Forgo benchmark results #46
Comments
|
This is fantastic! I don't have any suggestions right now, but I'll look at it this week/weekend. |
|
I'll devote some energy this weekend to this. |
|
The benchmarks PR has been merged, and we have semi-official results, pending I guess whenever they run the whole suite again.
|

|
This is fantastic stuff! |
|
Working on the Performance (section 1 under Keyed Results). At the same time, good to know that we're doing well in some areas (Startup Metrics - section 2 under Keyed Results). There might also be a leak somewhere, because we start off well in Memory Allocation (section 3) but then drop dramatically. |
|
I spent some time on this today, but unfortunately haven't been able to improve things. However, it looks like findReplacementCandidateForComponent() is what's killing performance. I'll investigate more. |
|
I think I know the issue.
We should be able to fix this by adding a Map on the parent to handle key lookup. But it's also a tricky change; hence I'd like to do this after we merge the CRU implementation. There is another low hanging fruit.
|
Sweet! That makes a lot of sense.
The perf boost from that would be nice, and I think the async render would be appropriate for most use cases (basically everything but unit tests, where you want to immediately make assertions when a render completes). Were you planning to just async-ify the call to the synchronous If we do the maximal version of this idea, we could eliminate all the DOM-walking logic from forgo-state, which in turn makes a hypothetical forgo-mobx trivial to implement. |
My initial thought was that most high frequency rerenders happen on the same element, or at the same level of nesting. For example, a list of stock tickers. And that the chances of parent and child being involved in high frequency rerenders is low. But I could be wrong.
What I was planning to do is to sort of "debounce" rerenders (within the same 1/60 * seconds) on the same element. I tried it yesterday, it's a fairly minor change. Currently rerender() and component.update() return a value to the caller, which we can't in async mode. rerenderAsync() could be a new function which internally calls rerender asynchronously - it'll have to return void. |
Sounds like a reasonable assumption to me. And if we ever need a more elaborate version, I don't think it would require any API changes, so doing the simple version now works fine. That design sounds good. I wonder if it makes sense to make the async render the default in 4.0? With |
The sync version returns the nodes affected as a return value, which we can't anymore. However, it's also not quite useful; so perhaps we should default to async. |
|
Now that #59 is merged, I'm gonna try to fix the performance issues on top of the new code. |
|
The way to find an element quickly based on a key is to have a Map from the key to the element index (under parent.childNodes). However, these indexes can change since we allow manual DOM manipulation. I can't think of another way to avoid the expensive loops we have now. What can we do here - impose restrictions on manual DOM modifications? |
|
What if we use the index as a starting point? Look up where we know the node used to live, and if it's not there, use the map to grab the index for the node that is there. That tells you whether the manual changes added or removed nodes before the target node. Use that to walk the siblings either forward or backward until you find the node again. It'll be a perf hit if you're doing manual DOM inserts, but for most situations apps will still get the boost. And even with manual changes, perf will be boosted from being linear to the number of nodes, to being linear with the number of manual changes. |
|
If we had 10 manually inserted nodes initially, and we pulled 5 from it (leaving 5) - we'd have to search backwards rather than forwards. If there are 10k nodes forwards, we'll only get to the backwards search after we loop 10k times. Perhaps if we don't find the node via the Map, disable the optimization for childNodes under that parent? |
|
Or maybe I could walk +1, -1, +2, -2, +3, -3 ... The bookkeeping is already a bit tricky; I don't think I'll be able to complete it today. ETA looks like next weekend unfortunately. |
No problem
Ahhh, I see. If our incorrect map value points to a managed node, we know what direction to look, but if it points to an unmanaged node we have no idea. Let me think on this. I wonder what's the performance cost of having a |
Even if it points to a managed node, we can't be sure right? The actual target node could be ahead (for manual insertions) or behind (when previously inserted manual nodes are deleted) - relative to the index stored against a key. |
|
When we check the DOM we'll know two facts: the last known index of the item we're holding, and the last known index of the item we actually found, if it's a managed node (or at least we could get it, I think? If we stick the key on a property on each element). If the found node used to be higher-indexed than it is, we know there were deletions in the list ahead of our target node, so we scan backwards. And vice versa. Or we could just say the algo is best-effort and unmanaged nodes implicitly opt out of it. If the node isn't right where we expect, fall back to scanning the whole sibling set. That might be okay - my thought is the dominant use case for unmanaged nodes is handing off renders to D3 or ApexCharts or something - cases where you make a |
Yep - I think this is the way to go. We'd over-complicate the algorithm otherwise, for what might be a relatively less common use case. And the manual DOM nodes are going to work anyway; they'd just be a little slower. |
|
Sorry, this is still WIP - but I think I'm close. |
|
Sorry, this isn't done yet - just wanted to give an update here. I had done a part of this work a while back, but it's a bit outdated now and wouldn't merge so easily. It touches a large part of the codebase; so maybe I'll start afresh. |
|
I spent the last couple of days on this and haven't made progress. This is a somewhat hard problem, and we can only optimize for the most common type of usage; and there are several best case vs worst case tradeoffs. The easiest solution might look like putting the key and node in a Map<string, Node> defined on the parent element. function MyComponent() {
return {
render: () => {
return (
<tr>
<SomeComp key="1">
<RowComponent key="1" />
<RowComponent key="2" />
<RowComponent key="10000" />
</SomeComp>
<SomeComp key="2">
<RowComponent key="1" />
<RowComponent key="2" />
</SomeComp>
</tr>
);
},
};
}In addition, Child can have a Child itself as a child element. So a simple key based mapping is not going to suffice. I think the best approach would be to optimize for the most common use case, in which the map is constructed on the key of the top level parent (for clarity, top level parent in the previous example is SomeComp, and in the following example is RowComponent). If a unique key isn't defined on the top level parent, we fall back to the current, slower mode of searching for replacement nodes (looping through all child nodes). Here's an example where performance optimization can kick in: function MyComponent() {
return {
render: () => {
return (
<tr>
<RowComponent key="1" />
<RowComponent key="2" />
<RowComponent key="10000" />
</tr>
);
},
};
}Performance sensitive code should be encouraged to do this. It will work for the code in the perf test suite as well (without needing changes). |
|
Ah, no wait. This approach has issues too. When a new keyed component needs to be inserted (which is not in the map), the fallback will always run, and that's expensive. |
|
I'm going to see if I can figure out how hyperapp is handling this; they're much faster than Forgo on the benchmark, and their source code is small enough that it should be practical to identify what they're doing right. |
|
I've been diving into this a bit, just haven't been able to focus on it. |
|
I haven't been able to spent time on this in the last two weeks. I doubt if there's a simple solution to this - we'll have to figure out how to directly find a keyed element via a map. Going to have another go at this today. Some of the complexity is that we need to track deleted nodes we well, and key="N" might be found among deletedNodes. I kinda know what to do and it's not too difficult to explain, it's just a tricky edit which affects a lot of different areas. Of course, if you can think of a simpler way to do this - something out of the box - we should definitely explore that as well. Maybe I'm on the wrong track here. |
|
So far I don't have a better proposal. I figure this must be solvable, since most frameworks achieve better performance on large lists than Forgo. I'm going to stay on this until one of us cracks it, since my app has reached the point where the perf hit is noticeable. I've just got to find the time to figure out how other frameworks are handling it. |
|
I realized I was spending too much time trying to interpret Hyperapp's uncommented, dense code, so I turned to see what Mithril does instead. Turns out Mithril describes their algorithm in plain language.. Does that look like something we can make use of? It looks like the key map idea is solid (both Mithril and Hyperapp use it), it's just a question of the details. Mithril's algo tosses some optimizations on top of it. Hyperapp solves the what-level-is-the-key-at problem by recursing its patch algorithm for every DOM parent node (as opposed to us trying to do it for a whole component at once). I think maybe Mithril does this too, but I haven't confirmed that. |
|
Thank you, great find and it sort of validates the approach. We have more bookkeeping to do. I have it half-way working, but it's buggy. Will need 2 whole days to work on it, but I'm away till Tuesday. I might only work on it on the weekend of 28th Oct. |
|
I went back to the drawing board and started from scratch. Made decent progess so far. However, one puzzle is how we should handle non-forgo/unmanaged nodes. I'm trying to map element keys to indexes in the childNode collection, but that won't work if there are unmanaged nodes added/removed. |
|
One limitation with the approach I'm attempting is that fast searches only work if the key is on the outermost component. For example this works: const component = (
<div>
<SomeComp key="1">
<p>Hello</p>
</SomeComp>
<SomeComp key="2">
<p>Hello</p>
</SomeComp>
</div>
);But this will fall back to our slower existing search algo: const component = (
<div>
<SomeComp>
<ChildComp key="1">
<p>Hello</p>
</ChildComp>
<ChildComp key="2">
<p>Hello</p>
</ChildComp>
</SomeComp>
</div>
);This will fall back as well: const component = (
<div>
<SomeComp>
<ChildComp key="1">
<p>Hello</p>
</ChildComp>
<SomeComp>
<SomeComp>
<ChildComp key="2">
<p>Hello</p>
</ChildComp>
<SomeComp>
</div>
); |
|
Limiting fast searches to when keys are defined on the outermost component doesn't seem to be problematic - that's what most people do, and it seems reasonable. The larger problem is that the approach falls apart with injected unmanaged nodes. We'll have to discuss what to do there. |
I disagree about this assumption. It's unintuitive behavior, and I don't think it's common enough to consider it the dominant case. As an example, both places my app renders large lists resemble your second example. They look like this: return (
<li>
<details>
<ul>
<li key="abc"></li>
<li key="def"></li>
</ul>
</details>
</li>
);My experience with various SPA frameworks is that having keyed items at various depths is commonplace. Is the third example supposed to be valid? The <div>
<SomeComp>
<ChildComp key="1">
<p>Hello</p>
</ChildComp>
<SomeComp>
<SomeComp>
<ChildComp key="1">
<p>Hello</p>
</ChildComp>
</SomeComp>
<SomeComp>
<ChildComp key="1">
<p>Hello</p>
</ChildComp>
</SomeComp>
</div>I thought frameworks typically only scoped keys to their nearest parent, rather than to the whole component? If they're in the same key pool, that would be a problem when a component renders multiple copies of the same list of items (e.g., currently-selected items + a dropdown)
We previously discussed opting out of the fast path if an element had any unmanaged nodes underneath it. Is that idea not working out? I'm also wondering whether we should handle managed + unmanaged nodes under the same parent at all. All of the big use cases I know for unmanaged nodes are shaped like "pass HighCharts a I'm not sure when you'd want manually-inserted nodes in the middle of Forgo-managed nodes, and if you do, I'll bet If mixing managed + unmanaged is making this complicated and holding this up, is it worth deciding we just don't support that? Deciding not to support that doesn't sound amazing to me, but I'd rather that than make commonplace situations worse in the name of an edge case we don't even have a specific use case for. |
|
Without how tricky solving this is turning out to be, would you like me to take a crack at implementing it? |
|
I should have been clearer.
The example you mentioned (quoted below) will work (Example 1): const component = (
<li>
<details>
<ul>
<li key="abc"></li>
<li key="def"></li>
</ul>
</details>
</li>
);But the following will not always work (Example 2): const component = (
<div>
<Wrapper>
<Child key="abc"></li>
<Child key="def"></li>
</Wrapper>
</div>
);The different is that Example 1 which you had mentioned allows us to store key="abc" and key="def" on the parent I say may not, because it works in the following case (Example 3): function Wrapper(props) {
return (
<div>{props.children}</div>
);
}But it does not work in the following (Example 4): function Wrapper(props) {
return (
<>{props.children}</>
);
}The criteria is whether we have a real DOM parent to hold the keys of immediate child components having keys. Where it doesn't work is a combination of "Example 2 + Example 4". "Example 1", and "Example 2 + Example 3" together will work. |
We could do that, I just wanted confirmation from you. To confirm, here's what one could do: const component = (
<div id="parent">
<div id="unmanaged">We can do whatever we want inside it</div>
<SomeComp key="1">
<p>Hello</p>
</SomeComp>
<SomeComp key="2">
<p>Hello</p>
</SomeComp>
</div>
);What they're not allowed to do is to mutate the children of the element with id="parent" directly. In the current approach, I am mapping keys to the index of the node under parent.childNodes. Hence adding/removing nodes will throw the mapping off. But users are free to do what they want inside the element with id="unmanaged". |
I'll have another go at it; I think pretty close. |
|
All sounds good. |
|
Sorry for the long delay. Haven't been able to make progress - the approach I was trying didn't work. And I was not able to look at it much in December. :(
I'll keep trying, but if you have time please take a look at it as well. You might be able to solve it faster than me. |
|
Alright 🙂 I wonder if we should consider integrating with Morphdom? How we update the DOM isn't important to what sets Forgo apart, yet speed + correctness there has cost us a lot of effort. It'd be nice if we could just focus on our API. I haven't dug deeply into what it would take to integrate (besides knowing it would be a major code change (understatement)). I could dive in and find some reason it won't work for us. I also don't know how Morphdom compares on the specific benchmarks we're working on, though I can find out. On Morphdom's own benchmark it outperforms competing libraries, so I'm hopeful we'd see an improvement. Bundlephobia says Morphdom is 2KB min+gz. I expect we'll replace around that much of our own code, so it would be approximately net-zero change to our bundle size. But it would be our first dependency. It'd be a lot of work, but if you think it makes sense I'd be willing to take on investigating + implementing. |
From their benchmarks it seems to be about 2.5x slower than virtual-dom. The speed (of morphdom) is fine, but:
|
|
I had it somewhat working, but here was the flaw:
Here's what I think you'd need to do:
This might do the trick. I just haven't found time to do it yet. In case, you're taking a look at it as well, I think this is what you might need to do. To be honest, I don't think it's that complicated. It's just that I've been a little tired due to other work, and spending time with the family. :) |
|
This is almost done via #85. A few tests fail - will fix. I'll share it for your review once it's complete (if you have time that is). Required extensive rework, but it hugely simplifies many code paths (the bookkeeping logic is now far simpler). |
|
PR #85 is ready for test/review. |
|
Ran the benchmarks - v4 is far worse than v2. Gotta investigate. |
I've submitted Forgo to the JS framework benchmark suite. Forgo's performance has been adequate for my own apps so far, but I'm not really pushing the envelope. Forgo doesn't need to be "the fastest gun in the West", but we want to make sure it's not the slowest, either.
The official results won't include Forgo until the PR gets accepted, but here's what I see running select benchmarks locally. All scores are mean-average milliseconds.
The tests discourage microoptimizing - they should reflect idiomatic usage of the framework.
So anyways...
Forgo's on the slower side, with some room for improvement, especially for mutating existing elements.
Any thoughts on low-hanging fruit to target?
Here's the flamegraph for the Insert 10k test:
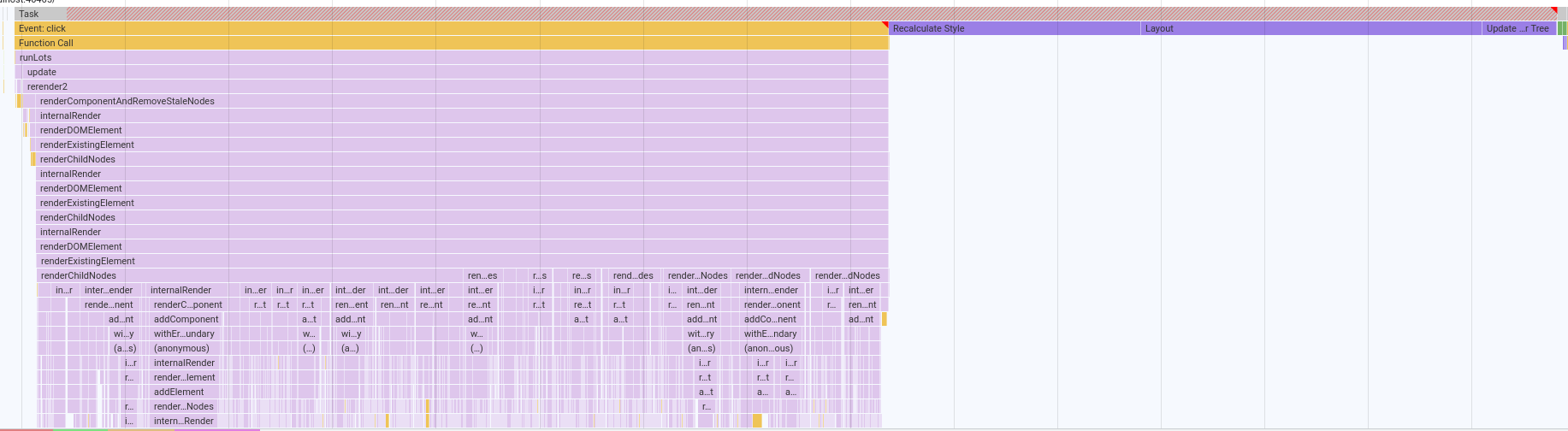
I don't know how to tie a specific item in that graph to which component was being rendered (short of just stepping through the debugger until I've hit a function N times), but there's clearly a lot going on.
The text was updated successfully, but these errors were encountered: