Rethinking atrous convolution for semantic image segmentation
Official Repo
Code Snippet
In this work, we revisit atrous convolution, a powerful tool to explicitly adjust filter's field-of-view as well as control the resolution of feature responses computed by Deep Convolutional Neural Networks, in the application of semantic image segmentation. To handle the problem of segmenting objects at multiple scales, we design modules which employ atrous convolution in cascade or in parallel to capture multi-scale context by adopting multiple atrous rates. Furthermore, we propose to augment our previously proposed Atrous Spatial Pyramid Pooling module, which probes convolutional features at multiple scales, with image-level features encoding global context and further boost performance. We also elaborate on implementation details and share our experience on training our system. The proposed `DeepLabv3' system significantly improves over our previous DeepLab versions without DenseCRF post-processing and attains comparable performance with other state-of-art models on the PASCAL VOC 2012 semantic image segmentation benchmark.
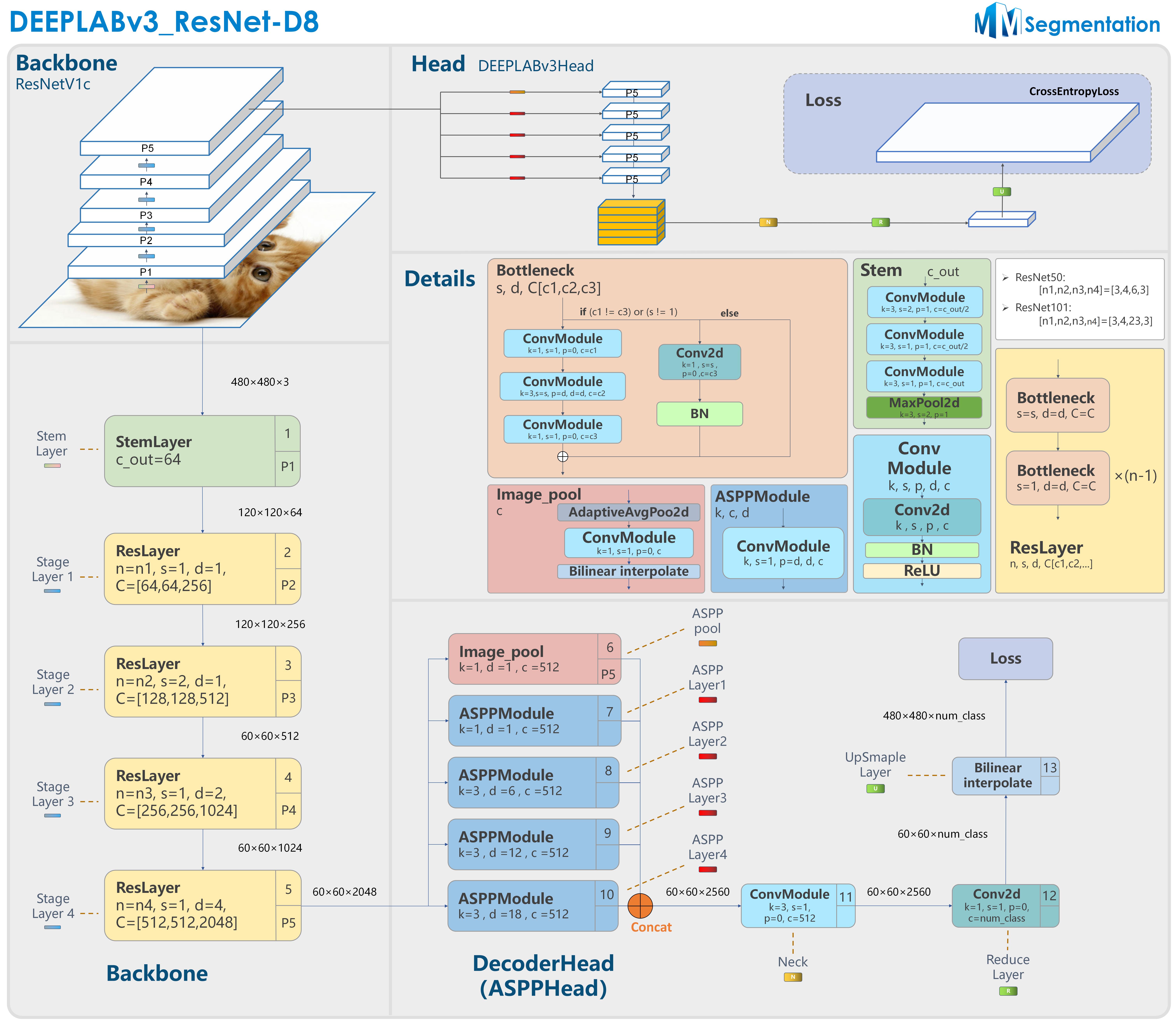
DEEPLABv3_ResNet-D8 model structure
| Method |
Backbone |
Crop Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
Device |
mIoU |
mIoU(ms+flip) |
config |
download |
| DeepLabV3 |
R-50-D8 |
512x1024 |
40000 |
6.1 |
2.57 |
V100 |
79.09 |
80.45 |
config |
model | log |
| DeepLabV3 |
R-101-D8 |
512x1024 |
40000 |
9.6 |
1.92 |
V100 |
77.12 |
79.61 |
config |
model | log |
| DeepLabV3 |
R-50-D8 |
769x769 |
40000 |
6.9 |
1.11 |
V100 |
78.58 |
79.89 |
config |
model | log |
| DeepLabV3 |
R-101-D8 |
769x769 |
40000 |
10.9 |
0.83 |
V100 |
79.27 |
80.11 |
config |
model | log |
| DeepLabV3 |
R-18-D8 |
512x1024 |
80000 |
1.7 |
13.78 |
V100 |
76.70 |
78.27 |
config |
model | log |
| DeepLabV3 |
R-50-D8 |
512x1024 |
80000 |
- |
- |
V100 |
79.32 |
80.57 |
config |
model | log |
| DeepLabV3 |
R-101-D8 |
512x1024 |
80000 |
- |
- |
V100 |
80.20 |
81.21 |
config |
model | log |
| DeepLabV3 (FP16) |
R-101-D8 |
512x1024 |
80000 |
5.75 |
3.86 |
V100 |
80.48 |
- |
config |
model | log |
| DeepLabV3 |
R-18-D8 |
769x769 |
80000 |
1.9 |
5.55 |
V100 |
76.60 |
78.26 |
config |
model | log |
| DeepLabV3 |
R-50-D8 |
769x769 |
80000 |
- |
- |
V100 |
79.89 |
81.06 |
config |
model | log |
| DeepLabV3 |
R-101-D8 |
769x769 |
80000 |
- |
- |
V100 |
79.67 |
80.81 |
config |
model | log |
| DeepLabV3 |
R-101-D16-MG124 |
512x1024 |
40000 |
4.7 |
6.96 |
V100 |
76.71 |
78.63 |
config |
model | log |
| DeepLabV3 |
R-101-D16-MG124 |
512x1024 |
80000 |
- |
- |
V100 |
78.36 |
79.84 |
config |
model | log |
| DeepLabV3 |
R-18b-D8 |
512x1024 |
80000 |
1.6 |
13.93 |
V100 |
76.26 |
77.88 |
config |
model | log |
| DeepLabV3 |
R-50b-D8 |
512x1024 |
80000 |
6.0 |
2.74 |
V100 |
79.63 |
80.98 |
config |
model | log |
| DeepLabV3 |
R-101b-D8 |
512x1024 |
80000 |
9.5 |
1.81 |
V100 |
80.01 |
81.21 |
config |
model | log |
| DeepLabV3 |
R-18b-D8 |
769x769 |
80000 |
1.8 |
5.79 |
V100 |
75.63 |
77.51 |
config |
model | log |
| DeepLabV3 |
R-50b-D8 |
769x769 |
80000 |
6.8 |
1.16 |
V100 |
78.80 |
80.27 |
config |
model | log |
| DeepLabV3 |
R-101b-D8 |
769x769 |
80000 |
10.7 |
0.82 |
V100 |
79.41 |
80.73 |
config |
model | log |
| Method |
Backbone |
Crop Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
Device |
mIoU |
mIoU(ms+flip) |
config |
download |
| DeepLabV3 |
R-50-D8 |
512x512 |
80000 |
8.9 |
14.76 |
V100 |
42.42 |
43.28 |
config |
model | log |
| DeepLabV3 |
R-101-D8 |
512x512 |
80000 |
12.4 |
10.14 |
V100 |
44.08 |
45.19 |
config |
model | log |
| DeepLabV3 |
R-50-D8 |
512x512 |
160000 |
- |
- |
V100 |
42.66 |
44.09 |
config |
model | log |
| DeepLabV3 |
R-101-D8 |
512x512 |
160000 |
- |
- |
V100 |
45.00 |
46.66 |
config |
model | log |
| Method |
Backbone |
Crop Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
Device |
mIoU |
mIoU(ms+flip) |
config |
download |
| DeepLabV3 |
R-50-D8 |
512x512 |
20000 |
6.1 |
13.88 |
V100 |
76.17 |
77.42 |
config |
model | log |
| DeepLabV3 |
R-101-D8 |
512x512 |
20000 |
9.6 |
9.81 |
V100 |
78.70 |
79.95 |
config |
model | log |
| DeepLabV3 |
R-50-D8 |
512x512 |
40000 |
- |
- |
V100 |
77.68 |
78.78 |
config |
model | log |
| DeepLabV3 |
R-101-D8 |
512x512 |
40000 |
- |
- |
V100 |
77.92 |
79.18 |
config |
model | log |
| Method |
Backbone |
Crop Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
Device |
mIoU |
mIoU(ms+flip) |
config |
download |
| DeepLabV3 |
R-101-D8 |
480x480 |
40000 |
9.2 |
7.09 |
V100 |
46.55 |
47.81 |
config |
model | log |
| DeepLabV3 |
R-101-D8 |
480x480 |
80000 |
- |
- |
V100 |
46.42 |
47.53 |
config |
model | log |
| Method |
Backbone |
Crop Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
Device |
mIoU |
mIoU(ms+flip) |
config |
download |
| DeepLabV3 |
R-101-D8 |
480x480 |
40000 |
- |
- |
V100 |
52.61 |
54.28 |
config |
model | log |
| DeepLabV3 |
R-101-D8 |
480x480 |
80000 |
- |
- |
V100 |
52.46 |
54.09 |
config |
model | log |
| Method |
Backbone |
Crop Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
Device |
mIoU |
mIoU(ms+flip) |
config |
download |
| DeepLabV3 |
R-50-D8 |
512x512 |
20000 |
9.6 |
10.8 |
V100 |
34.66 |
36.08 |
config |
model | log |
| DeepLabV3 |
R-101-D8 |
512x512 |
20000 |
13.2 |
8.7 |
V100 |
37.30 |
38.42 |
config |
model | log |
| DeepLabV3 |
R-50-D8 |
512x512 |
40000 |
- |
- |
V100 |
35.73 |
37.09 |
config |
model | log |
| DeepLabV3 |
R-101-D8 |
512x512 |
40000 |
- |
- |
V100 |
37.81 |
38.80 |
config |
model | log |
| Method |
Backbone |
Crop Size |
Lr schd |
Mem (GB) |
Inf time (fps) |
Device |
mIoU |
mIoU(ms+flip) |
config |
download |
| DeepLabV3 |
R-50-D8 |
512x512 |
80000 |
9.6 |
10.8 |
V100 |
39.38 |
40.03 |
config |
model | log |
| DeepLabV3 |
R-101-D8 |
512x512 |
80000 |
13.2 |
8.7 |
V100 |
40.87 |
41.50 |
config |
model | log |
| DeepLabV3 |
R-50-D8 |
512x512 |
160000 |
- |
- |
V100 |
41.09 |
41.69 |
config |
model | log |
| DeepLabV3 |
R-101-D8 |
512x512 |
160000 |
- |
- |
V100 |
41.82 |
42.49 |
config |
model | log |
| DeepLabV3 |
R-50-D8 |
512x512 |
320000 |
- |
- |
V100 |
41.37 |
42.22 |
config |
model | log |
| DeepLabV3 |
R-101-D8 |
512x512 |
320000 |
- |
- |
V100 |
42.61 |
43.42 |
config |
model | log |
Note:
D-8 here corresponding to the output stride 8 setting for DeepLab series.FP16 means Mixed Precision (FP16) is adopted in training.
@article{chen2017rethinking,
title={Rethinking atrous convolution for semantic image segmentation},
author={Chen, Liang-Chieh and Papandreou, George and Schroff, Florian and Adam, Hartwig},
journal={arXiv preprint arXiv:1706.05587},
year={2017}
}