If your GraphQL schema has a nullable field, dillonkearns/elm-graphql will generate a corresponding Maybe for that field in the response.
The best way to get rid of these Maybes is to make the fields non-nullable (for example, turn a string field into a string! field or a [int] into a [int!]!).
If you are unable to change your schema and make the nullable fields non-nullable, you can use Graphql.SelectionSet.nonNullOrFail. Be aware that the entire response will fail to decode if you do get a null back in a field where you used nonNullOrFail.
Again, ideally you could change your schema (e.g. [string]! becomes [string!]!). If that's not possible, take a look at the Graphql.SelectionSet.nonNullElementsOrFail function to turn a List (Maybe something) into a List something.
Take a look at the section about this from the official GraphQL docs.
There are two placeholder types in the SelectionSet type (known as "type variables" in Elm terminology, but you can think of them as generics, too).
type SelectionSet decodesTo scopeThe first type is what the type will decode to. For example, if it were a SelectionSet String <...>, then that decoder would give you a String value. You can combine SelectionSets together using things like SelectionSet.map2, so you could take a SelectionSet that decodes into an Int, and one that decodes into a String, and turn it into a record with an Int and a String, for example.
The second type variable, scope, is what prevents you from grabbing a field that doesn't exist in a certain context. Let's look at the example with a raw GraphQL query:
query {
currentDateString
currentUser {
firstName
lastName
}
}What's to keep us from building up a query like
query {
firstName # this shouldn't be allowed!
}
Well, that's what scope is for. So in this example, we would have a type that looks like this:
firstName : SelectionSet String Userand in another module
currentDateString : SelectionSet String RootQuerySo this allows us to grab currentDateString in a top-level query. But to get firstName, we need to use it within the context of selecting fields from a GraphQL User Object.
Why do I get an error when I don't provide an Optional Argument? According to the schema it's optional.
This is very common, if you look at your schema you will probably find that the optional argument is marked as nullable (i.e. it doesn't end with a !). And in GraphQL, a nullable argument is exactly what an optional argument is, see http://spec.graphql.org/June2018/#sec-Required-Arguments
Arguments can be required. An argument is required if the argument type is non‐null and does not have a default value. Otherwise, the argument is optional.
But even though the schema lists the argument as optional (i.e. nullable), it's common to throw a runtime error and say that it's invalid. A common reason for this is that you must pass in "one of the following...", so no individual argument is required, but if you don't provide one it will throw a runtime error. Here's an example from the Github API (you can reporduce it yourself by running this query in the Github Explorer):
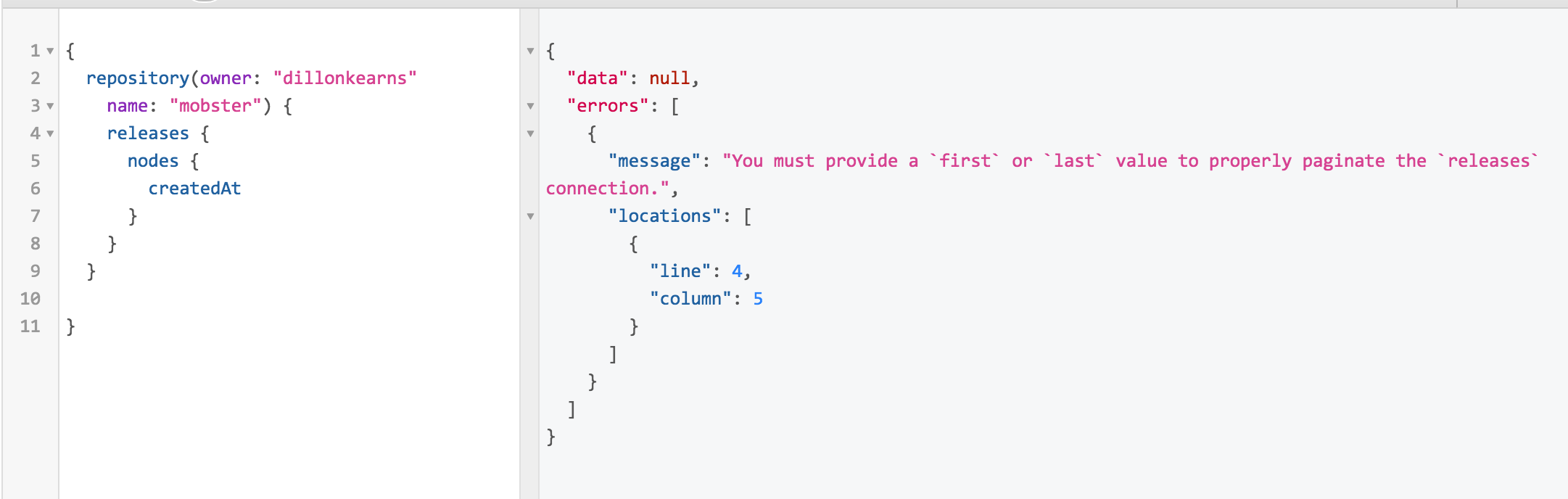
Why is the OptionalArgument union type used instead of Maybe?
An optional argument can be either present, absent, or null, so using a Maybe does not fully capture the GraphQL concept of an optional argument. For example, you could have a mutation that deletes an entry if a null argument is provided, or does nothing if the argument is absent. See The official GraphQL spec section on null for details.
My recommendation is to keep them in their own module. I have an example of this with ElmReposRequest.elm. That query module is consumed by the Main.elm module.
Some GraphQL names are invalid in Elm, and others are not idiomatic and would sound awkard in the context of Elm code.
For example, it is conventional to name a Union's values with all caps in GraphQL, like a union Episode with values NEWHOPE, EMPIRE, JEDI. dillonkearns/elm-graphql will generate the following union type type Episode = Empire | Jedi | Newhope. If you follow the GraphQL naming conventions, dillonkearns/elm-graphql will generate nice names that follow Elm naming conventions.
Elm also has to avoid reserved words in the language like, so it would convert a field name like module or import into module_ and import_ (See #41 for more in-depth discussion of this). If you want more details on the normalization behavior you can take a look at the normalization test suite.
What if you have two names that dillonkearns/elm-graphql normalizes to the same thing, like a field called user and User (which would both turn into user? This is possible, but indicates that you are not following GraphQL conventions. Consider using a different naming convention. If you have a compelling reason for your naming, open an issue so we can discuss the normalization strategy.
Take a look at the dillonkearns/elm-graphql Elm 0.19 upgrade guide.
Yes, you can read about why the name changed here.
You may notice that "Show Aliases" is unchecked by default in the demos in the examples folder.
Aliases are just a tool for telling GraphQL what field to return your data back under
in the JSON response. But with dillonkearns/elm-graphql, you're not dealing with
JSON directly. You just use map2 or SelectionSet.succeed or SelectionSet.with functions
to build up data structures. The JSON response details are all handled under the hood by
the library.
Sometimes GraphQL requires you to use aliases to make sure you don't make ambiguous
queries. For example, if you make a request asking for avatar(size: SMALL) and
avatar(size: LARGE) in the same request, then you will need to use an alias
since they can't both come back under the JSON field avatar with more than
one avatar data in the response.
We hide aliases by default in this demos to reduce noise. But note that these request may be invalid without the aliases, so check "Show Aliases" if you would like to copy-paste the queries and execute them yourself.
You can read more about how aliases are used under the hood in this blog
post
about the dillonkearns/elm-graphql internals.
dillonkearns/elm-graphql deserializes custom scalars into Strings because scalars are a blindspot in GraphQL. At the moment, there's no way to express what underlying type you use to represent your Scalars in your GraphQL Schema. This is just an area of GraphQL that isn't type-safe yet for some reason. But there is a proposal to allow you (but not require you) to specify the base primitive you use to represent your scalars. See this issue for more on that pending GraphQL Spec change: #39
As for the type wrappers, like type Numeric = Numeric String, the reason for that type wrapper is that it allows you to make certain assumptions given a particular Scalar type. If it was just a raw String, then the compiler wouldn't be able to help ensure that if you write a function to transform a particular scalar, you only use it for that scalar and not any other string by mistake.
There are two ways to turn your Custom Scalars into the data types you want.
-
Use the Custom Scalar Decoders feature of
dillonkearns/elm-graphql. Look at this example and mini-tutorial to see how and what the resulting code looks like. There is also an 11-minute demo and tutorial video on setting up and using Custom Scalar Codecs. -
Or you can unwrap the default scalar wrapper type using
SelectionSet.map. The result looks something like this:
Query.someNumericField
|> SelectionSet.map (\(Api.Scalar.Numeric rawNumeric) -> String.toFloat rawNumeric |> Maybe.withDefault 0)elm/http@2.0.0 introduced a change to the Http.Error type where BadStatus went from containing the status code and the message to only containing the status code. Some users need that bit of data (the message for a bad status response). In order to prevent losing information, we needed to define a custom HttpError type for elm-graphql. See the full discussion on this issue.
You can use withSimpleHttpError to turn the data type from a Graphql.Http.HttpError into a standard Http.Error. See the example in the docs for withSimpleHttpError for details on how to use that function.
Having the user define their own types is a deliberate design decision.
My view on that is that grabbing primitives from your GraphQL server should just be something you take for granted that you can't get wrong because they're defined for you. But the way you piece those primitives together is very specific to the domain. You can even use the same GraphQL Objects to build different types in different contexts.
Having elm-graphql make decisions for the user about those things would mean that:
- you have to learn what those opinions are as a user, instead of just explicitly seeing how things are wired up
- if you want to do something that's not what's generated by the framework, now there's the complexity of unwinding what the framework gives you
- the framework building this means that the types are defined for you, but often in a domain you want to share your types with the rest of your domain. It also discourages using nice custom types with logic for your domain
I talk a little bit about some of those ideas in here:
The primary goal of elm-graphql is to give you type-safe building blocks, and to let the user piece those building blocks together. It's not meant to handle the high-level domain logic of the app because it doesn't know about that so it can't handle that well. So its job is to make the low-level primitives as type-safe as possible, and give the user the tools to build up those nice high-level pieces.
Here's an example of a module that illustrates how I envision people using those low-level building blocks: https://github.com/IncrementalElm/elm-graphql-shopping-cart/blob/master/client/src/Product.elm
It also fits with Elm's core philosophy that "There are worse things than being explicit".
One thing that I've learned from the Elm community is that the things that seem like they are making code hard to work with might not actually be the bottleneck to maintainable code. Often languages give you implicit magic, and it seems like it "cleans up the code" a lot. Making things clean, intuitive, and simple is extremely valuable. But explicitness is also extremely valuable, and sometimes what looks like simple code is actually magic that is hard to understand and maintain (and not simple at all really!).
I feel that way about explicitly defining your types for use with elm-graphql. It's work, but it's explicit work, and I don't think that's the bottleneck to maintaining code.
Evan talks about his reasons for not automatically generating JSON decoders in Elm like Haskell does, and I think it's somewhat analagous to my thinking on why elm-graphql shouldn't automatically generate types based on your schema: https://gist.github.com/evancz/1c5f2cf34939336ecb79b97bb89d9da6#gistcomment-2606737
Elm JSON Decoders have Json.Decode.lazy to help decode recursive data structures like comments. There is no equivalent of lazy in elm-graphql because the GraphQL spec chose not to allow recursive selection sets since they would have an unbounded depth.
Instead, the typical approach to retrieving recursive data structures in GraphQL is to manually define a selection set that recurses a specific finite number of times (for example get 10 levels of nested comments, or 20 levels deep), and re-use that when needed.
What do I do about errors and warnings from static analysis and linting tools like elm-review and VS Code?
Tools like elm-review recommend ignoring errors within generated directories.
For elm-review, you can ignore your generated directories using Review.Rule.ignoreErrorsForDirectories.