开发以及维护。这些旁支流程的时延如若非常敏感,比如用户在界面上点了按钮,需要立刻返回(价格计算、支付),那么需要与主流程系统进行RPC通信,并且在通信失败时,要将结果直接返回给用户。如果时延不敏感,比如抽奖系统,结果稍后公布的这种,或者非实时的统计类系统,那么就没有必要在主流程里为每一套系统做一套RPC流程。我们只要将下游需要的数据打包成一条消息,传入消息队列,之后的事情与主流程一概无关(当然,与用户的后续交互流程还是要做的)。
通过拆解和异步化虽然解决了一部分问题,但并不能解决所有问题。随着业务发展,单一职责的模块也会变得越来越复杂,这是必然的趋势。一件事情本身变的复杂的话,这时候拆解和异步化就不灵了。我们还是要对事情本身进行一定程度的封装抽象。
最基本的封装过程,我们把相似的行为放在一起,然后打包成一个一个的函数。
func BusinessProcess(ctx context.Context, params Params) (resp, error){
ValidateLogin()
ValidateParams()
AntispamCheck()
GetPrice()
CreateOrder()
UpdateUserStatus()
NotifyDownstreamSystems()
}不管是多么复杂的业务,系统内的逻辑都是可以分解为step1 -> step2 -> step3 ...这样的流程。
func CreateOrder() {
ValidateDistrict() // 判断是否是地区限定商品
ValidateVIPProduct() // 检查是否是只提供给 vip 的商品
GetUserInfo() // 从用户系统获取更详细的用户信息
GetProductDesc() // 从商品系统中获取商品在该时间点的详细信息
DecrementStorage() // 扣减库存
CreateOrderSnapshot() // 创建订单快照
return CreateSuccess
}在阅读业务流程代码时,我们只要阅读其函数名就能知晓在该流程中完成了哪些操作,如果需要修改细节,那么就继续深入到每一个业务步骤去看具体的流程。
业务发展的早期,是不适宜引入接口(interface)的,很多时候业务流程变化很大,过早引入接口会使业务系统本身增加很多不必要的分层,从而导致每次修改几乎都要全盘否定之前的工作。
当业务发展到一定阶段,主流程稳定之后,就可以适当地使用接口来进行抽象了。这里的稳定,是指主流程的大部分业务步骤已经确定,即使再进行修改,也不会进行大规模的变动,而只是小修小补,或者只是增加或删除少量业务步骤。
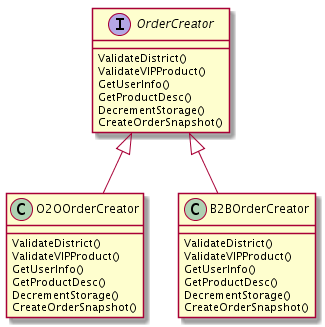
如果我们在开发过程中,已经对业务步骤进行了良好的封装,这时候进行接口抽象化就会变的非常容易,伪代码:
// OrderCreator 创建订单流程
type OrderCreator interface {
ValidateDistrict() // 判断是否是地区限定商品
ValidateVIPProduct() // 检查是否是只提供给 vip 的商品
GetUserInfo() // 从用户系统获取更详细的用户信息
GetProductDesc() // 从商品系统中获取商品在该时间点的详细信息
DecrementStorage() // 扣减库存
CreateOrderSnapshot() // 创建订单快照
}我们只要把之前写过的步骤函数签名都提到一个接口中,就可以完成抽象了。
在进行抽象之前,我们应该想明白的一点是,引入接口对我们的系统本身是否有意义,这是要按照场景去进行分析的。假如我们的系统只服务一条产品线,并且内部的代码只是针对很具体的场景进行定制化开发,那么引入接口是不会带来任何收益的。
面向接口编程,不用关心具体的实现。如果对应的业务在迭代中发生了修改,所有的逻辑对平台方来说也是完全透明的。
Go被人称道的最多的地方是其接口设计的正交性,模块之间不需要知晓相互的存在,A模块定义接口,B模块实现这个接口就可以。如果接口中没有A模块中定义的数据类型,那B模块中甚至都不用import A。
但这种“正交”性也会给我们带来一些麻烦。当我们接手了一个几十万行的系统时,如果看到定义了很多接口,例如订单流程的接口,我们希望能直接找到这些接口都被哪些对象实现了。但直到现在,这个简单的需求也就只有Goland实现了,并且体验尚可。Visual Studio Code则需要对项目进行全局扫描,来看到底有哪些结构体实现了该接口的全部函数。那些显式实现接口的语言,对于IDE的接口查找来说就友好多了。另一方面,我们看到一个结构体,也希望能够立刻知道这个结构体实现了哪些接口,但也有着和前面提到的相同的问题。
虽有不便,接口带给我们的好处也是不言而喻的:一是依赖反转,这是接口在大多数语言中对软件项目所能产生的影响,在Go的正交接口的设计场景下甚至可以去除依赖;二是由编译器来帮助我们在编译期就能检查到类似“未完全实现接口”这样的错误,如果业务未实现某个流程,但又将其实例作为接口强行来使用的话,会报错。
所以接口也可以认为是一种编译期进行检查的保证类型安全的手段。
在函数中如果有if和switch的话,会使函数的圈复杂度上升,所以有强迫症的同学即使在入口一个函数中有switch,还是想要干掉这个switch,用表驱动的方式来存储我们需要的实例。
当然,表驱动也有缺点,因为需要对输入key计算哈希,在性能敏感的场合,需要多加斟酌。
在大型系统中容错是重要的,能够让系统按百分比,分批次到达最终用户,也是很重要的。虽然当今的互联网公司系统,名义上会说自己上线前都经过了充分慎重严格的测试,但就算它们真得做到了,代码的bug总是在所难免的。即使代码没有bug,分布式服务之间的协作也是可能出现“逻辑”上的非技术问题的。
这时候,灰度发布就显得非常重要了,灰度发布也称为金丝雀发布,互联网系统的灰度发布一般通过两种方式实现:
- 通过分批次部署实现灰度发布
- 通过业务规则进行灰度发布
在对系统的旧功能进行升级迭代时,第一种方式用的比较多。新功能上线时,第二种方式用的比较多。当然,对比较重要的老功能进行较大幅度的修改时,一般也会选择按业务规则来进行发布,因为直接全量开放给所有用户风险实在太大。
假如服务部署在15个实例(可能是物理机,也可能是容器)上,我们把这15个实例分为四组,按照先后顺序,分别有1-2-4-8台机器,保证每次扩展时大概都是二倍的关系。
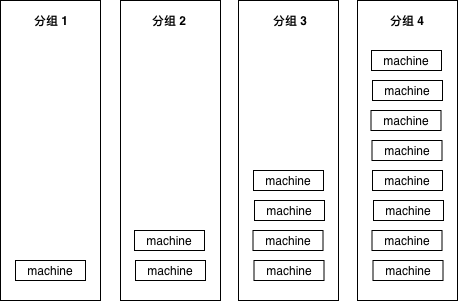
为什么要用2倍?这样能够保证我们不管有多少台机器,都不会把组划分得太多。例如1024台机器,也就只需要1-2-4-8-16-32-64-128-256-512部署十次就可以全部部署完毕。
这样我们上线最开始影响到的用户在整体用户中占的比例也不大,比如1000台机器的服务,我们上线后如果出现问题,也只影响1/1000的用户。如果10组完全平均分,那一上线立刻就会影响1/10的用户,1/10的业务出问题,那可能对于公司来说就已经是一场不可挽回的事故了。
在上线时,最有效的观察手法是查看程序的错误日志,如果较明显的逻辑错误,一般错误日志的滚动速度都会有肉眼可见的增加。这些错误也可以通过metrics一类的系统上报给公司内的监控系统,所以在上线过程中,也可以通过观察监控曲线,来判断是否有异常发生。
如果有异常情况,首先要做的自然就是回滚了。
常见的灰度策略有多种,较为简单的需求,例如我们的策略是要按照千分比来发布,那么我们可以用用户id、手机号、用户设备信息,等等,来生成一个简单的哈希值,然后再求模。
可选规则:常见的灰度发布系统会有下列规则提供选择:
- 按城市发布
- 按概率发布
- 按百分比发布
- 按白名单发布
- 按业务线发布
- 按UA发布(APP、Web、PC)
- 按分发渠道发布
因为和公司的业务相关,所以城市、业务线、UA、分发渠道这些都可能会被直接编码在系统里,不过功能其实大同小异。
按白名单发布比较简单,功能上线时,可能我们希望只有公司内部的员工和测试人员可以访问到新功能,会直接把账号、邮箱写入到白名单,拒绝其它任何账号的访问。
按照城市发布:按白名单、按业务线、按UA、按分发渠道发布,本质上和按城市发布是一样的。
var cityID2Open = map[int]struct{}{}
func init() {
readConfig()
for _, city := range openCities {
cityID2Open[city] = struct{}{}
}
}
func isPassed(cityID int) bool {
if _, ok := cityID2Open[cityID]; ok {
return true
}
return false
}按概率发布:注意初始化种子。
func init() {
rand.Seed(time.Now().UnixNano())
}
// rate 为 0~100
func isPassed(rate int) bool {
if rate >= 100 {
return true
}
if rate > 0 && rand.Int(100) > rate {
return true
}
return false
}求哈希可用的算法非常多,比如md5,crc32,sha1等等,但我们的目的只是为了给这些数据做个映射,并不想要因为计算哈希消耗过多的cpu,所以现在业界使用较多的算法是murmurhash。
Running tool: /usr/local/go/bin/go test -benchmem -run=^$ -coverprofile=/tmp/vscode-gobDPSNI/go-code-cover -bench . github.com/huxiangyu99/advanced-go-programming/ch5web/gatedlaunch/hash
goos: linux
goarch: amd64
pkg: github.com/huxiangyu99/advanced-go-programming/ch5web/gatedlaunch/hash
cpu: Intel(R) Xeon(R) Platinum 8255C CPU @ 2.50GHz
BenchmarkMD5 8362228 145.6 ns/op 0 B/op 0 allocs/op
BenchmarkSHA1 5988250 200.6 ns/op 16 B/op 1 allocs/op
BenchmarkMurmurHash32 60599727 20.40 ns/op 0 B/op 0 allocs/op
BenchmarkMurmurHash64 25020146 45.60 ns/op 16 B/op 1 allocs/op
PASS
coverage: 100.0% of statements
ok github.com/huxiangyu99/advanced-go-programming/ch5web/gatedlaunch/hash 6.038s对于哈希算法来说,除了性能方面的问题,还要考虑哈希后的值是否分布均匀。如果哈希后的值分布不均匀,那也自然就起不到均匀灰度的效果了。
以murmurhash为例,我们先以15810000000开头,造一千万个和手机号类似的数字,然后将计算后的哈希值分十个桶,并观察计数是否均匀:
bucketMap: map[0:998000 1:999862 2:1000388 3:999393 4:1000657 5:1000487 6:999575 7:999594 8:1000520 9:1001524]偏差都在1/100以内,可以接受。