关于线性回归算法的数学模型,可以参考: 机器学习笔记--多元线性回归
回归,指的是研究一组随机变量(y1,y2,y3,……yn),和另一组变量(x1,x2,x3,……xn)之间关系的统计分析方法。 回归分析是一种数学模型,当函数为参数未知的线性函数时,称为线性回归分析模型;当函数为参数未知的非线性函数时,称为非线性回归分析模型。
- 对于一组数据,(y1,y2,y3,……yn),(x1,x2,x3,……xn),可以先用matplotlib作图,观察两组变量之间的关系。确认两者之间是否存在线性关系。
- 如果存在线性关系,则在已知自变量X,和因变量Y的情况下,可以利用正规方程公式求解,直接得到线性回归模型的参数W。
正规方程求解公式:

正规方程求解过程:

对于常规方程求解,默认所有的样本点都具有同样的权重,但实际,我们预测一个预测点的值的时候,根据预测点与训练集样本点之间的接近程度,赋予样本点不同的权重,这样预测出来的值会更加准确。 思想:通过计算预测点与所有训练集样本点之间的距离,赋予不同样本点不同的权重值(距离越近,样本点的权重越大;距离越远,样本点的权重越小),这样用计算出来的参数W来带入求预测点的值,会更加准确一些。
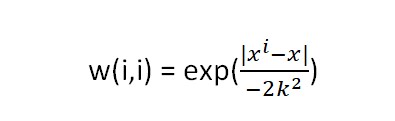

%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import csv
def loadDataSet(fileName):
dataMat = []; labelMat = []
with open(fileName,'r') as f:
reader = csv.reader(f,delimiter = '\t')
for row in reader:
row = [float(x) for x in row]
dataMat.append(row[:2])
labelMat.append(row[2])
return dataMat,labelMat
def plotBestFit(w):
# 把训练集数据用坐标的形式画出来(常规方程求解) 可视化
dataMat,labelMat=loadDataSet('ex0.txt')
dataArr = np.array(dataMat)
n = np.shape(dataArr)[0]
xcord = []
ycord = []
for i in range(n):
xcord.append(dataArr[i,1]); ycord.append(labelMat[i])
fig = plt.figure()
fig.set_figheight(10)
fig.set_figwidth(10)
ax = fig.add_subplot(111)
ax.scatter(xcord, ycord, s=2, c='red', marker='s')
# 把分类边界画出来
x = np.arange(0,1.0,0.01)
y = w[0]+w[1]*x
ax.plot(x,y)
print('常规方程线性回归求解:')
plt.show()
def plotBestFit_lwlr(X,Y):
# 利用局部加权线性回归求解 可视化
dataMat,labelMat=loadDataSet('ex0.txt')
dataArr = np.array(dataMat)
n = np.shape(dataArr)[0]
xcord = []
ycord = []
for i in range(n):
xcord.append(dataArr[i,1]); ycord.append(labelMat[i])
fig = plt.figure()
fig.set_figheight(10)
fig.set_figwidth(10)
ax = fig.add_subplot(111)
ax.scatter(xcord, ycord, s=2, c='red', marker='s')
# 利用局部加权线性回归求解
Y_lwlr = get_Y_lwlr(X,Y)
# X数组从小到大排序
sort_index = X[:,1].argsort(0)
X_sort = X[sort_index][:,1]
ax.plot(X_sort, Y[sort_index])
print('局部加权线性回归求解:')
plt.show()
def get_w(X,Y):
# 用正规方程求解,知道X,Y,求参数w w=(X.T*X)(-1)*X.T*Y
X_Xt_I = np.linalg.inv(np.dot(X.T,X))
w = np.dot(np.dot(X_Xt_I,X.T),Y)
return w
def get_w_lwlr(X,Y,x_test):
m = X.shape[0]
weight = np.eye(m)
for j in range(m):
# 对于预测点,根据预测点与每一个样本点之间的接近程度,更新每一个样本点的权重
diff = x_test-X[j,:]
weight[j,j] = np.exp(np.dot(diff.T,diff)/(-2*0.05**2))
# 局部加权之后,重新计算得到新的参数w_lwlr
X_Xt_I_lwlr = np.linalg.inv(np.dot(np.dot(X.T,weight),X))
w_lwlr = np.dot(np.dot(np.dot(X_Xt_I_lwlr,X.T),weight),Y)
return w_lwlr
def get_Y_lwlr(X,Y):
Y_lwlr = []
# 对所有训练实例进行局部加权,求得局部加权后对应的Y值
m = X.shape[0]
weight = np.eye(m)
for j in range(m):
diff = X[j,:]-X[j,:]
weight[j,j] = np.exp(np.dot(diff.T,diff)/(-2*0.05**2))
X_Xt_I_lwlr = np.linalg.inv(np.dot(np.dot(X.T,weight),X))
w_lwlr = np.dot(np.dot(np.dot(X_Xt_I_lwlr,X.T),weight),Y)
for j in range(m):
y_lwlr = w_lwlr[0]+w_lwlr[1]*X[j,1]
Y_lwlr.append(y_lwlr)
return np.array(Y_lwlr)
def main():
# 读取txt文件,获取数据集
dataMat,labelMat = loadDataSet('ex0.txt')
# 把数据集转换成array数组
X = np.array(dataMat)
Y = np.array(labelMat).T
# 用正规方程求解,知道X,Y,求参数W
w = get_w(X,Y)
# 正规方程求解可视化
plotBestFit(w)
# 局部加权后求解可视化
plotBestFit_lwlr(X,Y)
# 预测点 [1.000000 0.995731]
x_test = np.array([1.000000,0.378887])
# 利用局部加权之后,求得参数W
w_lwlr = get_w_lwlr(X,Y,x_test)
print('正规方程求解参数W:',w)
print('局部加权后求解参数W:',w_lwlr)
print('y的真实值:3.52617')
y = w[0]+w[1]*0.378887
print('常规方程求解w后,预测值:',y)
y_lwlr = w_lwlr[0]+w_lwlr[1]*0.378887
print('局部加权线性回归求解w后,预测值:',y_lwlr)
if __name__ == '__main__':
main()

%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
import csv
def loadDataSet(fileName):
dataMat = []; labelMat = []
with open(fileName,'r') as f:
reader = csv.reader(f,delimiter = '\t')
for row in reader:
row = [float(x) for x in row]
dataMat.append(row[:-1])
labelMat.append(row[-1])
return dataMat,labelMat
def get_w(X,Y):
# 用正规方程求解,知道X,Y,求参数w w=(X.T*X)(-1)*X.T*Y
X_Xt_I = np.linalg.inv(np.dot(X.T,X))
w = np.dot(np.dot(X_Xt_I,X.T),Y)
return w
def get_w_lwlr(X,Y,x_test):
m = X.shape[0]
weight = np.eye(m)
for j in range(m):
# 对于预测点,根据预测点与每一个样本点之间的接近程度,更新每一个样本点的权重
diff = x_test-X[j,:]
weight[j,j] = np.exp(np.dot(diff.T,diff)/(-2*0.01**2))
# 局部加权之后,重新计算得到新的参数w_lwlr
X_Xt_I_lwlr = np.linalg.inv(np.dot(np.dot(X.T,weight),X))
w_lwlr = np.dot(np.dot(np.dot(X_Xt_I_lwlr,X.T),weight),Y)
return w_lwlr
def main():
dataMat,labelMat = loadDataSet('abalone.txt')
X = np.array(dataMat)
Y = np.array(labelMat).T
# 测试数据
test_x1 = [-1,0.53,0.42,0.135,0.677,0.2565,0.1415,0.21]
# 用正规方程求解,知道X,Y,求参数W
w = get_w(X,Y)
print('正规方程求解参数:',w)
w_lwlr = get_w_lwlr(X,Y,test_x1)
print('局部加权后求解参数:',w_lwlr)
print('测试鲍鱼的真实年龄:9')
y1 = np.dot(np.array(test_x1),w.T)
print('正规方程求解预测值:',y1)
y2 = np.dot(np.array(test_x1),w_lwlr.T)
print('局部加权后求解预测值',y2)
if __name__ == '__main__':
main()
