Code for the Paper "IllusionVQA: A Challenging Optical Illusion Dataset for Vision Language Models".
For more details, please refer to the project page: https://illusionvqa.github.io.
🔔 If you have any questions or suggestions, please don't hesitate to let us know. You can post an issue on this repository or mail us directly.
Project Page |
Paper |
🤗 IllusionVQA-Comprehension |
🤗 IllusionVQA-Soft-Localization
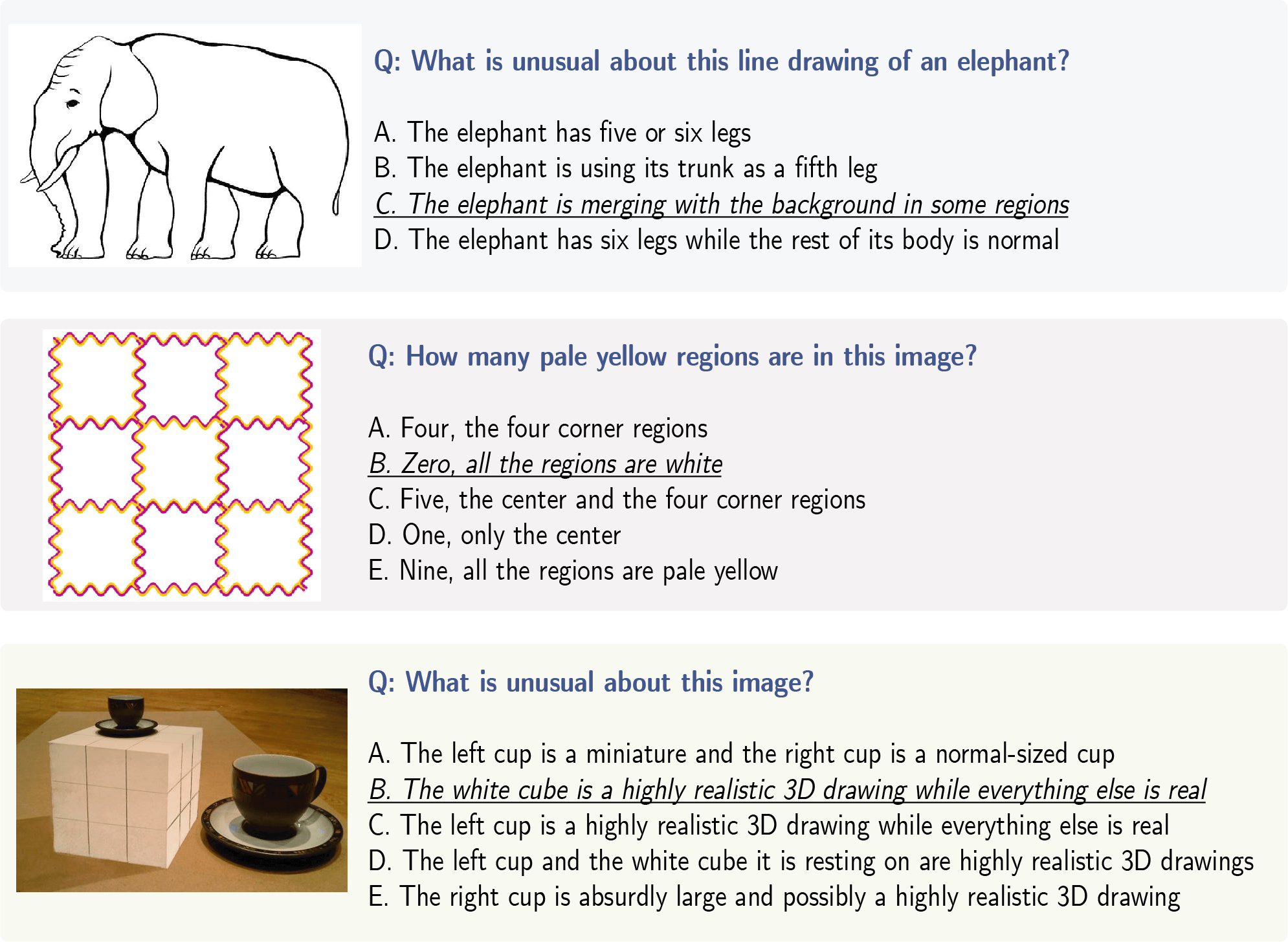
IllusionVQA is a dataset of optical illusions and hard-to-interpret scenes designed to test the capability of Vision Language Models in comprehension and soft localization tasks. GPT4V achieved 62.99% accuracy on comprehension and 49.7% on localization, while humans achieved 91.03% and 100% respectively.
- [2024.08.31] 💥 Gemini-1.5-Pro sets new SOTA on both Comprehension and Soft-Localization! With a significant lead in Comprehension (71% vs. second place 67%). Gemini-1.5-Flash places 7th and 4th respectively.
- [2024.08.16] 💥 Claude 3.5 Sonnet achieves 2nd place on comprehension with 66.44! Learn more at the Anthropic blog.
- [2024.08.16] 💥 OpenAI's GPT-4o achieves new SOTA on IllusionVQA with 67.12% on Comprehension and 53.3% on Soft Localization! Learn more at the OpenAI blog.
- [2024.07.28] 🚀 InternVL2 achieves 45.06% on Comprehension and 28.3% on Soft Localization, scoring the best among open source models. 🎉 Congratulations!
- [2024.07.09] 🌟 Our IllusionVQA paper has been accepted at COLM 2024 (acceptance rate 28.8%)! 🎉 Cheers!
- [2024.05.28] ✨ Our work was featured by Scientific American. Thanks! ✨
- [2024.03.28] 🚀 Our project page is live at https://illusionvqa.github.io.
- [2024.03.27] Our dataset is now accessible at Papers With Code.
- [2024.03.26] Our dataset is now accessible at Huggingface Datasets! 🧠 Comprehension and 🔎 Soft Localization.
- [2024.03.26] Our paper is now accessible at https://arxiv.org/abs/2403.15952.

For the latest results, checkout out the leaderboard in the project page.
| Class | # | 0-shot | 4-shot | Human | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| I-BLIP | LLaVA | Cog | Gemini | GPT4V | Gemini | GPT4V | ||||||
| Impossible Object | 134 | 34.22 | 43.28 | 44.03 | 56.72 | 55.22 | 56.72 | 58.96 | 98.51 | |||
| Real-Scene | 64 | 26.56 | 42.19 | 34.38 | 46.88 | 57.81 | 46.88 | 54.69 | 98.44 | |||
| Size | 46 | 26.09 | 19.57 | 13.04 | 45.65 | 58.70 | 52.17 | 69.57 | 63.04 | |||
| Hidden | 45 | 44.44 | 42.22 | 42.22 | 42.22 | 51.11 | 48.89 | 46.67 | 100 | |||
| Deceptive Design | 37 | 37.84 | 43.24 | 45.95 | 64.86 | 70.27 | 67.56 | 72.97 | 94.59 | |||
| Angle Illusion | 26 | 30.77 | 38.46 | 30.77 | 53.85 | 69.23 | 50 | 84.62 | 84.62 | |||
| Color | 23 | 30.43 | 26.09 | 30.43 | 17.39 | 69.57 | 17.39 | 82.61 | 60.87 | |||
| Edited-Scene | 21 | 42.86 | 61.90 | 42.86 | 66.67 | 71.43 | 66.67 | 80.95 | 100 | |||
| Upside-Down | 7 | 42.86 | 71.43 | 71.43 | 57.14 | 71.43 | 57.14 | 71.43 | 100 | |||
| Pos.-Neg. Space | 7 | 57.41 | 42.86 | 71.43 | 85.71 | 57.14 | 71.43 | 85.71 | 100 | |||
| Circle-Spiral | 6 | 33.33 | 0.00 | 16.67 | 33.33 | 50 | 33.33 | 33.33 | 66.67 | |||
| Miscellaneous | 19 | 36.84 | 42.11 | 42.11 | 52.63 | 42.11 | 57.89 | 42.11 | 89.47 | |||
| Total | 435 | 34.25 | 40 | 38.16 | 51.26 | 58.85 | 52.87 | 62.99 | 91.03 |
New Results [13 July 2024]
| Class | # | 0-shot | 4-shot | Human | |||
|---|---|---|---|---|---|---|---|
| gpt4o | gpt4o | ||||||
| Impossible Object | 134 | 63.43 | 61.94 | 98.51 | |||
| Real-Scene | 64 | 64.06 | 57.81 | 98.44 | |||
| Size | 46 | 45.65 | 93.47 | 63.04 | |||
| Hidden | 45 | 66.67 | 48.89 | 100 | |||
| Deceptive Design | 37 | 72.97 | 78.38 | 94.59 | |||
| Angle Illusion | 26 | 50.00 | 80.77 | 84.62 | |||
| Color | 23 | 52.17 | 78.26 | 60.87 | |||
| Edited-Scene | 21 | 80.95 | 85.71 | 100 | |||
| Upside-Down | 7 | 71.43 | 42.86 | 100 | |||
| Pos.-Neg. Space | 7 | 85.71 | 71.43 | 100 | |||
| Circle-Spiral | 6 | 50.00 | 50.00 | 66.67 | |||
| Miscellaneous | 19 | 52.63 | 52.63 | 89.47 | |||
| Total | 435 | 62.53 | 67.12 | 91.03 |
| VLM | Prompt Type | Accuracy |
|---|---|---|
| InstructBLIP | 0-shot | 24.3 |
| LLaVA-1.5 | 0-shot | 24.8 |
| CogVLM | 0-shot | 28 |
| GPT4V | 0-shot | 40 |
| 4-shot | 46 | |
| 4-shot + CoT | 49.7 | |
| Gemini Pro | 0-shot | 43.5 |
| 4-shot | 41.8 | |
| 4-shot + CoT | 33.9 | |
| Human | 100 |
from datasets import load_dataset
import base64
from openai import OpenAI
import os
os.environ["OPENAI_API_KEY"] = "YOUR_API_KEY"
def encode_image(pil_image):
temp_name = "temp.jpg"
pil_image.save(temp_name)
with open(temp_name, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
def construct_mcq(options, correct_option):
correct_option_letter = None
i = "a"
mcq = ""
for option in options:
if option == correct_option:
correct_option_letter = i
mcq += f"{i}. {option}\n"
i = chr(ord(i) + 1)
mcq = mcq[:-1]
return mcq, correct_option_letter
def add_row(content, data, i, with_answer=False):
mcq, correct_option_letter = construct_mcq(data["options"], data["answer"])
content.append({ "type": "text",
"text": "Image " + str(i) + ": " + data["question"] + "\n" + mcq })
content.append({ "type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{encode_image(data['image'])}",
"detail": "low"}})
if with_answer:
content.append({"type": "text", "text": "Answer {}: ".format(i) + correct_option_letter})
else:
content.append({"type": "text", "text": "Answer {}: ".format(i), })
return content
dataset = load_dataset("csebuetnlp/illusionVQA-Comprehension")
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
content = [{
"type": "text",
"text": "You'll be given an image, an instruction and some choices. You have to select the correct one. Do not explain your reasoning. Answer with the option's letter from the given choices directly. Here are a few examples:",
}]
### Add a few examples
for i, data in enumerate(dataset["train"], 1):
content = add_row(content, data, i, with_answer=True)
content.append({"type": "text", "text": "Now you try it!",})
next_idx = i + 1
### Add the test data
test_data = dataset["test"][0]
content_t = add_row(content.copy(), test_data, next_idx, with_answer=False)
### Get the answer from GPT-4
response = client.chat.completions.create(
model="gpt-4-vision-preview",
messages=[{"role": "user","content": content_t,}],
max_tokens=5,
)
gpt4_answer = response.choices[0].message.content
print(gpt4_answer)This dataset is made available for non-commercial research purposes only under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0). The dataset may not be used for training models. The dataset contains images collected from the internet. While permission has been obtained from some of the images' creators, permission has not yet been received from all creators. If you believe any image in this dataset is used without proper permission and you are the copyright holder, please email Haz Sameen Shahgir to request the removal of the image from the dataset.
The dataset creator makes no representations or warranties regarding the copyright status of the images in the dataset. The dataset creator shall not be held liable for any unauthorized use of copyrighted material that may be contained in the dataset.
You agree to the terms and conditions specified in this license by downloading or using this dataset. If you do not agree with these terms, do not download or use the dataset.

@inproceedings{
shahgir2024illusionvqa,
title={Illusion{VQA}: A Challenging Optical Illusion Dataset for Vision Language Models},
author={Haz Sameen Shahgir and Khondker Salman Sayeed and Abhik Bhattacharjee and Wasi Uddin Ahmad and Yue Dong and Rifat Shahriyar},
booktitle={First Conference on Language Modeling},
year={2024},
url={https://openreview.net/forum?id=7ysaJGs7zY}
}