-
可靠
使用超时重传(发送端在发送报文后启动一个定时器,若定时器在规定时间内没有收到应答就会重发该报文),发送应答机制(发送端发送的每个TCP报文都必须得到接收方的应答)等方式来确保数据包被正确的发送到目的地。最后还会对收到的TCP报文进行重排、整理然后再交付给应用层。
-
面向连接
使用TCP链接的双方必须要建立连接,并在内核中为该链接维持一些必要的数据结构,比如度写缓冲区,定时器等
-
基于流
基于流的数据没有边界长度限制,源源不断的从通信的一端流入另一端。发送端可以逐个字节的向数据流中写入数据,接收端也可以逐字节的将他们读出。
-
不可靠
UDP协议无法保证数据能够从发送端正确的传送到目的端口。如果数据在中途丢失或目的端设备会通过数据校验发现数据错误而将其丢失,则UDP协议只是简单地通知应用程序发送失败
-
无连接
通信双方不能保持一个长久的链接,因此应用程序每次发送数据都要明确指明接收端的地址
-
基于数据报**(疑问)**
每个UDP数据报都有长度,接收端必须以该长度为最小单位将内容从缓存中读出,否则数据会被截断。
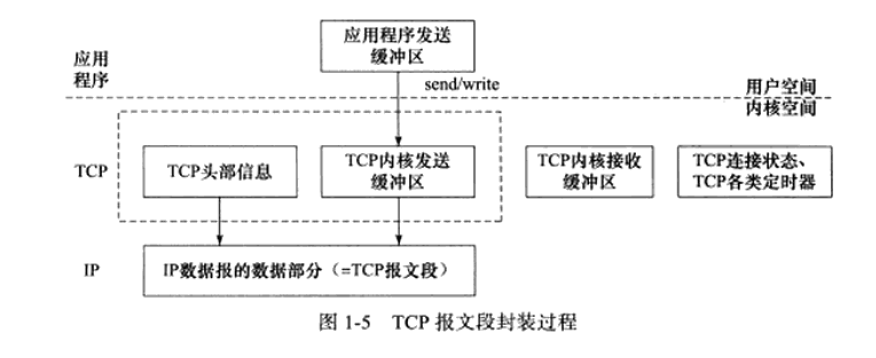
上图以发送为例来介绍这个过程:
- 应用程序通过调用send/write向TCP写入数据
- 从用户空间进入到内核空间
- 将应用缓冲区的数据复制到内核TCP发送缓冲区,同时在TCP协议中还要加上TCP头,还有各种定时器函数
- 将TCP报文段即TCP头部信息和TCP内核缓冲区数据发送到IP协议模块
- IP模块进行封装,加上自己的IP头
UDP封装与TCP类似,但是UDP无需为应用层数据保存一个副本,因为提供的是不可靠的服务。当一个UDP数据报被成功发送之后,UDP内核缓冲区就会把该数据丢弃。如果发送端应用程序检测到该UDP报文没有被正确接收并打算重发该数据的时候,由于没有缓存,应用程序需要重新将发送数据从用户空间拷贝到内核发送缓冲区。

如上图可以清晰的看见socket的位置
要明确,二三四层的协议都需要在操作系统内核中去实现,但是我们有应用程序需要去访问这些网络协议所提供的服务,因此我们用一组系统调用API去实现,因此socket就是这样一套API。
IP协议是TCP/IP协议族的动力,为上层提供了无状态、无连接、不可靠的服务
-
无状态
指进行IP通信的双方不同步传输数据的状态信息。所以所有IP数据报的发送、传输和接受都是独立的,没有上下文关系。
最大的缺点是无法处理乱序和重复的IP数据报
同时无状态服务也有优点:简单和高效。无需为保持通信状态而分配内核资源和算力,也无需每次传递数据都携带状态信息
-
无连接
指通信双方都不长久的维持对方的信息,因此当上层协议每次发送数据的时候都要指明对方的IP地址。
-
不可靠
指IP协议不能够保证IP数据报准确地到达接收端,他只是承诺尽最大努力交付。因此很多情况都可能导致IP数据报发送失败。因此可靠传输都是需要上层传输层协议去考虑的问题。
最直观的表现形式就是通信双方(发送方和服务器方)是否执行相同次数的读写操作
-
TCP字节流服务
当发送端应用程序执行多次写操作的时候,TCP模块先将这些数据放到TCP的发送缓冲区中。当TCP模块真正开始发数据的时候,发送缓冲区中这些等待发送的数据可能被封装成一个或多个TCP报文段发出,因此TCP模块的发送次数和应用程序执行写操作的次数之间没有固定的数量关系。
当接收端收到TCP报文的时候,按照顺序一次放入TCP接收缓冲区中供接收端应用程序读取。应用程序可以一次性将缓冲区的数据全部读出来,也可以分多次读取,因此TCP模块的接收和读操作之间也没有固定的数量关系。
因此我们可以看到发送端应用程序执行写操作的次数和接收端应用程序执行读操作的次数没有任何数量关系,这就是字节流——应用程序对数据的发送和接收是没有边界的。
-
数据报服务‘
对于UDP协议来说,发送端应用程序每执行一次写操作,UDP模块就将其封装成数据报然后发送,同时接收端必须及时针对每一个UDP数据报进行接收然后应用程序进行读操作,否则就会丢包。
-
MTU(Maximum Transmission Unit,MTU)最大传输单元
MTU主要是针对于二层来说的,限制了数据链路层上可以传输数据报的大小,因此也限制了网络层上的数据包的大小。
以太网中为1500字节
-
MSS(Max Segment Size)最大报文段长度
这个是TCP报文段每次传输中数据部分的大小,一般为MTU-20IP头部长度-20TCP头部长度。

由于TCP链接是全双工的,因此允许两个方向上数据的传输状态被独立的关闭。即通信的一端可以发送结束报文给对方,告诉我已经完成了数据的发送,但是还是可以继续接收数据。
这两个有时候老是分不清楚,因此就放在一起来说了。
-
超时重连
针对的是建立连接的过程来说,如果发送端的同步报文信息发出去了但是迟迟没有收到对方的应答报文,就会进行重传。
在linux中 /proc/sys/net/ipv4/tcp_syn_retries文件中定义了重连的操作。每次重连的超时时间都增加一倍,在5次重连之后TCP模块就会放弃连接并通知于应用程序。
-
超时重传
TCP协议必须能够重传超时时间内未收到确认的TCP报文。这是在网络异常情况下讨论的
TCP模块为每个TCP报文段都维护了一个重传定时器,该定时器在发送报文的时候被启动,如果超时时间内未收到应答,TCP模块将重传报文段并且重置定时器。TCP一般会执行5次重传策略,每次重传超时时间都增加一倍(这点和超时重连很像)
Linux中有两个内核参数和重传有关
- /proc/sys/net/ipv4/tcp_retries1 指定底层IP接管之前TCP最少执行的重传次数
- /proc/sys/net/ipv4/tcp_retries2 指定放弃连接前TCP最多可以执行的重传次数

-
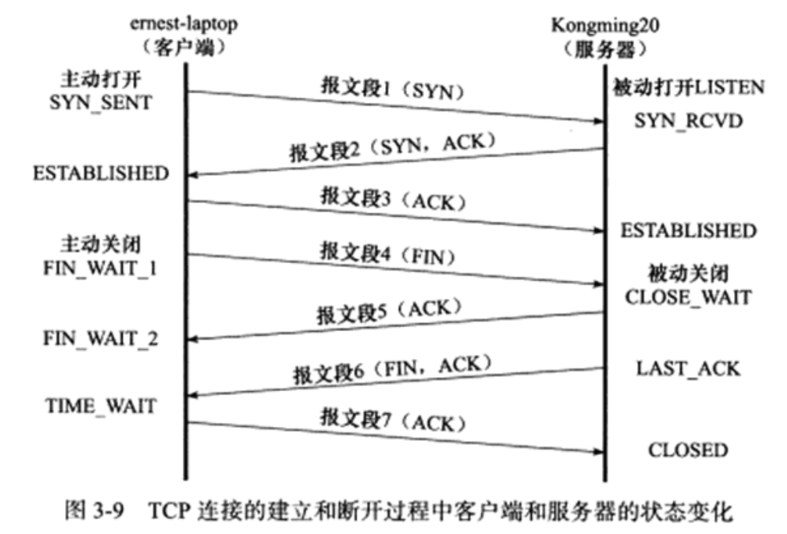
服务器通过listen系统调用进入LISTEN(监听)状态,被动的等待客户端的连接
-
服务器监听到某个请求(收到同步报文段),进入到SYN_RCVD状态,就会将该连接放入内核等待队列中,称为半连接队列。同时向客户端发送带SYN标志、ACK标志的确认报文段。
-
如果服务器成功的接收到客户端发送过来的确认报文段,则该连接进入到ESTABLISHED状态,双方可以进行双向数据传输。
-
当客户端主动关闭连接的时候,服务端收到FIN关闭报文,进入到CLOSE_WAIT状态的同时发送确认报文。这个状态就是为了等待服务器应用程序关闭连接,此时客户端到服务器的已经关了,但是服务器到客户端的还没有关掉。
当服务器检测到客户端关闭连接后,就会再发送一个ack报文段给客户端,这个时候就进入了LAST_ACK状态,等待客户端对结束报文的最后一次确认,一旦确认完成连接就彻底关闭。
-
客户端通过connect系统调用主动与服务器建立连接、首先给服务器发送一个同步报文,使得连接进入SYN_SENT状态。此后返回失败有两种可能
- 目标端口不存在,或者该端口仍处于TIME_WAIT状态的连接所占用,则服务器给客户端发送一个复位报文段,表示连接失败
- 目标端口存在,但是connect在超时时间内未收到来自服务器的确认报文
调用失败使得进入CLOSED状态
如果成功则进入ESTABLISHED状态
-
客户端主动执行关闭,发送结束报文段给服务器端,同时进入FIN_WAIT_1状态。
-
客户端收到了来自服务器的确认报文段,则进入FIN_WAIT_2状态。当客户端处于FIN_WAIT_2状态的时候服务器处于CLOSE_WAIT状态,可能会发生半关闭状态。
-
随后服务器又发送ack报文段,则客户端进入TIME_WAIT状态,
注意,处于FIN_WAIT_2状态的客户端需要等待服务器发送带有FIN、ACK的报文段后才能转移到TIME_WAIT状态,否则就会一直停留在FIN_WAIT_2状态。如果不是为了在半关闭状态下接收数据,长时间停留在这个状态没有一处。
连接停留在FIN_WAIT_2状态可能发生在客户端执行半关闭后未等服务器关闭连接就强行退出了。此时客户端由内核接管,成为孤儿连接。内核中有指定孤儿连接的数目和孤儿连接的生存时间。
客户端收到了来自服务器的带有FIN、ACK的结束报文段后并没有直接关闭,而是进入了TIME_WAIT状态。
在这个状态中客户端只有等待2MSL(Maximum Segment Life,报文段最大生存时间)才能完全关闭。MSL是报文段在网络中的最大生存时间,RFC文档的建议值是2分钟。
TIEM_WAIT存在的原因有以下两点:
-
可靠的终止TCP连接
当客户端向服务器发送的最后一个确认报文段丢失的时候,也就是说服务器没有收到客户端的确认报文段(TCP状态转移中的图),那么服务器将重新发送带有FIN、ACK的结束报文段。这样客户端必须停留在某个状态来接收服务器发送过来的结束报文段才行,所以要有TIME_WAIT状态。
-
保证让迟来的TCP报文段有足够的时间被识别并丢弃
一个TCP端口不能同时被打开多次,当TCP连接的客户端处于TIME_WAIT的时候,我们没有办法在被占的端口建立新连接。如果不存在TIME_WAIT状态,则应用程序就可以建立一个和刚关闭的连接相似的连接(相同的IP、端口号),那么这个新连接就会收到可能属于原来连接的数据,这显然是不应该发生的。
TCP报文最大生存时间是MSL,所以坚持2MSL时间的TIME_WAIT可以保证链路上未被收到的,延迟的TCP报文段都消失,这样当相似新连接建立的时候就不会受到原来属于就连接的数据报文
由于客户端使用系统自动分配的临时端口号来建立连接,所以一般不用考虑这个问题。
在某些情况下,TCP连接的一端回向另一端发送携带RST标志的报文段,即复位报文段,以通知对方关闭连接或重新建立连接。主要有以下三种情况:
- 1、访问不存在端口
当访问不存在的端口时候,服务器将发送一个复位报文段。因为复位报文段接收通告窗口大小为0,所以受到复位报文段的一端应该关闭连接或者重新连接,而不能回应这个复位报文段。
当客户端向服务器某个端口发起连接的时候,若端口处于TIME_WAIT状态,客户端程序也会收到复位报文段。
- 2、异常终止连接
TCP提供了一个异常终止连接的方法:给对方发送一个复位报文段,一旦发送了复位报文段,发送端所有排队等待发送的数据都将被丢弃。
- 3、处理半打开连接
情况出现原因:客户端突然关闭了连接,但是服务器没有接收到结束报文段,此时服务器还维持着原来的连接,而客户端即使重启也没有原来的连接。这种状 态称为半打开状态,处于这种状态的连接称为半打开连接。如果服务器往半打开连接中写入数据,则发送端会回应一个复位报文段(客户端被内核接管)。
TCP所携带的应用程序数据按照长度可以分为两种:交互数据和成块数据。
从服务器视角来看,若TCP是交互数据块的话,证明数据量很少,这种情况下服务器没有必要收到一个数据报就确认一个。而是在一段时间延迟后查看服务器端是否有数据需要发送,有的话确认消息就和数据一起发出。由于服务器对客户请求处理的很快,因此当发送确认报文段的时候总会有数据和这个确认信息一起发出。
延迟确认可以减少TCP报文的发送数量,对于客户端来说,由于用户输入数据的速度明显慢于客户端处理数据的速度,因此客户端的确认报文段总是不携带任何应用数据。因此本质上还是想减少网络中传输的TCP报文段数量,防止拥塞。有一个算法也是为了防止拥塞。
出现原因:small packet problem。有一些对实时性要求高的应用程序如ssh会发送一个字节的情况,这个时候发送一个TCP包需要20ip头+20tcp头+1字节数据=41字节。可以看到只有1字节有用信息。
nagle算法要求TCP通信连接的双方在任意时刻只能发送一个未被确认的TCP报文段,同时在该TCP确认报文段到达之前不能发送其它TCP报文段。
另外发送确认报文的一方再等到对方回复的同时也在收集本端需要发送的微量数据,并在回复到来之后用一个TCP报文段将他们全部发出。
见面试总结中的拥塞控制
-
正向代理服务器
要求客户端自己设置代理服务器的地址。客户的每次请求都将发送到代理服务器,由代理服务器来请求目标资源。比如防火墙内的局域网机器要访问Internet,或者国内访问一些被屏蔽掉的国外网站就需要用。
正向代理服务器和客户端主机处于同一个逻辑网络中。
-
反向代理服务器
设置在服务器端,客户端这边无需进行任何配置。反向代理是指用代理服务器来接收Internet上的连接请求,然后再将请求转发给内部网络的服务器,并将从内部服务器上得到的结果返回给客户端。
反向代理服务器和web服务器也处于同一个逻辑网络中
-
透明代理服务器
透明代理只能设置在网关上,用户访问Internet上的数据必然要经过网关,如果在网关上设置代理,那么对于用户来说就是透明的。
-
代理服务器还通常提供目标缓存功能,这样用户访问同一资源的时候速度会很快。
目标资源的URL是http://www.baidu.com/index.html
http就是获取目标资源需要使用的应用层协议
www.baidu.com就是资源所在的目标主机,要借助dns服务找到IP地址进而访问
index.html是资源文件的名称,是服务器文件的根目录
HTTP是一种无状态的协议,即每个HTTP请求之间没有任何上下文关系,如果服务器处理后续HTTP请求时需要用到前面的HTTP请求的相关信息就必须重传之前的HTTP请求,这样会使得HTTP请求必须传输更多的数据。
由于交互程序要承上启下,因此HTTP的这种特点就不适用了,就有了cookie。
cookie是服务器发送给客户端的特殊信息,而后客户端每次向服务器发送信息的时候都带着这些信息,这样服务器就可以区分不同的客户端。
大端字节序指整数的高位字节存储在内存的低地址处,符合人类的读写习惯。
小端字节序指整数的高位字节存储在内存的高地址处,低位字节存储在低地址处。
在Linux网络编程中,会使用下列C标准库函数进行字节之间的转换
#include <arpa/inet.h>
uint32_t htonl(uint32_t hostlong); //把uint32_t类型从主机序转换到网络序
uint16_t htons(uint16_t hostshort); //把uint16_t类型从主机序转换到网络序
uint32_t ntohl(uint32_t netlong); //把uint32_t类型从网络序转换到主机序
uint16_t ntohs(uint16_t netshort); //把uint16_t类型从网络序转换到主机序其他的参考c++面试操作系统那部分,有详细的记载。
被动socket(server) 主动socket(client)
---------------------------------------------------------------------------
socket()
|
bind()
|
listen() socket()
| |
accept() |
| |
| <------------------------- connect()
| |
read() <------------------------ write()
| |
write() -----------------------> read()
| |
close() close()
---------------------------------------------------------------------------
表示socket地址的是结构体sockaddr,定义如下:
struct sockaddr
{
uint8_t sin_len;
sa_family_t sin_family;
char sa_data[14]; //14字节,包含IP和地址
}; sockaddr的缺陷是把目标地址和端口混在一起了,所以TCP/IP协议族有两个专用的socket地址结构体如下(只介绍IPv4的):
struct sockaddr_in
{
uint8_t sin_len;
sa_family_t sin_family; //地址族:AF_INET
in_port_t sin_port; //端口号,网络字节序表示
struct in_addr sin_addr; //ipv4结构体
char sin_zero[8]; //8字节
};
struct in_addr
{
u_int32_t s_addr; //ipv4地址,要用网络字节序表示
};所有专用的socket地址类型的变量在实际使用时候都需要转化为通用socket地址类型
sockaddr(强转就行),因为所有socket编程接口使用的地址参数类型都是sockaddr!!
#include <arpa/inet.h>
in_addr_t inet_addr(const char* strptr);
int inet_aton(const char* cp, struct in_addr* inp);
char* inet_ntoa(struct in_addr in);
int inet_pton(int af, const char* src, void* dst);
const char* inet_ntop(int af, const void* src, char* dst, socklen_t cnt);inet_addr函数将用点分十进制字符串表示的IPv4地址转化为用网络字节序整数表示的IPv4地址。
inet_aton函数完成和inet_addr同样的功能,但是将转化结果存储于参数inp指向的地址结构中。
inet_ntoa函数将用网络字节序整数表示的IPv4地址转化为用点分十进制字符串表示的IPv4地址。
该函数内部用一个静态变量存储转化的结果,函数返回值指向该静态内存,因此inet_ntoa是不可重入的。
#include <sys/types.h> /* See NOTES */
#include <sys/socket.h>
int socket(int domain, int type, int protocol);| 协议簇 | 地址族 | 描述 |
|---|---|---|
| PF_UNIX | AF_UNIX | UNIX本地域协议族 |
| PF_INET | AF_INET | TCP/IPv4协议族 |
| PF_INET6 | AF_INET6 | TCP/IPv6协议族 |
由于宏AF_*和PF_*定义的是完全相同的值,所以二者经常混用
-
type
名称 含义 SOCK_STREAM Tcp连接,提供序列化的、可靠的、双向连接的字节流。支持带外数据传输 SOCK_DGRAM 支持UDP连接(无连接状态的消息) SOCK_SEQPACKET 序列化包,提供一个序列化的、可靠的、双向的基本连接的数据传输通道,数据长度定常。每次调用读系统调用时数据需要将全部数据读出 SOCK_RAW RAW类型,提供原始网络协议访问 SOCK_RDM 提供可靠的数据报文,不过可能数据会有乱序 -
protocol
函数socket()的第3个参数protocol用于制定某个协议的特定类型,即type类型中的某个类型。通常某协议中只有一种特定类型,这样protocol参数仅能设置为0;但是有些协议有多种特定的类型,就需要设置这个参数来选择特定的类型。
一般设置为0
-
socket返回的错误类型
值 含义 EACCES 没有权限建立指定的domain的type的socket EAFNOSUPPORT 不支持所给的地址类型 EINVAL 不支持此协议或者协议不可用 EMFILE 进程文件表溢出 ENFILE 已经达到系统允许打开的文件数量,打开文件过多 ENOBUFS/ENOMEM 内存不足。socket只有到资源足够或者有进程释放内存 EPROTONOSUPPORT 制定的协议type在domain中不存在
int bind( int sockfd, struct sockaddr* addr, socklen_t addrlen)在创建一个socket的时候我们给socket指定了地址族,但是重点是没有给这个socket指定一个具体的地址,因此bind就是将创建的socket文件描述符和一个socket地址绑定。
对于服务器这边的代码来说,要绑定一个众所周知的IP地址和端口以等待客户连接
-
bind返回的错误类型
值 含义 备注 EADDRINUSE 给定地址已经使用 EBADF sockfd不合法 EINVAL sockfd已经绑定到其他地址 ENOTSOCK sockfd是一个文件描述符,不是socket描述符 EACCES 地址被保护,用户的权限不足 EADDRNOTAVAIL 接口不存在或者绑定地址不是本地 UNIX协议族,AF_UNIX EFAULT my_addr指针超出用户空间 UNIX协议族,AF_UNIX EINVAL 地址长度错误,或者socket不是AF_UNIX族 UNIX协议族,AF_UNIX ELOOP 解析my_addr时符号链接过多 UNIX协议族,AF_UNIX ENAMETOOLONG my_addr过长 UNIX协议族,AF_UNIX ENOENT 文件不存在 UNIX协议族,AF_UNIX ENOMEN 内存内核不足 UNIX协议族,AF_UNIX ENOTDIR 不是目录 UNIX协议族,AF_UNIX
int listen(int sockfd, int backlog);当bind完成后并不能马上就能接受客户端连接,需要使用listen系统调用来创建一个监听队列以存放待处理的客户端连接。
backlog参数表示内核监听队列的最大长度,如果超过这个最大长度则服务器将不受理新的客户连接,客户端也将收到错误返回,典型值是5。如果底层协议支持重传(比如tcp协议),本次请求会被丢弃不作处理,在下次重试时期望能连接成功(下次重传的时候队列可能已经腾出空间)。
-
listen函数返回值
值 含义 EADDRINUSE 另一个套接字已经绑定在相同的端口上。 EBADF 参数sockfd不是有效的文件描述符。 ENOTSOCK 参数sockfd不是套接字。 EOPNOTSUPP 参数sockfd不是支持listen操作的套接字类型。
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);sockfd参数是指执行过listen系统调用的监听socket,addr是来获取接受连接的客户端的地址信息。
accept成功的时候会返回一个新的socket,这个新socket唯一的标识了这个被接受的连接,服务端和客户端就是通过这个socket来建立连接和通信的。
accept是一个阻塞式的函数,对于一个阻塞的套接字,要么一直阻塞直到等到想要的值。对于非阻塞套接字会调用完直接返回一个值。accept有可能返回-1,但是如果errno的值为,EAGAIN或者EWOULDBLOCK,此时需要重新调用一次accept函数。
-
accept函数的返回值
值 含义 EBADF 非法的socket EFAULT 参数addr指针指向无法存取的内存空间 ENOTSOCK 参数s为一文件描述词,非socket EOPNOTSUPP 指定的socket并非SOCK_STREAM EPERM 防火墙拒绝此连线 ENOBUFS 系统的缓冲内存不足 ENOMEM 核心内存不足
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);这个函数是对于客户端来说的。sockfd是系统调用socket()返回的套接字文件描述符,serv_addr 是保存着要连接对象目的地端口和IP地址的数据结构 struct sockaddr_in。
-
connect返回的值
值 含义 EBADF 参数sockfd 非合法socket处理代码 EFAULT 参数serv_addr指针指向无法存取的内存空间 ENOTSOCK 参数sockfd为一文件描述词,非socket。 EISCONN 参数sockfd的socket已是连线状态 ECONNREFUSED 连线要求被server端拒绝。 ETIMEDOUT 企图连线的操作超过限定时间仍未有响应。 ENETUNREACH 无法传送数据包至指定的主机。 EAFNOSUPPORT sockaddr结构的sa_family不正确。
#include<unistd.h>
int close(int fd)close系统调用并非总是立刻关闭一个连接,而是将fd的引用计数减一。只有当fd的引用计数为0的时候才真正关闭连接。
比如多进程中我们使用系统调用创建一个子进程,会将父进程中打开的socket的引用计数+1,因此必须在父进程和子进程中都对执行close函数才能关闭连接,也就是必须执行两次close将引用计数-2才行。
立即终止连接是如下函数:
#include<sys/socket.h>
int shutdown(int fd, int howto)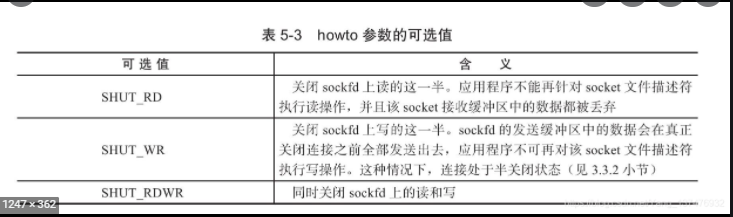
#include <sys/types.h>
#include <sys/socket.h>
ssize_t recv(int sockfd, void *buf, size_t len, int flags);
ssize_t send(int sockfd, const void *buf, size_t len, int flags);recv()用于读取sockfd上的数据,buf和len参数分别指定读缓冲区的位置和大小,flags参数用于数据收发的额外控制,通常设置为0。
函数执行成功返回实际读取到的数据的长度,它可能小于程序员所期望的长度len。待读取的数据大于len时需要多次调用recv()才能完整读取,被读取过后的数据,将会在内核空间的接收缓冲区清除。recv()可能返回0,即对端已经关闭连接,出错则返回-1并设置errno。
send()用于往sockfd写入数据,buf和len参数分别指定写缓冲区的位置和大小。send()成功时返回实际写入的数据的长度,失败则返回-1并设置errno。
需要注意的是,send()实际是将应用程序的数据拷贝到内核的TCP模块的发送缓冲区,发往网络连接的具体实现是在系统内核。所以send()返回成功的情况下,也不能证明数据就一定发送成功。
-
flag参数
选项名 含义 send recv MGS_CONFIRM 提示数据链路层协议持续监听对方的回应,知道得到答复。它仅能用于SOCK_DFRAM和SOCK_RAW类型的socket。 Y N MSG_DONTROUTE 不查看路由表,直接将数据发送给本地局域网内的主机。这表示发送者的确地知道目标主机就在本地网络上 Y N MSG_DONTWAIT 对socket的此类操作将是非阻塞的 Y N MSG_MORE 告诉内核程序还有更多数据要发送,内核将超时等待数据写入TCP发送缓冲区后一并发送。这样可防止TCP发送过多小的报文段,从而提高传输效率。 Y N MSG_WAITALL 读操作仅在读取到指定数量的字节才返回 N Y MSG_PEEK 窥探读缓存中的数据,此次读操作不会导致这些数据被清除 N Y MSG_OOB 发送或接受紧急数据 Y N MSG_NOSIGNAL 王读端关闭的管道或者socket连接中写数据时不引发SIGPIPE信号 Y N
#include <sys/types.h>
#include <sys/socket.h>
ssize_t recvfrom(int sockfd,void* buf, size_t len, int flags, struct sockaddr* src_addr,socklen_t* addrlen);
ssize_t sendto(int sockfd, const void* buf, size_t len, int flags, const struct sockaddr* dest_addr,socklen_t addrlen);- recvfrom读取sockfd上的数据,buf和len参数分别指定读缓冲区的位置和大小。 因为UDP通信没有连接的概念,说我们每次读取的数据都需要获取发送端的socket地址,即参数src_addr所指的内容,addrlen参数则指定该地址的长度。
- sendto往sockfd上写入数据,buf和len参数分别指定读缓冲区的位置和大小。dest_addr参数指定接收端的socket地址,addrlen参数指定该地址的长度。
socket编辑接口还提供了一堆通用的数据读写系统调用。他们不仅能用于TCP数据流,也可以用于UDP数据报
#include <sys/socket.h>
ssize_t recvmsg(int sockfd,struct msghdr* msg, int flags);
ssize_t sendmsg(int sockfd,struct msfhdr* msg, int flags);sockfd参数指定被操作的目标socket。msg参数是msghdr结构体类型的指针,msghdr结构体的定义如下:
struct msghdr
{
void* msg_name; //socket地址
socklen_t msg_namelen; //socket地址的长度
struct iovec* msg_iov; //分散的内存块
int msg_iovlen; //分算的内存块数量
void* msg_control; //指向辅助数据的起始位置
socklen_t msg_controllen; //辅助数据的大小
int msg_flags; //赋值函数中的flags参数,并在调用过程中更新
};socket选项主要是由setsockopt和getsockopt函数完成的。
#include <sys/types.h>
#include <sys/socket.h>
int getsockopt(int sockfd, int level, int optname,void *optval, socklen_t *optlen);
int setsockopt(int sockfd, int level, int optname,const void *optval, socklen_t optlen);| level | option name | 数据类型 | 说明 |
|---|---|---|---|
| SO_BROADCAST | int | 允许发送广播数据报 | |
| SO_DEBUG | int | 打开调试信息 | |
| SO_REUSEADDR | int | 重用本地地址 | |
| SO_TYPE | int | 获取socket类型 | |
| SO_ERROR | int | 获取并清除socket错误状态 | |
| SO_DONTROUTE | int | 不查看路由表,直接将数据发送给本地局域网内的主机。含义和send系统调用的MSG_DONTROUTE标志类似 | |
| SO_RCVBUF | int | TCP接受缓冲区大小 | |
| SO_SNDBUF | int | TCP发送缓冲区大小 | |
| SO_KEEPALIVE | int | 发送周期性保活报文以维持连接 | |
| SO_OOBINLINE | int | 接收到的带外数据将保留在普通数据的输入队列中(在线保留) | |
| SO_LINGER | linger | 若有数据待发送, 则延迟关闭 | |
| SO_RCVLOWAT | int | TCP接收缓冲区低水位标记 | |
| SO_SNDLOWAT | int | TCP发送缓冲区低水位标记 | |
| SO_RCVTIMEO | itmeval | recv,recvmsg,accept [返回-1, 设置errno为EAGAIN或EWOULDBLOCK] | |
| SO_SNDTIMEO | timeval | send, sendmsg [返回-1, 设置errno为EAGAIN或EWOULDBLOCK], connect [[返回-1, 设置errno为EWOULDBLOCK]] | |
| SOL_SOCKET(通用socket选项, 与协议无关) | SO_USELOOPBACK | 路由套接字取得所发送数据的副本 | |
| IP_TOS | int | 服务类型 | |
| IPPROTO_IPv4(IPV4选项) | IP_TTL | int | 保活时间 |
| IPV6_NEXTHOP | sockaddr_in6 | 下一跳IP地址 | |
| IPV6_RECVPKTINFO | int | 接收分组信息 | |
| IPV6_DONTFRAG | int | 禁止分片 | |
| IPPROTO_IPv6(IPv6选项) | IPV6_RECVTCLASS | int | 接收通讯类型 |
| TCP_MAXSNG | int | TCP最大报文段大小 | |
| IPPROTO_TCP(TCP选项) | TCP_NODELAY | int | 禁止Nagle算法 |
#include <sys/socket.h>
/* 获取sockfd本端socket地址,并将其存储于address参数指定的内存中 */
int getsockname ( int sockfd, struct sockaddr* address, socklen_t* address_len );
/* 获取sockfd对应的远端socket地址,其参数及返回值的含义与getsockname的参数及返回值相同 */
int getpeername ( int sockfd, struct sockaddr* address, socklen_t* address_len ); #include <netdb.h>
struct hostent* gethostbyname(const char* name);
struct hostent gethostbyaddr(const void* addr, size_t len, int type);
struct hostent{
char* h_name; //主机名
char** h_aliases;//主机别名列表,可能由多个
int h_addrtype; //地址类型(地址族)
int h_length; //地址长度
char** h_addr_list;//按网络字节序列出的主机IP地址列表
}//根据名称获取某个服务器的完整信息
#include<netdb.h>
struct servent* getservbyname (const char* name,const char* proto);
struct servent* getservbyport (int port ,const char* proto);
struct servent{
char* s_name;//服务名称
char** s_aliases;//服务的别名列表,可能多个
int s_port;//端口号
char* s_proto;//服务类型,通常是TCP或者UDP
}//将返回的主机名存储在hsot参数指向的缓存中,将服务名存储在serv参数指向的缓存中,hostlen和servlen参数分别指定这两块缓存的长度
#include<netdb.h>
int getnameinfo (const struct sockaddr* sockaddr,socklen_t addrlen,char* host,socklen_t hostlen,char* serv,socklen_t servlen,int flags);文件I/O
标准I/O
高级I/O
这三种要分清楚
-
Linux服务器一般都是以后台进程形式运行。后台进程又称守护进程(daemon)。没有控制终端,也不会意外接收到用户的输入。守护进程的父进程通常是init进程(PID为1)
-
linux服务器有一套日志系统,通常在/var/log目录下。Linux提供一个守护进程来处理日志,syslogd和rsyslogd,现在一般用后者。
rsyslogd技能接收用户进程输出的日志也能接收内核日志。
用户通过调用syslog函数来生成系统日志的。
-
linux服务器一般以某个专门的非root用户运行。
一个进程有两个ID:UID和EUID。
UID:真实用户ID,即这个进程属于那个用户的。
EUID:有效用户ID。这个存在的目的是方便资源访问,使得该进程的用户拥有EUID用户的权限。
比如su程序,每个用户都可以用,但是其EUID就是root。主要是为了给用户提供某些权限
-
Linux服务器程序通常是可配置的。服务器程序通常能够处理很多命令行选项,如果一次运行的选项太多,则可以用配置文件来管理。
绝大多数的服务器配置文件都放在/etc目录下
-
服务器程序后台化,让一个进程以守护进程的方式运行。
主要将服务器结构为三个模块:
- I/O处理单元,主要有四种I/O模型和两种高效事件处理模式
- 逻辑单元,怎样对数据进行处理,两种高效并发模式和有限状态机
- 存储单元,将数据存起来
TCPIP协议在最开始是没有客户端和服务端的概念的,但是现实中我们的很多应用都需要服务器提供服务然后客户端去访问这些服务,数据资源被提供者所垄断。
-
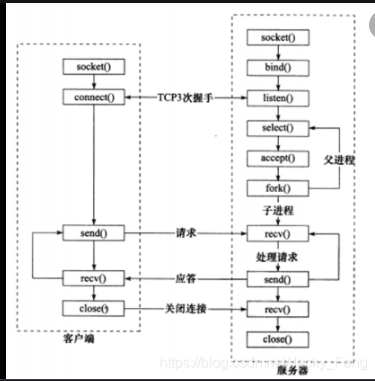
C/S模型
服务器启动之后,首先创建一个或者多个监听socket,然后调用bind函数将其绑定到服务器的相关端口上,然后调用listen函数等待客户端的连接。服务器运行稳定之后,客户端就调用connect函数向服务器发起连接请求。由于客户请求的到达是随机的异步事件,因此服务器要用某种IO模型来监听这一事件。当监听到来自客户端的链接请求之后就将请求放入接收队列中,然后服务器端调用accept函数接受它,并分配一个逻辑单元为新的连接服务,连接单元可以使新创建的子进程,子线程或其他。
优点是适合资源相对集中的场合,并且实现简单
缺点是服务器是通信的中心,当访问量过大时,所有客户得到响应的速度会变慢。
-
P2P模型
此模型摒弃了以服务器为中心的格局,让网络中的所有主机重新回归对等地位。
使得每台机器在消耗服务的同时也给别人提供服务,这样资源能够得到充分自由的共享。
由于主机之间很难发现对方,因此实际使用的p2p模型带有一个专门的发现服务器,每台主机既是客户端又是服务器。



-
IO处理单元
是服务器管理客户连接的模块。有以下任务要完成:等待并接受新的客户连接,接收客户数据,将服务器响应的数据返回给客户端。
对于服务器集群来说,IO处理单元是一个专门的接入服务器,用来实现负载均衡,然后从所有逻辑服务器中选取一台负荷最小的为新接入的客户端服务
-
逻辑单元
一个逻辑单元通常是一个进程或者线程。它分析并处理客户端数据,然后将结果发送给IO处理单元或者直接返回给客户端
对于服务器集群来说一个逻辑单元就是一台服务器。但一般一个服务器拥有多个逻辑单元,以实现多个任务的并行处理
-
网络存储
可以使数据库、文件、缓存,甚至是一台独立的服务器,但不是必须的,比如ssh服务
-
请求队列
当请求连接的客户端数量多了之后或者需要处理的数据多了之后就需要请求队列保证顺序。
IO处理单元接受到了客户请求时候,需要以某种方式通知逻辑单元请求该连接。同样,多个逻辑单元同时访问一个存储单元时也同样需要某种机制来协调竞争条件。
请求队列通常被实现为池的一部分。
对服务器集群来说,请求队列是各台服务器预先建立的、静态的、永久的TCP连接。
socket在创建时候默认是阻塞的,我们可以给socket参数传递SOCK_NONBLOCK标志或者通过fcnl函数的F_SETFL命令将其变成非阻塞的。
针对阻塞IO执行的系统调用可能因为无法立即完成而被操作系统挂起,直到等待的事件发生为止。因此被阻塞的系统调用有accept、send、recv、connect。
比如connect,客户端通过connect向服务器发起连接,发送同步报文段给服务器,然后等待服务器返回确认报文段。如果服务器的确认报文段没有立即到达,则connect调用将被挂起直到客户端收到确认报文段然后唤醒connect
针对非阻塞IO总是立即返回的,不管发生还是没发生。如果事件没有发生就返回-1,需要根据返回值来区分。很明显非阻塞IO需要和其他IO通知机制一起使用比如IO复用或者SIGIO信号。
从理论上来说阻塞IO,非阻塞IO复用和非阻塞信号驱动IO都是同步IO模型。因为IO的读写操作都是IO事件发生之后由应用程序完成的。
对异步IO来说,用户可以直接对IO执行读写操作,这些操作告诉内核用户读写缓冲区的位置,以及IO操作完成之后内核通知应用程序的方式。异步IO的读写操作总是立即返回的,不论IO操作是否阻塞,因为真正的读写操作已经由内核接管。
同步IO模型要求用户代码自行执行IO操作,即将数据从内核缓冲去中读入用户缓冲区或者将用户缓冲区的数据写入内核缓冲区。而异步IO机制由内核执行IO操作,即数据在内核和用户缓冲区之间的操作由内核自动完成。即同步IO向应用程序通知的是IO就绪事件,异步IO向应用程序通知的是IO完成事件。
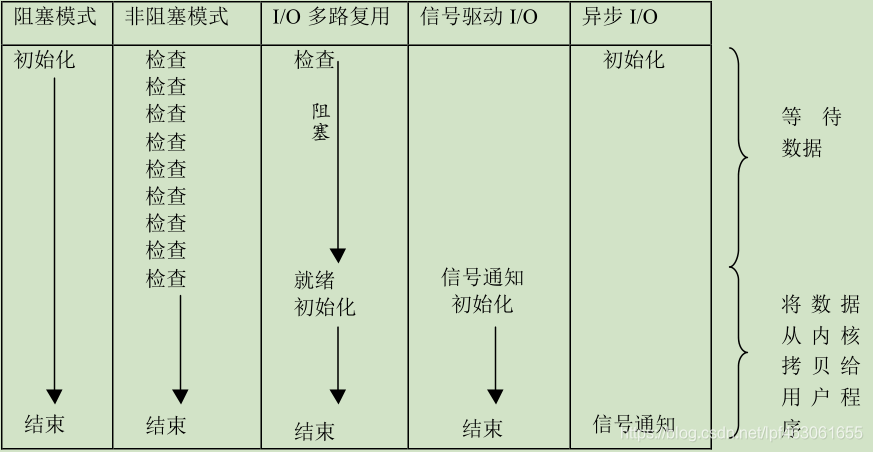
服务器程序通常要处理三类事件:IO事件、信号及定时事件
同步IO模型通常用于实现Reactor模式,而异步IO模型通常用于实现Proactor模式
-
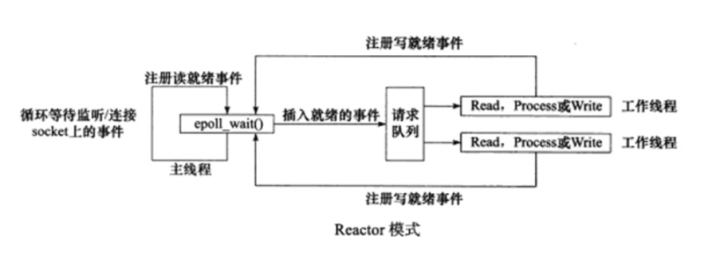
Reactor模式
定义:主线程主要用来监听文件描述符是否有事件发生,有的话就将该事件通知工作线程即逻辑处理单元,除此之外主线程不用做任何事情。读写数据,接受新的连接、处理客户端请求均在工作线程中完成。
工作流程如下:
- 主线程往epoll内核时间表中注册socket上的读就绪事件
- 主线程调用epoll_wait等待socket上有数据可读
- 当有数据可读时,epoll_wait通知主线程,然后主线程将可读事件放入请求队列中
- 睡眠在请求队列上的某个工作线程被唤醒,从socket中读取数据并处理客户端请求
- 然后往epoll内核事件表中注册socket的写事件
- 主线程调用epoll_wait等待socket可写
- 当socket可写的时候epoll_wait通知主线程,主线程将socket写事件放入请求队列
- 睡眠在请求队列上的某个工作线程被唤醒,王socket写入服务器处理客户端请求的结果。
-
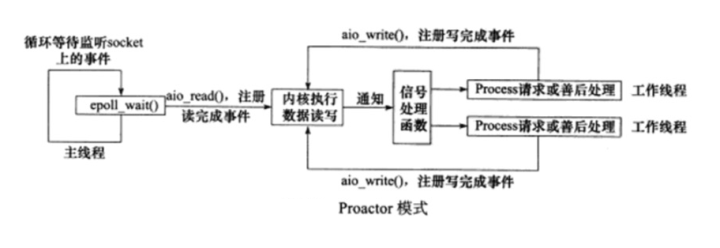
Proactor模式
定义:所有IO操作都交给主线程和内核来处理,工作线程仅负责业务逻辑,而Reactor模式中工作线程不仅仅负责业务逻辑。
工作流程如下:
- 主线程调用aio_read函数向内核注册socket上的读完成事件,并告诉内核用户读缓冲区的位置,以及读操作完成时如何通知应用程序
- 主线程继续处理其他逻辑
- 当socket上的数据被读入用户缓冲区之后,内核向应用程序发送一个信号,通知应用程序数据可用了
- 应用程序预先定义好的一个信号处理函数选择一个工作线程来处理客户端请求。
- 工作线程处理完客户端请求之后,主线程调用aio_write函数向内核注册socket上的写完成事件,并告诉内核用户写缓冲区的位置,以及操作完成后如何通知用户
- 主线程继续处理其他逻辑
- 当用户缓冲区的数据被写入socket之后,内核将向应用程序发送一个信号,通知于应用程序已经发送完毕
- 应用程序预先定义好的信号处理函数选择一个工作线程来做善后处理,比如是否关闭socket
住现成的epoll_wait只能用来监听socket上的连接请求,而不能用来检测连接socket上的读写时间。
并发模式是指IO处理单元和多个逻辑单元之间协调完成任务的方法。
这里面的同步异步IO操作的同步异步是不一样的。
IO模型中同步异步区分的是内核向应用程序通知的是就绪事件(同步,必须等数据都到了在通知)还是完成事件(异步,数据全部到了再回来操作),以及是应用程序来完成IO读写还是内核完成IO读写。
并发模式中的同步异步指的是程序完全按照代码顺序执行(同步)还是程序的执行需要由系统事件的驱动(异步)

纯异步线程:执行效率高、实时性强,因此是很多嵌入式程序选择的模型。但是编写异步程序难于调试和扩展,相对复杂因此不适合于大量并发。
纯同步线程:效率低,实时性差但是逻辑简单。
因此对于服务器这种实时性要求高,同时处理多个客户请求的应用程序应该将同步编程和异步编程结合来用。
因此引入了半同步/半异步模式如下:
在上图中异步线程用来处理IO事件(IO处理单元)、同步线程用来处理客户逻辑(逻辑单元)。
异步线程监听到客户请求之后就将其封装成请求对象并插入请求队列,请求队列通知某个工作在同步模式的工作线程读取数据并做相应的处理。选取工作线程可以顺序选取也可以随机选取。
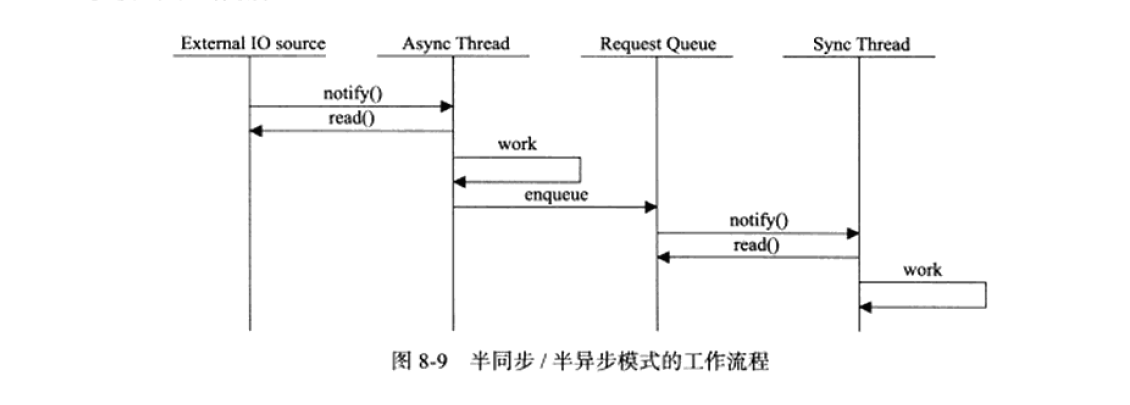
上面是最简单的一个模型,是最基础的,如果考虑两种事件模式和几种IO模型的话就存在很多变体,我们今天主要两个,半同步/半反应堆模式和高效的半同步/异步模式
-
半同步/半反应堆模式
主线程作为异步线程,负责监听所有socket上的事件。如果监听到socket上有可读事件发生同时是未连接的socket,就接受新连接的socket,然后往epoll内核事件表中注册该socket上的读写事件。如果是已经连接的socket上有读写事件发生,即有新的客户请求到来或者有数据要发送给对端,主线程就将该连接的socket插入请求队列,从队列中选取一个工作线程处理任务
上图采用的事件处理模式是Reactor模式,工作线程自己从socket上读取客户请求和往socket中写入服务器应答。
半同步/半反应堆模式缺点:
- 主线程和工作线程共享请求队列。这样需要对请求队列加锁,耗费CPU时间
- 每个工作线程同一时间只能处理一个请求。如果客户数多,而工作线程较少则会在队列中堆积很多对象导致客户端响应速度变慢。如果通过增加线程数来解决这一问题,则工作线程的切换也耗费大量CPU时间
-
高效的半同步/异步模式
和半同步/半反应堆模式不同的是主线程仅仅监听socket,而连接socket由工作线程去管理。当有新连接到来时,主线程就接受该连接同时将返回的socket连接发送给某个工作线程,此后该socket上的任何IO操作都由工作线程处理,直到客户端连接关闭。主线程向工作线程派发socket的最简单的方式就是向管道里面写数据。工作线程检测到管道有数据可读时候,就分析是否是新的客户连接到来,如果是就将新的socket上的读写事件注册到自己的epoll内核事件表中。
可以看到上图中每个线程(主线程和工作线程)都维持自己的事件循环,他们各自独立的监听不同的事件,在上图中每个线程都工作在异步模式。


多个工作线程轮流获得事件源集合,轮流监听、分发并处理事件的一种模式。在任意时间点程序都只有一个领导者线程,负责监听IO事件。而其他线程则都是追随者,她们休眠在线程池中等待成为新的领导者。当前的领导者如果检测到IO事件,首先从线程池中选出新的领导者,再去处理IO事件。然后新的领导者等待新的IO事件,原来的领导者则处理到来的IO事件,实现并发。
包含句柄集(HandleSet)、线程集(ThreadSet)、事件处理器(EventHandler)、具体事件处理器(ConcreteEventHandler)
以空间换时间,池是一组资源的集合,这组资源在服务器启动之初就被创建出来并初始化,成为静态资源分配。当服务器正式运行,从池中直接获取相关资源,无需动态分配,这样速度会很快。池相当于服务器管理系统资源的应用层设施,避免了服务器对内核的频繁访问。
内存池、进程池、线程池、连接池等
高性能服务器应该要避免不必要的数据复制,尤其当数据复制发生在用户代码和内核之间的时候。
如果内核直接处理从socket或者文件读入的数据,则应用程序就没必要将这些数据从内核缓冲区复制到应用程序缓冲区中。(直接处理指的是应用程序不关心数据内容)
此外用户代码内部的复制也应该避免,比如两个工作进程之间传递大量消息的时候,可以考虑使用共享内存的方式去实现。
并发程序必须考虑上下文切换,即进程切换或者线程切换导致的系统开销,切换会占用CPU的时间,进而服务器用于处理业务逻辑的时间就会显得不足。
第二个就是锁,由于共享资源的原因,加锁时必要的,但是加锁会导致效率低下,因为引入的代码不仅不会对业务逻辑有帮助,而且会访问内核。
IO 多路转接也称为 IO 多路复用,它是一种网络通信的手段(机制),通过这种方式可以同时监测多个文件描述符并且这个过程是阻塞的,一旦检测到有文件描述符就绪( 可以读数据或者可以写数据)程序的阻塞就会被解除,之后就可以基于这些(一个或多个)就绪的文件描述符进行通信了。通过这种方式在单线程 / 进程的场景下也可以在服务器端实现并发。常见的 IO 多路转接方式有:select、poll、epoll。下面将多线程多进程编程和IO多路复用做一个对比:
-
IO多路复用
使用相关函数委托内核检测服务器端所有的文件描述符(通信和监听两大类),这个检测过程会导致进程/线程阻塞,如果检测到已就绪的文件描述符则解除阻塞,并且将已就绪的文件描述符都传出以供使用。传出的文件描述符有两类:
- 监听的文件描述符,主要和客户端建立连接。此时如果调用accept是不会被阻塞,因为监听的文件描述符是已就绪的。
- 通信的文件描述符,调用通信函数和已建立连接的客户端通信。由于文件描述符检测到有读写资源,表明通信的文件描述符就绪,不会阻塞程序,读缓冲内有数据可以读出,写缓冲区不满可以往里面写数据。
对这些文件描述符进行下一轮的检测,循环往复
-
多进程,多线程编程
- 主进程调用accept检测客户端连接请求。如果没有新的客户连接,当前父进程会阻塞。如果有新的客户端连接请求就会接触阻塞然后建立连接。
- 子进程主要是和建立连接后的客户端进行通信。调用 read() / recv() 接收客户端发送的通信数据,如果没有通信数据,当前线程 / 进程会阻塞,数据到达之后阻塞自动解除。调用 write() / send() 给客户端发送数据,如果写缓冲区已满,当前线程 / 进程会阻塞,否则将待发送数据写入写缓冲区中
select函数的优点是跨平台的,在三大操作系统中都是支持的。通过调用该函数可以委托内核帮我们检测若干文件描述符的状态,本质上就是检测这些文件描述符对应的读写缓冲区的状态:
- 读缓冲区,检测里面是否包含数据,如果有数据则表明对应的文件描述符就绪
- 写缓冲区,检测写缓冲区是否可以写,如果有容量可以写,缓冲区对应的文件描述符就绪
- 读写异常,检测读写缓冲区是否有异常,如果有则该缓冲区对应的文件描述符就绪
使用select函数将委托的文件描述符遍历完毕后,满足条件的文件描述符就会通过select函数的三个参数(表示三个集合)传出,然后根据集合中的文件描述符来处理。
函数原型如下:
#include <sys/select.h>
int select(int nfds, fd_set *readfds, fd_set *writefds,fd_set *exceptfds, struct timeval * timeout);函数参数详解:
-
nfds参数指定被监听的文件描述符的总数,通常被设置为select监听的所有文件描述符中的最大值+1,因为描述符是从0开始的。内核需要线性遍历集合中的文件描述符
-
readfds:可读的文件描述符的集合,内核检测集合中对应文件描述符的读缓冲区。读集合一般都是需要检测的,这样才知道哪个文件描述符接收到了数据
writefds:可写的文件描述符的集合,内核检测集合中对应文件描述符的写缓冲区,如果不需要该参数可以穿个NULL进去。
exceptfds:内核检测文件描述符是否有异常状态,不需要改参数可以传NULL
fd_set结构体仅包含一个整型数组,数组中的每个元素的每一位(bit)标记了一个文件描述符。fd_set能够容纳的文件描述符数量由FD_SETSIZE执行,因此这样就限制了select能同时处理的文件描述符的总量
由于位操作比较频繁,因此使用下面的宏来访问fd_set结构体中的位:
// 将文件描述符fd从set集合中删除 == 将fd对应的标志位设置为0 void FD_CLR(int fd, fd_set *set); // 判断文件描述符fd是否在set集合中 == 读一下fd对应的标志位到底是0还是1 int FD_ISSET(int fd, fd_set *set); // 将文件描述符fd添加到set集合中 == 将fd对应的标志位设置为1 void FD_SET(int fd, fd_set *set); // 将set集合中, 所有文件文件描述符对应的标志位设置为0, 集合中没有添加任何文件描述符 void FD_ZERO(fd_set *set);
-
timeout:设置select函数的超时时间。他是一个timeval结构类型的指针,采用指针是因为内核会修改该参数然后通知应用程序select等待了多久。不能完全信任该值因为调用失败后返回的值是不确定的
#include <sys/select.h> struct timeval { time_t tv_sec; /* seconds */ suseconds_t tv_usec; /* microseconds */ };
fd_set这个文件描述符集合的大小是128字节,也就是有1024个标志位,和内核中文件描述符表中的文件描述符个数一样的,这不是巧合,因为fd_set中的每一个bit和文件描述符表中的每一个文件描述符是一一对应的关系
下图是fd_set委托内核检测读缓冲区文件描述符集合

内核在遍历读集合的过程中,如果被检测的文件描述符对应的读缓冲区没有数据,内核将修改文件描述符在fd_set的标志位,改为0,如果有数据则为1
文件描述符就绪的条件:
- 内核接收缓冲区的字节数大于或等于其低水位标记SO_RCVLOWAT,此时可以无阻塞的读取socket,并且读操作返回的字节数大于0。内核发送缓冲区的可用字节数大于或等于其低水位标记SO_SNDLOWAT,可以无阻塞的写该socket。
- 监听socket上有新的连接请求(可读)
- socket上有未处理的错误(可读),用getsockopt来读取和清除该错误。
- socket使用非阻塞connect连接成功或者失败
网络程序中select能处理的异常情况只有一种,socket上接收到带外数据。
epoll使用一组函数来完成任务,而不是单个函数。
epoll把用户关心的文件描述符上的事件放在内核里的一个事件表中,从而不用像select那样每次调用都需要重复传入文件描述符集合。
但是epoll需要一个额外的文件描述符来唯一标识内核中的事件表,用epoll_create函数创建。
epoll中一共有三个函数,分别处理不同的操作:
#include <sys/epoll.h>
// 创建epoll实例,通过一棵红黑树管理待检测集合
int epoll_create(int size);
// 管理红黑树上的文件描述符(添加、修改、删除)
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
// 检测epoll树中是否有就绪的文件描述符
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
struct epoll_event {
uint32_t events; /* Epoll 事件 */
epoll_data_t data; /* 用户数据 */
};
// 联合体, 多个变量共用同一块内存
typedef union epoll_data {
void *ptr;
int fd; // 通常情况下使用这个成员, 和epoll_ctl的第三个参数相同即可
uint32_t u32;
uint64_t u64;
} epoll_data_t;-
int epoll_create(int size);size参数不起作用,只是提示内核事件表需要多大,大于0即可
失败返回-1
成功返回一个有效的文件描述符,通过这个文件描述符就可以访问创建的epoll实例了
-
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event)- epfd就是epoll_create()函数的返回值,找到相应的epoll实例
- op,是一个枚举值,指定函数的操作类型,有如下几个
EPOLL_CTL_ADD:往 epoll 模型中添加新的节点EPOLL_CTL_MOD:修改 epoll 模型中已经存在的节点EPOLL_CTL_DEL:删除 epoll 模型中的指定的节点
- fd是文件描述符,即要进行op操作的文件描述符
- event,epoll事件,用来修饰第三个参数对应的文件描述符,检测这个文件描述符是什么事件
EPOLLIN:读事件,接收数据,检测读缓冲区,如果有数据该文件描述符就绪EPOLLOUT:写事件,发送数据,检测写缓冲区,如果可写该文件描述符就绪EPOLLERR:异常事件- data:用户数据变量,这是一个联合体类型,通常情况下使用里边的 fd 成员,用于存储待检测的文件描述符的值,在调用 epoll_wait() 函数的时候这个值会被传出。
-
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout)检测创建的 epoll 实例中有没有就绪的文件描述符。
- epfd,epoll_create () 函数的返回值,通过这个参数找到 epoll 实例
- events,传出参数,这是一个结构体数组的地址,里边存储了已就绪的文件描述符的信息
- maxevents,修饰第二个参数,结构体数组的容量(元素个数)
- timeout,如果检测的 epoll 实例中没有已就绪的文件描述符,该函数阻塞的时长,单位 ms 毫秒
接下来看一下epoll的使用:
//创建epoll实例对象
int epfd = epoll_create(100);
//将用于监听的套接字添加到epoll实例中
struct epoll_event ev;
ev.events = EPOLLIN; // 检测lfd读读缓冲区是否有数据
ev.data.fd = lfd; //lfd即socket创建的
int ret = epoll_ctl(epfd, EPOLL_CTL_ADD, lfd, &ev);
//检测添加到epoll实例中的文件描述符是否已就绪,并将这些已就绪的文件描述符进行处理
int num = epoll_wait(epfd, evs, size, -1);
//如果是监听的文件描述符,和新客户端建立连接,将得到的文件描述符添加到epoll实例中
int cfd = accept(curfd, NULL, NULL);
ev.events = EPOLLIN;
ev.data.fd = cfd;
epoll_ctl(epfd, EPOLL_CTL_ADD, cfd, &ev); // 新得到的文件描述符添加到epoll模型中, 下一轮循环的时候就可以被检测了
//如果是通信的文件描述符,和对应的客户端通信,如果连接已断开,将该文件描述符从epoll实例中删除
int len = recv(curfd, buf, sizeof(buf), 0);
if(len == 0)
{
// 将这个文件描述符从epoll模型中删除
epoll_ctl(epfd, EPOLL_CTL_DEL, curfd, NULL);
close(curfd);
}
else if(len > 0)
{
send(curfd, buf, len, 0);
}select/poll 低效的原因之一是将 “添加 / 维护待检测任务” 和 “阻塞进程 / 线程” 两个步骤合二为一。每次调用 select 都需要这两步操作,然而大多数应用场景中,需要监视的 socket 个数相对固定,并不需要每次都修改。epoll 将这两个操作分开,先用 epoll_ctl() 维护等待队列,再调用 epoll_wait() 阻塞进程(解耦)。通过下图的对比显而易见,epoll 的效率得到了提升。
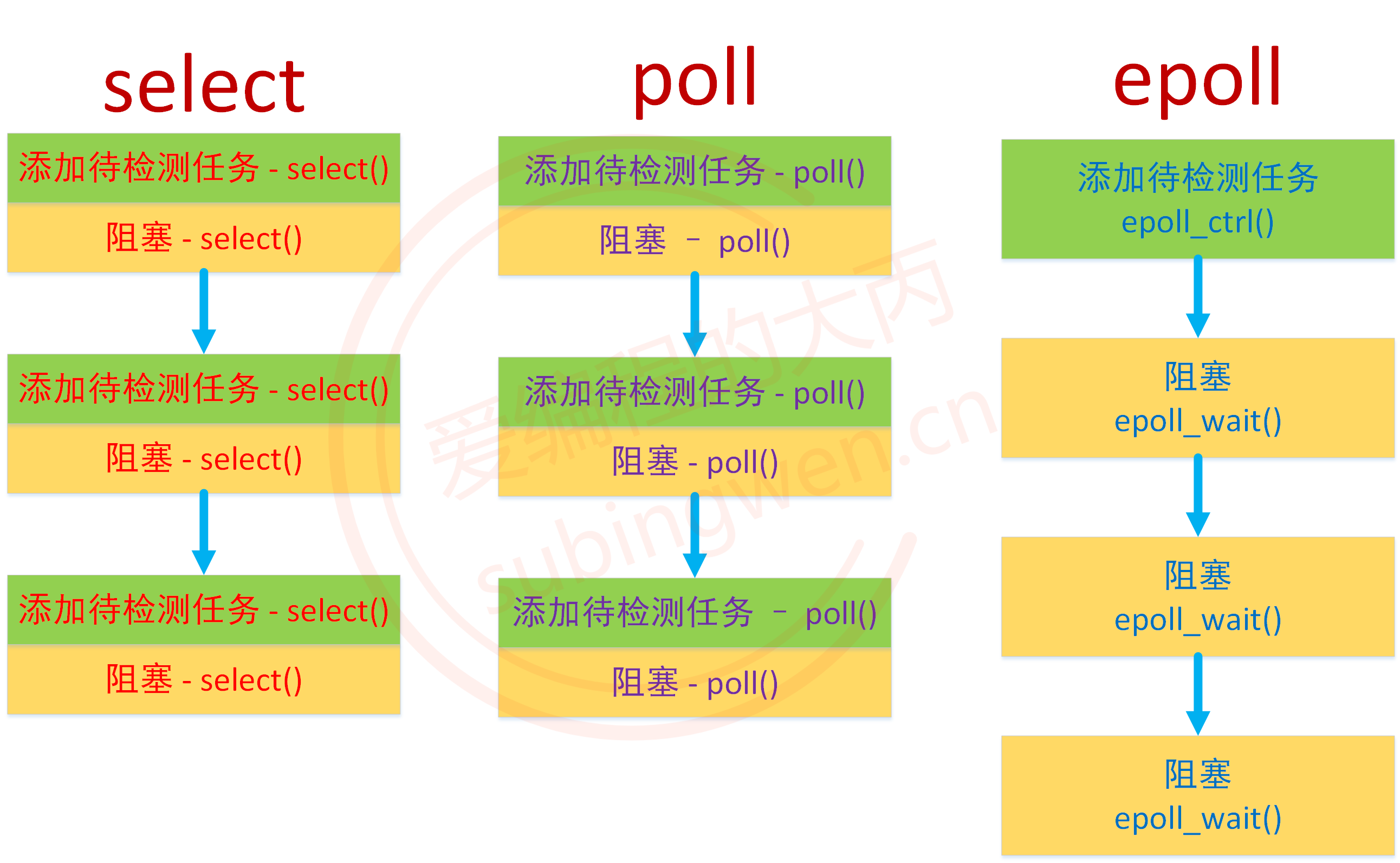

epoll工作模式:
-
水平模式LT(level triggered)
是缺省的工作方式,并且同时支持block和no-block socket。在这种做法中,内核通知使用者哪些文件描述符已经就绪,之后就可以对这些已就绪的文件描述符进行 IO 操作了。如果我们不作任何操作,内核还是会继续通知使用者。
特点如下:
- 读事件。如果文件描述符对应的读缓冲区还有数据,读事件就会被触发,epoll_wait () 解除阻塞后,就可以接收数据了。如果接收数据的 buf 很小,不能全部将缓冲区数据读出,那么读事件会继续被触发,直到数据被全部读出,如果接收数据的内存相对较大,读数据的效率也会相对较高(减少了读数据的次数)。因为读数据是被动的,必须要通过读事件才能知道有数据到达了,因此对于读事件的检测是必须的
- 写事件。如果文件描述符对应的写缓冲区可写,写事件就会被触发,epoll_wait () 解除阻塞后,之后就可以将数据写入到写缓冲区了,写事件的触发发生在写数据之前而不是之后,被写入到写缓冲区中的数据是由内核自动发送出去的 如果写缓冲区没有被写满,写事件会一直被触发 因为写数据是主动的,并且写缓冲区一般情况下都是可写的(缓冲区不满),因此对于写事件的检测不是必须的
-
边沿模式ET(edge-triggered)
是高速工作方式,只支持no-block socket。在这种模式下,当文件描述符从未就绪变为就绪时,内核会通过epoll通知使用者。然后它会假设使用者知道文件描述符已经就绪,并且不会再为那个文件描述符发送更多的就绪通知(only once)。如果我们对这个文件描述符做 IO 操作,从而导致它再次变成未就绪,当这个未就绪的文件描述符再次变成就绪状态,内核会再次进行通知,并且还是只通知一次。ET模式在很大程度上减少了epoll事件被重复触发的次数,因此效率要比LT模式高。
特点如下:
- 读事件。当读缓冲区有新的数据进入,读事件被触发一次,没有新数据不会触发该事件,如果有新数据进入到读缓冲区,读事件被触发,epoll_wait () 解除阻塞,读事件被触发,可以通过调用 read ()/recv () 函数将缓冲区数据读出,如果数据没有被全部读走,并且没有新数据进入,读事件不会再次触发,只通知一次,如果数据被全部读走或者只读走一部分,此时有新数据进入,读事件被触发,并且只通知一次
- 写事件。当写缓冲区状态可写,写事件只会触发一次,如果写缓冲区被检测到可写,写事件被触发,epoll_wait () 解除阻塞,写事件被触发,就可以通过调用 write ()/send () 函数,将数据写入到写缓冲区中,写缓冲区从不满到被写满,期间写事件只会被触发一次,写缓冲区从满到不满,状态变为可写,写事件只会被触发一次.
epoll 的边沿模式下 epoll_wait () 检测到文件描述符有新事件才会通知,如果不是新的事件就不通知,通知的次数比水平模式少,效率比水平模式要高。
epoll 在边沿模式下,必须要将套接字设置为非阻塞模式
对于写事件的触发一般情况下是不需要进行检测的,因为写缓冲区大部分情况下都是有足够的空间可以进行数据的写入。对于读事件的触发就必须要检测了,因为服务器也不知道客户端什么时候发送数据,如果使用 epoll 的边沿模式进行读事件的检测,有新数据达到只会通知一次,那么必须要保证得到通知后将数据全部从读缓冲区中读出。那么,应该如何读这些数据呢?
-
准备一块特别大的内存,用于存储从读缓冲区中读出的数据,但是这种方式有很大的弊端:首先内存的大小没有办法界定,太大浪费内存,太小又不够用。其次系统能够分配的最大堆内存也是有上限的,栈内存就更不必多言了
-
循环接收数据。
int len = 0; while((len = recv(curfd, buf, sizeof(buf), 0)) > 0) { // 数据处理... }
这样做也是有弊端的,因为套接字操作默认是阻塞的,当读缓冲区数据被读完之后,读操作就阻塞了也就是调用的 read()/recv() 函数被阻塞了,当前进程 / 线程被阻塞之后就无法处理其他操作了。
要解决阻塞问题,就需要将套接字默认的阻塞行为修改为非阻塞,需要使用 fcntl() 函数进行处理
通过上述分析就可以得出一个结论:epoll 在边沿模式下,必须要将套接字设置为非阻塞模式,但是,这样就会引发另外的一个 bug,在非阻塞模式下,循环地将读缓冲区数据读到本地内存中,当缓冲区数据被读完了,调用的 read()/recv() 函数还会继续从缓冲区中读数据,此时函数调用就失败了,返回 - 1,对应的全局变量 errno 值为 EAGAIN 或者 EWOULDBLOCK 如果打印错误信息会得到如下的信息:Resource temporarily unavailable
select函数的参数类型fd_set没有将文件描述符和事件绑定,它仅仅是一个文件描述符集合,因此select函数需要三个参数来帮助识别读、写、异常事件。这使得select不能处理更多类型的事件,同时由于内核对fd_set的在线修改,应用程序下一次调用select会重置这三个fd_set集合。
epoll采用与select和poll完全不同的方式来管理用户注册的事件,它在内核中维护了一个事件表,并提供了一个独立的系统调用epoll_ctl来控制往其中添加、删除、修改事件。这样每次epoll_wait都直接从该内核事件表中取得用户注册的事件,而不用反复从用户空间读入这些事件。epoll_wait系统调用的events参数仅用来返回就绪事件,使得应用程序索引就绪文件描述符的时间复杂度为O(1)。而select和poll调用都返回整个用户注册的事件集合。
select和poll都只能工作在相对低效的LT模式,而epoll可以工作在ET高效模式,同时epoll还支持EPOLLONESHOT事件,进一步减少可读、可写和异常事件
重点:从实现原理上说select和poll采用的都是轮询的方式,即每次调用都要扫描整个注册文件描述符集合,并将就绪的文件描述符返还给用户程序,因此检测就绪算法的时间复杂度是O(n)。epoll_wait采用回调方式,内核检测到就绪文件描述符时就出发回调函数,回调函数会将该文件描述符上对应的事件插入内核就绪队列,然后内核在适当的时机将该就绪队列中的内容拷贝到用户空间。因此epoll_wait不用轮询整个文件描述符集来查找哪个事件已经就绪,算法时间复杂度是O(1)。当活动连接比较多的时候,select和poll未必比epoll高,因为此时回调函数会触发的比较频繁,因此epoll_wait适用于连接多但是活跃连接少的情况。
poll实现
客户端有以下两个功能:
- 从标准输入终端读入用户数据,并将用户数据发送到服务器
- 在输出终端打印服务器发送的数据
服务器功能是:接受客户数据,并把客户数据发送给每一个登录到该服务器上的客户端
#include<iostream>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <assert.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
#include <poll.h>
#include <fcntl.h>
#define _GNU_SOURCE 1
#define BUFFER_SIZE 64
int main(int argc, char* argv[]){
if(argc <= 2){
printf("usage: %s ip_address port\n", basename(argv[0]));
return 1;
}
const char* ip = argv[1];
int port = atoi(argv[2]);
struct sockaddr_in server_address;
//bzero函数,将字符串s的前n个字节置为0,一般来说n通常取sizeof(s),将整块空间清零
bzero(&server_address, sizeof(server_address));
server_address.sin_family = AF_INET;
inet_pton(AF_INET, ip, &server_address.sin_addr);
server_address.sin_port = htons(port);
int sockfd = socket(PF_INET, SOCK_STREAM, 0);
printf("sockfd:%d\n",sockfd);
int conn_status = connect(sockfd, (struct sockaddr*)&server_address, sizeof(server_address));
printf("conn_status:%d\n",conn_status);
if( conn_status < 0){
printf("connect failed!,erron:%d\n");
close(sockfd);
return 1;
}
//连接成功,注册描述符sockfd和0(标准输入)的可读事件
pollfd fds[2];
fds[0].fd = 0;
fds[0].events = POLLIN;
fds[0].revents = 0;
fds[1].fd = sockfd;
//#define _GNU_SOURCE 1
fds[1].events = POLLIN | POLLRDHUP;
fds[1].revents = 0;
short temp = POLLIN | POLLRDHUP;
std::cout<<" POLLIN | POLLRDHUP :" << temp <<std::endl;
char read_buf[BUFFER_SIZE];
int pipefd[2];
int ret = pipe(pipefd);
while(1){
//-1表示poll永远不会超时
ret = poll(fds, 2, -1);
//小于0出错
if(ret < 0){
printf("poll failed!\n");
break;
}
if(fds[1].revents & POLLRDHUP){
printf("fds[1].revents:%d", fds[1].revents);
printf("server close the connection\n");
break;
}
else if(fds[1].revents & POLLIN){
printf("fds[1].revents:%d", fds[1].revents);
memset(read_buf, '\0', BUFFER_SIZE);
recv(fds[1].fd, read_buf, BUFFER_SIZE -1, 0);
printf("receive msg:%s\n", read_buf);
}
if(fds[0].revents & POLLIN){
//标准输入→管道写端
ret = splice(0, NULL, pipefd[1], NULL, 32768, SPLICE_F_MORE | SPLICE_F_MOVE);
//管道读端→sockfd文件描述符,发送给服务器
ret = splice(pipefd[0], NULL, sockfd, NULL, 32768, SPLICE_F_MORE | SPLICE_F_MOVE);
}
}
close(sockfd);
return 0;
}#include <iostream>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <stdio.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <fcntl.h>
#include <stdlib.h>
#include <poll.h>
#define _GNU_SOURCE 1
#define USER_LIMIT 5 /*最大用户数量*/
#define BUFFER_SIZE 64 /*读缓冲区大小*/
#define FD_LIMIT 65535 /*文件描述符限制*/
struct client_data
{
/* data */
sockaddr_in address;
char* write_buf;
char buf[BUFFER_SIZE];
};
int set_no_blocking(int fd){
//取得文件描述符filedes的文件状态标志。
int old_option = fcntl(fd, F_GETFL);
int new_option = old_option | O_NONBLOCK;
printf("old_option:%d\n", old_option);
printf("new_option:%d\n", new_option);
fcntl(fd, F_SETFL, new_option);
return old_option;
}
int main(int argc, char* argv[]){
//const char* ip = argv[1];
printf("argc num:%d\n",argc);
int port = atoi(argv[1]);
printf("port:%s\n", argv[1]);
int ret = 0;
struct sockaddr_in address;
bzero(&address, sizeof(address));
address.sin_family = AF_INET;
//inet_pton(AF_INET, ip, &address.sin_addr);
address.sin_addr.s_addr = htonl(INADDR_ANY);
address.sin_port = htons(port);
int listenfd = socket(PF_INET, SOCK_STREAM, 0);
ret = bind(listenfd, (struct sockaddr*)&address, sizeof(address));
if(ret == -1){
printf("bind error!\n");
}
ret = listen(listenfd, 5);
if(ret == -1){
printf("listen error!\n");
}
printf("listenning...., listen fd:%d\n",listenfd);
client_data* users = new client_data[FD_LIMIT];
pollfd fds[USER_LIMIT + 1];
int user_counter = 0;
for(int i = 1; i <= USER_LIMIT; i++){
fds[i].fd = -1;
fds[i].events = 0;
}
fds[0].fd = listenfd;
fds[0].events = POLLIN | POLLERR;
fds[0].revents = 0;
while(1){
ret = poll(fds, user_counter + 1, -1);
if(ret < 0){
printf("poll failed!\n");
break;
}
for(int i = 0; i < user_counter + 1; i++){
if(fds[i].fd == listenfd && fds[i].revents & POLLIN){
printf("linsten fd, fds[%d].revents:%x", i, fds[i].revents & POLLIN);
struct sockaddr_in client_adress;
socklen_t clinet_addr_len = sizeof(client_adress);
int connectfd = accept(listenfd, (struct sockaddr*)&client_adress, &clinet_addr_len);
if(connectfd < 0){
printf("erro:%d\n", errno);
continue;
}
//连接太多处理
if(user_counter >= USER_LIMIT){
const char* info = "too many users!\n";
printf("%s", info);
send(connectfd, info, strlen(info), 0);
close(connectfd);
continue;
}
user_counter++;
users[connectfd].address = client_adress;
set_no_blocking(connectfd);
fds[user_counter].fd = connectfd;
fds[user_counter].events = POLLIN | POLLRDHUP | POLLERR;
fds[user_counter].revents = 0;
printf("already have %d users!\n", user_counter);
}
else if(fds[i].revents & POLLERR){
printf("have an error from %d\n",fds[i].fd);
char errors[100];
memset(errors, '\0', 100);
socklen_t len = sizeof(errors);
if(getsockopt(fds[i].fd, SOL_SOCKET, SO_ERROR, &errors, &len) < 0){
printf("get socket option failed\n");
}
continue;
}
else if(fds[i].revents & POLLRDHUP){
users[fds[i].fd] = users[fds[user_counter].fd];
close(fds[i].fd);
fds[i] = fds[user_counter];
i--;
user_counter--;
printf("a client left!\n");
}
else if(fds[i].revents & POLLIN){
printf("have data from client, fds[%d].revents & POLLIN is :%x\n", i ,fds[i].revents & POLLIN);
printf("fds[i].revents:%x\n", fds[i].revents);
printf("fds[i].revents & POLLERR : %x\n", fds[i].revents & POLLERR);
printf("fds[i].revents & POLLRDHUP : %x\n", fds[i].revents & POLLRDHUP);
printf("fds[i].revents & POLLIN : %x\n", fds[i].revents & POLLIN);
int connnectfd = fds[i].fd;
memset(users[connnectfd].buf, '\0', BUFFER_SIZE);
ret = recv(connnectfd, users[connnectfd].buf, BUFFER_SIZE -1 , 0);
printf("get %d bytes of client data from %d\n", ret, connnectfd);
printf("data:%s\n", users[connnectfd].buf);
if(ret < 0){
close(connnectfd);
users[fds[i].fd] = users[fds[user_counter].fd];
fds[i] = fds[user_counter];
i--;
user_counter--;
}
for(int j = 1; j <= user_counter; j++){
if(fds[j].fd == connnectfd){
continue;
}
fds[j].events |= ~POLLIN;
fds[j].events |= POLLOUT;
users[fds[j].fd].write_buf = users[connnectfd].buf;
}
}
else if(fds[i].revents & POLLOUT){
int connfd = fds[i].fd;
if(!users[connfd].write_buf){
continue;
}
ret = send(connfd, users[connfd].write_buf, strlen(users[connfd].write_buf), 0);
users[connfd].write_buf = NULL;
fds[i].events |= ~POLLOUT;
fds[i].events |= POLLIN;
}
}
}
delete [] users;
close(listenfd);
return 0;
}在实际应用中服务器程序能够同时监听多个端口。
从bind系统调用参数来看,一个socket只能够与一个socket地址绑定,只能监听一个端口。因此要监听多个端口就必须创建多个socket,并绑定到各个端口上。
另外,即使是同一个端口,如果服务器要处理端口上的TCP和UDP请求,也需要创建两个不同的socket,一个流socket,一个数据报socket,并绑定到端口上。
下面代码是一个同时处理TCP和UDP请求的回射服务器!
#include<stdio.h>
#include<fcntl.h>
#include<unistd.h>
#include<sys/epoll.h>
#include<stdlib.h>
#include<libgen.h>
#include<sys/types.h>
#include<sys/socket.h>
#include<netinet/in.h>
#include<errno.h>
#include<pthread.h>
#include<arpa/inet.h>
#include<string.h>
#define MAX_EVENT_NUMBER 1024
#define TCP_BUFFER_SIZE 512
#define UDP_BUFFER_SIZE 1024
int set_no_blocking(int fd){
int old_option = fcntl(fd, F_GETFL);
int new_option = old_option | O_NONBLOCK;
fcntl(fd, F_SETFL, new_option);
return old_option;
}
void addfd(int epollfd, int fd){
epoll_event event;
event.data.fd = fd;
event.events = EPOLLIN | EPOLLET;
epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event);
set_no_blocking(fd);
}
int main(int argc, char* argv[]){
if(argc <= 2){
printf("usage: %s port \n", basename(argv[0]));
return 1;
}
int port = atoi(argv[1]);
int ret = 0;
struct sockaddr_in adress;
bzero(&adress, sizeof(adress));
adress.sin_family = AF_INET;
adress.sin_addr.s_addr = htonl(INADDR_ANY);
adress.sin_port = htons(port);
/*instruct tcp socket, and bind*/
int listenfd = socket(PF_INET, SOCK_STREAM, 0);
if(bind(listenfd, (struct sockaddr*)&adress, sizeof(adress)) == -1){
printf("bind() error!\n");
}
if(listen(listenfd, 5) == -1){
printf("listen() error!");
}
/*instruct udp socket, and bind*/
bzero(&adress, sizeof(adress));
adress.sin_family = AF_INET;
adress.sin_addr.s_addr = htonl(INADDR_ANY);
adress.sin_port = htons(port);
int udpfd = socket(PF_INET, SOCK_DGRAM, 0);
if(bind(udpfd, (struct sockaddr*)&adress, sizeof(adress)) == -1){
printf("bind() error!\n");
}
epoll_event events[MAX_EVENT_NUMBER];
int epollfd = epoll_create(5);
/*register TCP and UDP socket about read event*/
addfd(epollfd, listenfd);
addfd(epollfd, udpfd);
while(1)
{
int number = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1);
if(number < 0){
printf("epoll failed!\n");
break;
}
for(int i = 0; i < number; i++){
int sockfd = events[i].data.fd;
if(sockfd == listenfd){
struct sockaddr_in client_address;
socklen_t len = sizeof(client_address);
int connfd = accept(listenfd, (struct sockaddr*)&client_address, &len);
addfd(epollfd, connfd);
}
else if(sockfd == udpfd){
char buf[UDP_BUFFER_SIZE];
memset(buf, '\0', UDP_BUFFER_SIZE);
struct sockaddr_in client_addresss;
socklen_t len = sizeof(client_addresss);
ret = recvfrom(udpfd, buf, UDP_BUFFER_SIZE -1, 0, (struct sockaddr*)&client_addresss, &len);
if(ret > 0){
sendto(udpfd, buf, UDP_BUFFER_SIZE-1, 0, (struct sockaddr*)&client_addresss, len);
}
}
else if(events[i].events & EPOLLIN){
char buf[TCP_BUFFER_SIZE];
while(1){
memset(buf, '\0', TCP_BUFFER_SIZE);
ret = recv(sockfd, buf, TCP_BUFFER_SIZE-1, 0);
if(ret < 0){
if(errno == EAGAIN || errno == EWOULDBLOCK){
break;
}
close(sockfd);
break;
}
else if(ret == 0){
close(sockfd);
}else{
send(sockfd, buf, ret, 0);
}
}
}
else{
printf("lalalla!\n");
}
}
}
close(listenfd);
return 0;
}信号是由用户,系统或者进程发送给目标进程的信息,用来通知目标进程某个状态的改变或系统异常。Linux信号有以下条件产生:
- 对于前台进程,通过用户输入的某些字符产生信号,比如
Ctrl+C- 系统异常,比如除以零
- 系统状态变化。比如alarm定时器到期引起SIGALRM信号
- 运行kill命令或者调用kill函数。
Linux下一个进程给其他进程发送信号的API是kill函数
#include <sys/types.h>
#include <signal.h>
// sig:信号;pid:目标进程
// 该函数成功时返回0,失败时返回-1并设置errno
int kill(pid_t pid, int sig);目标进程收到信号后,需要定义一个接收函数来处理,信号处理函数原型如下:
#include <signal.h>
typedef void (*__sighandler_t) (int);这个是用户自定义的信号处理函数。除了自定义也可以用系统指定的:
#include <bits/signum.h>
#define SIG_DFL ((__sighandler_t) 0) //忽略目标信号
#define SIG_IGN ((__sighandler_t) 1) //使用信号的默认处理方式信号的默认处理方式主要有:
- Term:结束进程
- Ign:忽略信号
- Core:结束进程并生成核心转储文件
- Stop:暂停进程
- Cont:继续进程
-
SIGHUP
当挂起进程的控制终端时,SIGHUP信号会被触发,这个信号的默认行为是Term(结束进程)
对于没有控制终端的网络后台程序而言,他们通常利用SIGHUP信号来强制服务器重读配置文件
例如xinetd超级服务器程序,在接收到SIGHUP信号之后将调用hard_config函数,循环读取/etc/xinted.d/目录下的每个子配置文件,并检测其变化。如果某个正在运行的子服务的配置文件被修改以停止服务,则xinetd主进程将给该子服务进程发送SIGTERM信号结束他。如果某个子服务的配置文件被修改以开启服务,则xinetd将创建新的socket并且绑定到该服务对应的端口上
-
SIGPIPE
默认情况下,往一个读端关闭的管道或socket连接中写数据将引发SIGPIPE信号,我们在代码中应该捕获处理它,或至少忽略它,因为它的默认行为是结束进程,我们肯定不希望错误的写操作导致程序退出。
-
SIGURG
Linux环境下,内核通知应用程序带外数据到达主要有两种方法:一种是I/O复用技术,select等系统调用在接收到带外数据时将返回并报告socket上的异常事件,另外一种是使用SIGURG信号。SIGURG的默认行为是Ign。
我的理解是这个系统调用函数将信号和信号处理函数集合到一起,即调用该信号函数就可以指定信号和该信号对应的信号处理函数。
主要有signal和sigaction两个
#include <signal.h>
// sig:指出要捕获的信号类型,_handler用于指定信号sig的处理函数
// 成功时返回类型为_sighandler_t的函数指针,错误返回SIG_ERR并设置errno
_sighandler_t signal(int sig, _sighandler_t _handler);
// 更健壮的信号处理函数接口
// sig:要捕获的信号类型;act:制定新的信号处理方式;oact:输出信号前的处理方式
int sigaction(int sig, const struct sigaction* act, struct sigaction* oact);
// sigaction结构体定义:
struct sigaction{
#ifdef __USE_POSIX199309
union{
_sighandler_t sa_handler;
void(*sa_sigaction)(int, siginfo_t*, void*);
}
_sigaction_handler;
# define sa_handler __sigaction_handler.sa_handler
# define sa_sigaction __sigatcion_handler.sa_sigaction
#else
_sighandler_t sa_handler;
#endif
_sigset_t sa_mask;
int sa_flags;
void(*sa_restorer)(void);
};Linux使用数据结构sigset_t来表示一组信号
#include <bits/sigset.h>
#include <signal.h>
// Linux用数据结构sigset_t来表示一组信号
#define _SIGSET_NWORDS (1024/(8*sizeof(unsigned long int)))
typedef struct{
unsigned long int __val[_SIGSET_NWORDS];
} __sigset_t;
//提供一组函数来设置、修改、查询、删除信号集
int sigemptyset(sigset_t* _set); // 清空信号集
int sigfillset(sigset_t* _set); // 在信号集中设置所有信号
int sigaddset(sigset_t* _set, int _signo); // 将信号_signo添加至信号集中
int sigdelset(sigset_t* _set, int _signo); // 将信号_signo从信号集中剔除
int sigismember(_const sigset_t*, int _signo); // 测试_signo是否在信号集中可以根据代码看到sigset_t实际是一个长整型数组,数组每个元素的每个位表示一个信号。还记得之前的fd_set吗,跟那个可想
信号是一种异步事件:信号处理函数和程序的主循环是两条不同的执行路线。信号处理函数需要尽可能快地执行完毕,以确保该信号不被屏蔽太久。
其典型解决方案是:把信号的主要处理逻辑放到程序的主循环中,当信号处理函数被触发时,它只是简单的通知主循环程序接收信号,并将信号值传递给主循环。主循环再根据接收到的信号值执行目标信号对应的逻辑代码。信号处理函数通常使用管道将信号值传递给主函数,主函数通过I/O复用系统调用来监听管道读端文件描述符上的可读事件即可统一事件源。
很多IO框架和后台服务器程序都统一处理信号和IO事件,下面给出一个统一事件源的简单实现:
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet.h>
#include <arpa.inet.h>
#include <assert.h>
#include <stdio.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#include <fcntl.h>
#include <stdlib.h>
#include <sys/epoll.h>
#include <pthread.h>
#include <signal.h>
#define MAX_EVENT_NUMBER 1024
static int pipefd[2];
// 将文件描述符设置成非阻塞
int setnonblocking(int fd){
int old_option = fcntl(fd, F_GETFL);
int new_option = old_option | O_NONBLOCK;
fcntl(fd, F_SETFL, new_option);
return old_option;
}
// 将文件描述符fd上的EPOLLIN注册到epollfd指示的epoll内核事件表中,参数enable_et指定是否对fd启用ET模式
void addfd(int epollfd, int fd, bool enable_et){
epoll_event event;
event.data.fd = fd;
event.events = EPOLLIN;
if(enable_et){
event.events |= EPOLLET;
}
epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event);
setnonblocking(fd);
}
// 信号处理函数
void sig_handler(int sig){
// 保留原来的errno,在函数最后回复,保证函数的可重入性
int save_errno = errno;
int msg = sig;
send(pipefd[1], (char*)&msg, 1, 0); // 将信号值写入管道,以通知主循环
errno = save_errno;
}
// 设置信号的处理函数
void addsig(int sig){
struct sigaction sa;
memset(&sa, '\0', sizeof(sa));
sa.sa_handler = sig_handler;
sa.sa_flags != SA_RESTART;
sigfillset(&sa.sa_mask);
assert(sigaction(sig, &sa, NULL)!=-1);
}
int main(int argc, char* argv[]){
if(argc<=2){
printf("usage: %s ip_address port_number \n", basename(argv[0]));
return 1;
}
const char* ip = argv[1];
int port = atoi(argv[2]);
int ret = 0;
struct sockaddr_in address;
bzero(&address, sizeof(address));
address.sin_family = AF_INET;
inet_pton(AF_INET, ip, &address.sin_addr);
address.sin_port = htons(port);
// 创建TCP socket,绑定在端口port上
int listenfd = socket(PF_INET, SOCK_STERAM, 0);
assert(listenfd>0);
ret = bind(listenfd, (struct sockaddr*)&address, sizeof(address));
if(ret = -1){
printf("errno is %d\n", errno);
return 1;
}
ret = listen(listenfd, 5);
assert(ret!=-1);
epoll_event events[MAX_EVENT_NUMBER];
int epollfd = epoll_create(5);
assert(epollfd!=-1);
addfd(epollfd, listenfd);
// 使用socketpair创建管道,注册pipefd[0]上的可读事件
ret = socketpair(PF_UNIX, SOCK_STREAM, 0, pipefd);
assert(ret!=-1);
setnonblocking(pipefd[1]);
addfd(epollfd, pipefd[0]);
// 设置一些信号的处理函数
addsig(SIGHUP);
addsig(SIGCHLD);
addsig(SIGTERM);
addsig(SIGINT);
bool stop_server = false;
while(!stop_server){
int number = epoll_wait(epollfd, events, MAX_EVENT_NUMBER, -1);
if((number<0)&&(errno!=EINTR)){
printf("epoll failure\n");
break;
}
for(int i=0;i<number;i++){
int sockfd = events[i].data.fd;
// 如果就绪的文件描述符是listenfd,则处理新的连接
if(sockfd == listenfd){
struct sockaddr_in client_address;
socklen_t client_addrlength = sizeof(client_address);
int connfd = accept(listenfd,(struct sockaddr*)&client_address, &client_addrlength);
addfd(epollfd, connfd);
}
// 如果就绪的文件描述符是pipefd[0],则处理信号
else if((sockfd==pipefd[0])&&(events[i].events&EPOLLIN)){
int sig;
char signals[1024];
ret = recv(pipefd[0], signals, sizeof(signals), 0);
if(ret == -1){
continue;
}
else if(ret == 0){
continue;
}
else{
// 因为每个信号值占一个字节,所以按照字节逐步接受信号
for(int i=0;i<ret;i++){
switch(signals[i]){
case SIGCHLD:
case SIGHUP:{
continue;
}
case SIGTERM:
case SIGEINT:{
stop_server = true;
}
}
}
}
}
else{
}
}
}
printf("close fds\n");
close(listenfd);
close(pipefd[1]);
close(pipefd[0]);
return 0;
}定时器在网络程序中也很重要,比如定期检测一个客户的活动状态。
服务器程序通常管理着众多的定时器,因此有效的组织这些定时器,使得他们能在预期的时间点被触发而且不影响服务器的主要逻辑这个特性对服务器的性能有着重要的影响。
因此我们会将定时事件封装成定时器,并使用某种容器类数据结构将所有的定时器集合到一起,比如用链表,时间轮,时间堆,以实现对事件的统一管理。
**定时的含义:**在一段时间之后出发一段代码的机制,我们可以在这段代码中依次处理所有到期的定时器,Linux提供了三种定时方法:
- socket选项的SO_RCVTIMEO和SO_SNDTIMEO
- SIGALRM信号
- IO复用的超时参数
这两个参数是分别用来设置socket接收数据超时时间和发送数据超时时间。因此这两个参数只对相关读写函数有用,比如send、recv、sendmsg、recvmsg、accept、connect。
可以根据系统调用如(send、recv、sendmsg、recvmsg、accept、connect)的返回值以及errno来判断超时时间是否已到,进而决定是否开始处理定时任务。
由alarm和setitimer函数设置的实时闹钟一旦超时,将触发SIGALRM信号,因此可以利用该信号的信号处理函数来处理定时任务。但是想一下,如果我们要处理多个定时任务就要不断的触发SIGALRM信号,并在其信号处理函数中执行到期的任务。
代码:
首先给出一种定时器的简单实现——基于升序链表的定时器(P195)
然后通过一个实例——处理非活动链接来介绍如何使用SIGALRM信号定时(P200)
Linux下的3组IO复用函数都带有超时参数,因此不仅可以统一处理信号和IO事件,而且也可以统一处理定时事件。
但由于IO复用可能在超时时间之前就返回(比如有IO事件发生),所以如果要用来定时,就需要不断地更新定时参数以反映剩余时间
代码:P205
基于升序链表来管理定时器这种方式不适合定时器过多的场景,因为就一条链表,随着链表上定时器的增多会造成插入效率的降低。
因此以下时间轮和时间堆是最常使用的两种。
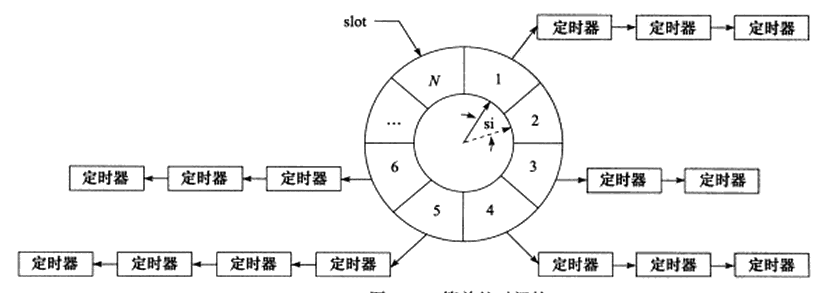
-
上图时间轮的特点:
- 上图有N个槽,每一个槽叫做slot
- 指针顺时针转动,从slot1转动到slot2,时间间隔是tick,即心搏时间。因此转完一圈所用的时间是N*tick
- 每一个slot指向一个定时器链表,每条链表上的定时器有相同的特征
- 两个slot中的定时器链表时间差是tick间隔时间的整数倍
- 要将定时时间为ti的定时器插入时间轮中,假如现在指向slot1,则会加入$$slot=(slot_1 + (t_i/tick))%N$$
- 对时间轮而言,如果要提高精度,就要使得tick值足够小;要提高执行效率,需要使得N值足够大。
- 本质思想就是利用哈希表,将定时器散列到不同的链表上,提高效率。
-
分析:添加一个定时器的时间复杂度是O(1),删除一个定时器的时间复杂度是O(1),执行一个定时器的时间复杂度是O(n)。‘
-
代码
#ifndef WHEEL_TIMER_H #define WHEEL_TIMER_H #include<time.h> #include<netinet/in.h> #include<stdio.h> #define BUFFER_SIZE 64 class tw_timer; /*客户端数据信息存储的结构体*/ struct client_data{ sockaddr_in address; int sockfd; char buf[BUFFER_SIZE]; tw_timer* timer; }; //定时器类 class tw_timer{ public: int rotation; //记录该定时器在时间轮转多少圈后才生效 int time_slot; //记录该定时器属于哪一个槽中 client_data* user_data; tw_timer* next; tw_timer* prev; void (*cb_fun)(client_data* user_data); tw_timer(int rotation, int slot):next(NULL), prev(NULL), rotation(rotation), time_slot(slot){} }; //时间轮 class time_wheel{ public: time_wheel():cur_slot(0){ for(int i = 0; i < N; i++){ slots[i] = 0; //初始化每一个槽的头结点 } } ~time_wheel(){ //销毁每一个槽中的定时器 for(int i = 0; i < N; i++){ tw_timer* tmp = slots[i]; while (tmp) { //slots[i]是头结点 slots[i] = tmp->next; delete tmp; tmp = slots[i]; } } } tw_timer* add_timer(int timeout); void del_timer(tw_timer* timer); void tick(); private: static const int N = 60; //slot的数目 static const int SI = 1; //从一个slot到下一个slot所耗费的时间,就是tick tw_timer* slots[N]; //N个slot,N个链表,每个定时器指向一个 int cur_slot; //时间轮当前所在的slot }; /*含义:根据定时值timeout创建定时器,然后插入相应slot中*/ tw_timer* time_wheel::add_timer(int timeout){ if(timeout < 0){ return NULL; } int ticks = 0; /*根据定时器的超时值timeout计算将在时间轮转动多少个tick后被触发,并将该数存放在ticks中。 如果不满足一个tick时间,就取最小的tick时间为1,如果大于一个tick就除法呗,将值存于ticks中*/ if(timeout < SI){ ticks = 1; }else{ ticks = timeout / SI; } int rotation = ticks / N; //看ticks是否超过了一轮,即时间轮转动多长时间会被触发 int select_slot = (cur_slot + (ticks % N)) % N; //待插入的定时器应该放在哪个槽中 tw_timer* timer = new tw_timer(rotation, select_slot); //创建一个定时器,在转动rotation后被触发,在select_slot中 /*如果某个slot中没有定时器,则将待插入的定时器作为头结点插入*/ if(!slots[select_slot]){ printf("add a new timer!, after %d rounds, at %d\n", rotation, select_slot); slots[select_slot] = timer; }else{ //头插法 timer->next = slots[select_slot]; slots[select_slot]->prev = timer; slots[select_slot] =timer; } return timer; } /*删除目标定时器*/ void time_wheel::del_timer(tw_timer* timer){ if(!timer){ return; } int timer_cur_slot = timer->time_slot; /*如果该timer是所在槽的头结点,则要重置一下该槽的头结点*/ if(timer == slots[timer_cur_slot]){ slots[timer_cur_slot] = slots[timer_cur_slot]->next; //为什么要判断,因为这个时候节点已经变成头结点的下一个了,要判断是是否为空 if(slots[timer_cur_slot]){ slots[timer_cur_slot]->prev = NULL; } delete timer; }else{ timer->prev->next = timer->next; if(timer->next){ timer->next->prev = timer->prev; } delete timer; } } //一个tick过后,需要调用该函数使得时间轮向前滚动 void time_wheel::tick(){ tw_timer* tmp = slots[cur_slot]; printf("current slot is %d\n", cur_slot); while (tmp) { printf("the wheel need to tick once!\n"); if(tmp->rotation > 0){ tmp->rotation--; tmp = tmp->next; }{ /*定时器到期,执行任务然后删除定时器*/ tmp->cb_fun(tmp->user_data); if(tmp == slots[cur_slot]){ printf("in head node, need to delete header in cur_slot!\n"); slots[cur_slot] = tmp->next; delete tmp; if(slots[cur_slot]){ slots[cur_slot]->prev = NULL; } tmp = slots[cur_slot]; }else{ tmp->prev->next = tmp->next; if(tmp->next){ tmp->next->prev = tmp->prev; } tw_timer* tmp2 = tmp->next; delete tmp; tmp = tmp2; } } } cur_slot = cur_slot++ % N; } #endif
-
添加一个定时器的时间复杂度是O(1), 删除一个定时器的时间复杂度是O(1),执行一个定时器的时间复杂度是O(N)。
时间轮是以固定的频率调用心搏函数tick的,并在其中依次检测到期的定时器,然后执行到期定时器上的回调函数。
但是时间堆是另外一种思路:将所有定时器中超时时间最小的一个定时器的超时值作为心搏间隔,这样的话一旦心搏函数tick被调用,超时时间最小的定时器必然到期,然后就可以在tick函数中处理该定时器。接着再从剩余的找个最小的,将这段最小时间设置为下一次心搏间隔。这样可以发现一个间隔(心搏时间)必然会触发一个定时器,这种定时方法比较精准。
所以最小堆很容易实现这种定时方案。
#ifndef MIN_HEAP
#define MIN_HEAP
#include<iostream>
#include<netinet/in.h>
#include<time.h>
#define BUFFER_SIZE 64
class heap_timer;
struct client_data{
sockaddr_in address;
int socket;
char buf[BUFFER_SIZE];
heap_timer* timer;
};
//定时器类
class heap_timer{
public:
time_t expire; //定时器生效绝对时间
void (*cb_func)(client_data* data);
client_data* user_data;
heap_timer(int delay){
expire = time(NULL) + delay;
}
};
//时间堆类
class time_heap{
private:
heap_timer** array; //堆数组
int capacity; //堆容量
int cur_size; //堆当前定时器的个数
void percolate_down(int hole);
void resize() throw(std::exception);
public:
//构造函数1,初始化容量为cap的空堆
time_heap(int cap)throw(std::exception):capacity(cap), cur_size(0){
array = new heap_timer*[capacity]; //创建cap容量的数组,每个数组元素是一个定时器类对象
if(!array){
throw std::exception();
}
for(int i = 0; i < capacity; i++){
array[i] = NULL; //初始化数组
}
}
//构造函数2, 用已有的数组来初始化堆
time_heap(heap_timer** init_array, int size, int capacity)
throw(std::exception):cur_size(size), capacity(capacity){
if(capacity < size){
throw std::exception();
}
array = new heap_timer*[capacity];
if(!array){
throw std::exception();
}
for(int i = 0; i < capacity; i++){
array[i] = NULL; //初始化数组
}
if(size !=0 ){
for(int i = 0; i < size; i++){
array[i] = init_array[i];
}
for(int i = (cur_size - 1)/2; i >=0; i--){
percolate_down(i);
}
}
}
~time_heap(){
for(int i = 0; i < cur_size; i++){
delete array[i];
}
delete [] array;
}
void add_timer(heap_timer* timer) throw(std::exception);
void del_timer(heap_timer* timer);
void pop_timer();
void tick();
bool empty() const {return cur_size==0;}
heap_timer* top() const;
};
void time_heap::add_timer(heap_timer* timer) throw(std::exception){
if(! timer){
return;
}
if(cur_size >= capacity){
resize();
}
/*新来一个定时器,堆数组加1*/
int hole = cur_size++;
int parent = 0;
/*上浮操作,更新堆*/
for(; hole > 0; hole = parent){
//找父亲节点
parent = (hole-1)/2;
if(array[parent]->expire <= timer->expire){
break;
}
array[hole] = array[parent];
}
array[hole] = timer;
}
void time_heap::del_timer(heap_timer* timer){
if(!timer){
return;
}
/*延迟销毁,节省删除定时器造成的开销,但会使得堆数组膨胀*/
timer->cb_func = NULL;
}
heap_timer* time_heap::top() const {
if(empty){
return;
}
return array[0];
}
void time_heap::pop_timer(){
if(empty()){
return;
}
if(array[0]){
delete array[0];
array[0] = array[--cur_size];
percolate_down(0); //对剩余元素执行下沉操作
}
}
void time_heap::tick(){
heap_timer* tmp = array[0];
time_t cur = time(NULL);
while(!empty()){
if(!tmp){
break;
}
//定时器没到期,退出循环
if(tmp->expire > cur){
break;
}
//到期了,执行定时器中的回调函数
if(array[0]->cb_func){
array[0]->cb_func(array[0]->user_data);
}
//到时的定时器执行完就拿走,生成新的根
pop_timer();
tmp = array[0];
}
}
//下沉操作,以hole为节点的这个定时器拥有最小堆性质
void time_heap::percolate_down(int hole){
heap_timer* temp = array[hole];
int child = 0;
for(; ((hole*2+1)) <= (cur_size-1); hole =child){
//上浮找的是父节点,下沉找的是孩子节点
child = hole*2+1;
if((child < (cur_size-1)) && (array[child+1]->expire < array[child]->expire)){
child++;
}
if(array[child]->expire < temp->expire){
array[hole] = array[child];
}else{
break;
}
}
array[hole] =temp;
}
//扩容一倍
void time_heap::resize() throw(std::exception){
heap_timer** temp =new heap_timer* [2*capacity];
for(int i=0; i< 2*capacity; i++){
temp[i] =NULL;
}
if(!temp){
throw std::exception();
}
capacity = 2*capacity;
for(int i = 0; i < cur_size; i++){
temp[i] = array[i];
}
delete [] array;
array = temp;
}
#endif其中关于小顶堆的上浮和下沉操作可以好好看一看,是循环的那种写法,不是递归的。
分析:添加一个定时器的时间复杂度是O(lgn),删除一个定时器的复杂度是O(1),执行一个定时器的时间复杂度是O(1),因此效率很高。
+++
Linux服务器必须处理的三类事件:
- IO事件
- 信号
- 定时事件
处理这三类事件的时候要考虑三个问题:
- 统一事件源。一般方法,利用IO复用来管理所有事件
- 可移植性。不同操作系统具有不同的IO复用方式
- 对并发编程的支持。在多进程和多线程的环境下,需要考虑各执行实体如何协同处理客户连接,信号和定时器,避免竞争
ACE、ASIO和Libevent对于上面六个问题的处理都非常出色,本章介绍Libevent
IO框架库以库函数的形式,封装了底层的系统调用,给应用程序提供了一组更便于使用的接口。各个IO框架库的实现原理较为类似,要么是Reactor模式,要么是Proactor模式。基于Reactor模式实现的IO框架库包含了如下几个组件:
-
Handle
IO框架库要处理的统一对象,包括IO事件,定时器和信号,成为统一事件源。一个事件源通常和一个handle绑定在一起。在Liunx环境下,IO事件对应的handle就是文件面舒服,信号事件对应的handle就是信号值,定时事件对应的handle是-1。
handle的作用就是当内核检测到就绪事件时候,通过handle通知给应用程序。
-
EventDemultiplexer(事件多路分发器)
事件的到来时随机,异步的。我们无法得知程序何时收到了一个客户连接,何时收到了一个暂停信号,因此程序就必须循环的等待这些handle的到来然后处理,这个过程就叫做事件循环,一般用IO复用技术实现。
IO框架库一般将系统支持的各种IO复用系统调用封装成统一的接口,叫做事件多路分发器
-
EventHandler和ConcreteEventHandler(事件处理器和具体事件处理器)
Eventhandler执行事件对应的业务逻辑,通常包含一个
get_handle()获得对应事件源的句柄,和一个或多个回调函数handle_event。 -
Reactor
Reactor是IO框架库的核心,主要提供以下几个方法:
- handle_events,一直循环等待事件发生,有事件来了就执行就绪事件的EventHandler。
- register_handler,调用事件多路分发器中的register_event方法,往事件多路分发器中注册一个事件
- remove_handler,调用事件多路分发器中的remove_event方法,往事件多路分发器中删除一个事件
没时间看了p220
+++
Linux下创建新进程的系统调用时fork函数,其定义如下:
#include <unistd.h>
pid_t fork(void); -
该函数的每次调用都返回两次,在父进程中返回子进程的PID,在子进程中则返回0,返回是后续判断该进程是子进程还是父进程的重要依据,调用失败时返回-1并设置errno。
-
fork函数复制当前进程,在内核进程表中创建一个新的进程表项。由于fork是复制原进程的映像,因此进程表项有很多属性和原进程相同,比如栈帧,标志寄存器的值等。(其它寄存器是用来存放数据,整个寄存器具有一个含义。而标志寄存器是按照位来起作用的,每一位有专门的含义,记录特定的信息。)
但是也有不同的,比如说PPID(该进程的父进程号)被设置成为了原进程的PID,信号位图被清除(因为原进程的信号处理函数不再对新进程起作用)
-
子进程的代码和父进程完全相同,同时还会复制父进程的数据(堆数据、栈数据、静态数据)。复制采用的是写时复制(只有任意进程不论父进程还是子进程,堆数据执行写操作时复制才会发生。先是缺页中断,然后操作系统给子进程分配内存并复制父进程的数据)。因此当在程序中分配大量内存的时候需要当心,尽量避免没必要的内存分配和数据复制
-
创建子进程后,父进程中打开的文件描述符在子进程中也是默认打开的,且文件描述符的引用计数+1.同时父进程的用户根目录,当前工作目录等引用计数均+1。
+++
当我们想在子进程中执行其他程序时候,即替换当前进程映像,需要使用exec系列函数:
#include <unistd.h>
extern char **environ;
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...); //后面是可变参数,以NULL结尾.带p会在环境变量路径下搜索程序。
int execle(const char *path, const char *arg,.., char * const envp[]); //不在环境变量下搜索,但是可以带一个环境信息,可以见下面的例2。
int execv(const char *path, char *const argv[ ]); //v是将参数以NULL结尾放入一个char* const数组中[指针是const]
int execvp(const char *file, char *const argv[ ]);path指定可执行文件的完整路径;file参数接受文件名,具体位置在PATH环境变量中找;arg接收可变参数,argv接收数组,都会被传递给新程序的main函数中。exec函数不会关闭源程序打开的文件描述符。
+++
当创建一个子进程后,父进程一般需要跟踪子进程的退出状态。所以当子进程结束后,内核不会立即释放子进程的进程表项,以满足父进程后续对子进程相关信息的查询。当子进程结束运行状态之后,父进程读取其退出状态之前这段时间内,子进程就是一个僵尸进程。另外一种使得子进程进入僵尸状态的是父进程结束或者异常终止,但是子进程还在运行,此时子进程的PPID被内核设置为1,即init进程。init进程接管该子进程,并等待其结束。因此在父进程退出之后,子进程退出之前的这段时间内的子进程也处于僵尸态。
停留在僵尸态的进程将占据内核资源,这是非常浪费的一种行为。Linux中提供了几个系统调用函数如下,父进程中调用该函数,以等待子进程的结束,并获取子进程的返回信息,避免僵尸进程的产生,或者使得子进程的僵尸态立即结束。
#include<sys/types.h>
#include<sys/wait.h>
pid_t wait (int * status);
pid_t waitpid(pid_t pid,int * status,int options)wait函数将会阻塞进程,直到某个进程的子进程结束运行为止,返回结束运行的子进程的PID,并将该子进程的退出状态信息存储在status中,用宏来定义退出状态信息。由于wait函数的阻塞特性非常傻逼,服务器肯定不愿意,那么waitpid来解决这个问题。waitpit等待有pid指定的子进程,如果取-1就和wait函数相同,即等待任意一个子进程的结束。
在事件已经发生后执行非阻塞调用才能提高程序效率,对于 waitpid来说,最好在某个子进程退出之后再调用,用SIGCHILD信号来通知父进程其某个子进程已经结束。因此父进程可以捕获SIGCHILD信号,并在信号处理函数中调用waitpid彻底结束一个子进程。
+++
系统调用:pipe
管道也是父进程和子进程间通信的最好手段
管道能在父、子进程间传递数据,利用的是fork调用之后两个管道描述符(fd[0]和fd[1])都保持打开,一对这样的描述符只能保持单向传递数据,

所以要实现双向通信就必须使用两个管道。
socket编程接口提供了一个创建全双工管道的系统调用:socketpair
管道只能用于两个有关联的进程间的通信,但后面要说的system V IPC可以用于无关联的多个进程间的通信
+++
一共有三种:信号量、消息队列、共享内存
当多个进程同时访问系统上的某个资源时,比如同时写一个数据库上的记录,或同时修改某个文件,就需要考虑进程间同步的问题。所以信号量严格来说是解决进程间同步问题的,但是进程间同步也是进程通信的一种吧,所以就放在这里了。
临界区:一段代码引发了进程之间的竞争条件,这段代码就叫做临界区
要保证代码独占式访问某个数据或文件是有的,比如Dekker算法和Peterson算法,试图从语言本身解决并发问题,但是依赖于忙等,即进程要持续不断地等待某个内存位置状态的改变,CPU利用率太低了,不可取。
信号量(Semaphore)是迪杰斯特拉提出的,是一种特殊的变量,取值是自然数并且只支持两种操作:等待和信号,即PV操作。P表示进入临界区,V表示释放,退出临界区。
信号量有自然数的,也有二进制信号量。
Linux信号量的API定义在sys/sem.h头文件中,主要包括三个系统调用:semget, semop, semctl。都是用来操作一组信号量而不是单个信号量的。
-
semget(创建)
semget系统调用创建一个新的信号量集,或者获取一个已经存在的信号量集
头文件: #include <sys/types.h> #include <sys/ipc.h> #include <sem.h> 函数原型:int semget (key_t key, int nsems, int flag) 参数说明: key: 所创建或要获取的信号量集的键。 nsems: 所创建的信号量集中信号量的个数,此参数只在创建一个新的信号量集时有效。 flag: 调用函数的操作类型,也可以设置信号量集的权限。 函数说明:调用函数semget的作用由参数key和flag决定,具体如下: a. 当key为IPC_PRIVATE时,创建一个新的信号量。此时flag的取值对函数的操作不起任何作用 b. 当key不为IPC_PRIVATE时,且flag设置了IPC_CREAT位,而没有设置IPC_EXCL位,则执行操作由key取值决定。如果key为内核中某个已经存在的信号量的 键,则执行获取这个信号量的操作,否则执行创建信号量的操作。 c. 当key不为IPC_PRIVATE时,且flag同时设置了IPC_CREAT和IPC_EXCL位,则只执行创建信号量的操作。参数key的取值应与内核中已经存在的任何信号量集的 键值都不相同,否则函数调失败。 返回值:函数 调用成功时,返回值为信号量集的引用标识符(semid);调用失败时,返回-1。 -
semop(操作)
semop系统调用改变信号量的值,即执行P、V操作
头文件: #include <sys/types.h> #include <sys/ipc.h> #include <sem.h> 函数原型:int semop (int semid, struct sembuf *sops, unsigned nsops); 参数说明: semid:信号量集的引用ID sops: 一个sembuf结构体数组,用于指定调用semop函数所做的操作。 nsops: sops数组元素的个数。 sembuf结构体的定义以及操作如下: struct sembuf{ ushort sem_num; // 指定要操作的信号量 short sem_op; // 所要执行的操作 short sem_flag; // 操作标记(IPC_NOWAIT / SEM_UNDO) };具体在书本的P246
-
semctl(控制)
semctl允许调用者对信号量进行直接控制
头文件: #include <sys/types.h> #include <sys/ipc.h> #include <sem.h> 函数原型:int semctl (int semid, int semnum, int cmd, ...); 参数说明: semid: 信号量集的引用标识符 semnum: 用于指定某个特定的信号量 cmd: 调用该函数希望执行的操作 第四个类型参数由用户自己定义,具体看书P247
+++
消息队列是在两个进程之间传递二进制数据块的一种简单有效的方式。每个数据块都有特定的类型,接收方可以根据类型有选择的接收数据,而不一定像管道和命名管道那样先进先出的方式接收数据。
Linux消息队列的API定义在sys/msg.h中,有四个:msgget, msgsnd, msgrcv, msgctl。具体用法在书的P263页
-
msgget
创建或获取一个已有的消息队列
-
msgsnd
把一条消息添加到消息队列中
-
msgrcv
从消息队列中获取一条消息
-
msgctl
控制消息队列的某些属性。
+++
共享内存是最高效的IPC机制,因为其不涉及进程间的任何数据传输。这种高效带来的缺点是我们必须通过其他辅助手段来同步进程对共享内存的访问,否则会产生竞态条件。所以共享内存通常和其他进程间通信方式一起使用。
Linux共享内存的API定义在sys/shm.h中,有四个:shmget, shmat, shmdt, shmctl。具体用法在书的P251页
-
shmget
创建一段新的共享内存,或者获取一段已经存在的共享内存。
-
shmat和shmdt
共享内存被创建或获取后,并不能立即访问。需要将这段共享内存关联到进程的地址空间中,使用完共享内存之后,需要将其从进程地址空间中分离。
-
shmctl
控制共享内存中的某些属性。
mmap函数利用MAP_ANONYMOUS标志可以实现父、子进程之间的匿名内存共享。
同时通过打开同一个文件,mmap也可以实现无关进程之间的共享。利用下面shm_open函数创建或打开一个共享内存对象,最后用shm_unlink来删除这个共享内存。
如果使用了这两个函数,编译的时候要加上-lrt!
使用共享内存的聊天室服务器程序:连接
+++
传递文件描述符并不是传递一个文件描述符的值,而是要在接收进程中创建一个新的文件描述符,该文件描述符和发送进程中传递的文件描述符执行内核中相同的文件表项,从过程来看确实很像是“文件描述符值的传递”
把子进程中打开的文件描述符传递给父进程与两个不相干进程之间传递文件描述符是同一个道理,都是利用socket在进程间传递特殊的辅助数据,以实现文件描述符的传递。代码如连接所示:链接
+++
小知识:早期Linux是不支持线程的,第一个基本符合POSIX标准的线程库是LinuxThreads,但效率低而且有很多问题。自内核2.6开始才真正提供内核级的线程支持,持续到最后的是NPTL,现在所用的基本都是NPTL。
线程是一个程序中完成一个独立任务的完整执行序列,是一个可调度的实体。Linux县城可以分为内核线程和用户线程。
内核线程:也叫做LWP(Light Weight Process,轻量级线程),运行在内核空间,由内核调度。
用户线程:运行在用户空间, 由用户调度。
当进程的一个内核线程获得CPU的使用权时,他就加载并运行一个用户线程,所以说内核线程相当于用户线程的容器。
一个进程可以拥有M个内核线程和N个用户线程,其中$M≤N$。同时在一个系统中的所有进程中,M和N的比值都是固定的。所以线程有三种实现方式:完全在内核空间实现,完全在用户空间实现,双层调度:
-
完全在用户空间实现的线程不需要内核的支持,内核甚至根本不知道这些线程的存在。线程库负责管理所有的线程,利用longjmp来切换线程的执行,使其看起来像是并发,但实际上内核仍然把进程当做最小调度单位。一个进程的所有线程共享该进程的时间片,M=1即N个用户线程对应一个内核线程,而内核线程本身就是进程本身。
用户空间内实现的线程的优点是:①创建和调度线程不需要内核干预,速度快。②用户空间实现的线程不占用内核资源,因此即使一个进程创建了很多线程,也不会对系统性能造成明显影响。
用户空间内实现的线程的缺点是:①对于多处理器系统,一个进程的多个线程无法运行在不同的CPU上(因为本质上还是一个进程内部的)。内核是按照最小调度单位来分配CPU的。②线程的优先级只对同一个进程的不同线程有效,不同进程中线程的优先级没有比较意义。
-
完全由内核实现的线程将创建、调度线程的任务交给了内核,运行在用户空间中的线程库无需执行管理任务。优缺点和完全在用户空间实现的完全相反。
完全由内核实现的线程满足$M:N=1:1$,即一个用户空间线程被映射为1个内核线程。
-
双层调度模式是混合的,内核调度M个内核线程,线程库调度N个用户线程。不会消耗过多的内核资源,线程切换速度也快,冲分利用了多处理器的优势。
Linux的NPTL采用1:1的方式实现线程。
+++
都是一些基础的API,详细用法在这里不讲,具体要去查
定义在pthread.h文件里面
-
phread_create()
创建一个线程,成功时返回0,失败时返回错误码。一个用户可以打开的线程数量不能超过RLIMT_NPPROC限制,系统上所有用户能创建的线程综述也不能超过内核定义的数量
-
pthread_exit()
线程被创建后,phread_create()有一个参数是线程可执行函数的函数指针,内核可以调度内核线程执行函数指针所指向的函数。
线程函数结束后调用pthread_exit()保证安全干净的退出。
-
pthread_join()
一个进程中的所有线程都可以调用该函数回收其他线程,就是等其他线程结束,类似于进程中的wait和waitpid系统调用
-
pthread_cancel()
终止线程。接收到取消请求的下承诺恒可以决定是否允许被取消以及如何被取消,由函数pthread_setcancelstate()和pthread_setcanceltype()完成。
pthread_attr_t结构体定义了一套完整的线程属性,线程库还定义了一些列函数来操作pthread_attr_t类型的变量,具体用到再细查。
+++
Linux上信号量API有两组,一组是System V IPC信号量,另一组就是POSIX信号量,这两组接口相似但是不能互换。POSIX信号量的头文件是semaphore.h
-
sem_init
初始化一个未命名的信号量,其中pshare表示信号量是当前进程的局部信号量还是可以在多个进程之间共享。
-
sem_destroy
销毁信号量,释放其占用的内核资源,如果销毁一个被其他线程等待的信号量,会产生不会预估的后果。
-
sem_wait和sem_trywait
sem_wait以原子操作将信号量的值减一,若信号量值为0,则该函数被阻塞。
sem_trywait每次都立刻返回,不论被操作的信号量是否为0,相当于非阻塞
-
sem_post
以原子方式将信号量值加1,当信号量的值大于0时,其他调用sem_wait等待的线程会被唤醒,这些等待线程在等待队列中。
互斥量可以保护关键代码段,确保其独占式访问
进入关键代码时,需要获得互斥锁并加锁,等价于二进制信号量的P操作
离开关键代码时,需要对互斥锁解锁同时唤醒其他等待该互斥锁的线程,等价于二进制信号量的V操作
介绍一下API,在pthread.h中,互斥锁的类型是pthread_mutex_t结构体
-
pthread_mutex_init
初始化互斥锁,除了这个函数外,还可以用如下方式初始化互斥锁:
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER
-
pthread_mutex_destroy
销毁互斥锁,释放其占用的内核资源。但是销毁一个已经加锁的互斥锁将导致不可预期的后果。
-
pthread_mutex_lock和pthread_mutex_trylock
加锁,阻塞和非阻塞版本,主要针对普通锁而言。
-
pthread_mutex_unlock
以原子操作给互斥锁解锁
pthread_mutexattr_t结构体定义了一套完整的互斥锁属性,同时线程库提供了一些列函数来操作pthread_mutexattr_t变量
互斥锁有两个常用的属性:pshared和type,具体看书p277
当一个线程中对一个已经加锁的普通锁再次加锁,就会导致死锁,见书p278的代码
条件变量提供了一种线程间的通知机制:当某个数据到达的时候,唤醒等待这个共享数据的线程。
APUE中的一句话:Condition variables are another synchronization mechanism available to threads. These synchronization objects provide a place for threads to rendezvous. When used with mutexes, condition variables allow threads to wait in a race-free way for arbitrary conditions to occur.
条件变量是线程的另外一种同步机。制理解起来就是两个(或者多个)线程需要交互(或者说进行交互-一个线程给另外的一个或者多个线程发送消息),我们指定在条件变量这个地方发生,一个线程用于修改这个变量使其满足其它线程继续往下执行的条件,其它线程则接收条件已经发生改变的信号。条件变量同锁一起使用使得线程可以以一种无竞争的方式等待任意条件的发生。所谓无竞争就是,条件改变时这个信号会发送到所有等待这个信号的线程。而不是说一个线程接受到这个消息而其它线程就接收不到了。
主要函数是pthread_cond_wait用于等待目标条件变量,有两个参数,mutex参数用于保护条件变量的互斥锁,以确保pthread_cond_wait的原子性(通知给其他所有线程,而不是通知一个后换线程导致其他线程收不到通知),而且必须先确保mutex已经加锁,否则会导致不可预估的结果。
具体在看吧,想有个概念。
+++
如果一个函数能被多个线程同时调用而且不发生竞态条件,则称其是线程安全的,也叫可重入的。
之所以不可重入,是因为内部使用了静态变量。但是Linux对很多不可重入的库函数提供了可重入的版本,一般是原函数名尾部加上_r
当多线程程序某个线程调用了fork函数后,新创建的子进程不会创建和父进程有相同数量的线程。
子进程中只会存在一个执行线程,就是调用了fork的那个线程的完整复制,同时子进程将自动继承父进程中互斥锁等状态,即父进程被加锁的变量在子进程中也是被加锁的。但是会存在一个问题:子进程不清楚从父进程继承而来的互斥锁的状态,即父进程的这个锁对子进程来说不知道是哪个线程加的。如果子进程再次加锁,可能会导致死锁。对于上述问题,pthread提供了一个专门的函数pthread_atfork确保调用后父进程和子进程都拥有一个清楚地锁状态。
#include <pthread.h>
int pthread_atfork(void (*prepare)(void), void (*parent)(void), void (*child)(void));
//调用fork时,内部创建子进程前在父进程中会调用prepare,内部创建子进程成功后,父进程会调用parent ,子进程会调用child每个线程可以独立的设置信号掩码,比如函数sigprocmask,但是多线程环境下使用pthread_sigmask来设置。
进程中的所有线程共享该进程的信号,所以线程库将根据线程掩码决定把信号发送给哪个具体的线程。所以如果每个子线程中都单独设置信号掩码,很容易导致逻辑错误。而且所有线程共享信号处理函数,即一个线程设置了某个信号的信号处理函数后,其他线程为该信号设置的信号处理函数将失效,因为已经有了。因此应该专门定义一个线程处理所有的信号:
- 在主线程创建其他子线程之前调用pthread_sigmask来设置信号掩码,那么所有后面创建的子线程将会继承该信号掩码
- 某个子线程调用sigwait等待信号并处理
另外pthread_kill可以将一个信号发送给指定的线程,还可以用来检查目标线程是否存在。
+++
-
概述
进程池是由服务器预先创建的一组子进程,这些子进程的数目在3~10之间(不一定,比如httpd守护进程使用7个子进程的进程池实现并发),总是进程池的数量应该和CPU数量差不多
进程池中的所有子进程都运行着相同的代码,并且具有相同的属性,比如优先级,PGID(进程组)等。
(进程池的优点)因为进程池中的进程是在服务器启动之初就建好了,所以每个子进程都是干净的,因为如果运行时创建进程,会创建对应父进程的进程映像,导致子进程有很多自身不需要的东西存在,即没有打开不必要的文件描述符(从父进程继承而来),也不会使用大块儿堆内存(从父进程复制)
当有新的任务到来时,主进程将通过某种方式选择进程池中的某一个子进程来为之服务,相比于动态创建子进程,选择一个已经存在的子进程的代价要小得多
选取子进程也有很多算法,比如轮转算法,共享的工作队列等,
选择相应的子进程后,主进程还需要用某种通知机制来告诉目标子进程有新任务处理,并传递必要的数据。一般来说就是子进程和父进程之间建立一个全双工管道,比如socketpair函数。父线程和子线程之间传递数据就很简单,把这些数据定义为全局的,可以被所有线程共享。
-
动态创建进程的缺点——进程池的优点
- 动态创建进程、线程比较费时,导致客户端响应变慢
- 动态创建的子进程、子线程通常是为了给某个特定的用户服务,这将导致系统上产生大量的细微进程,线程的话因为linux规定,销毁线程并不会全部销毁,而是将线程结构中的一个标志位设置为不可响应,这样等需要新的线程之后可以用原先被销毁线程的数据结构,这样为了节省空间和提高效率
- 动态创建子进程是当前进程的完整映像。因此当前进程必须谨慎的管理文件描述符、堆内存、锁等资源,否则子进程会复制这些资源导致服务器性能下降,严重还会出现bug。
-
进程池需要考虑的问题
-
监听socket和连接socket是否都由主进程统一管理
半同步/半反应堆是由主进程统一管理这两种socket,当主进程接收到新的连接socket时候需要将该socket传递给子进程
高效的半同步/半异步模式,领导者/追随者模式是由主进程管理监听socket,各个子进程管理属于自己的连接socket。这种灵活性更大,因为子进程可以自己调用accept来接收新的连接,这样父进程就无须向子进程传递连接的socket了
-
长连接问题.即一个客户的多次请求可以复用同一个TCP连接,因此设计进程池需要考一个客户连接上的所有任务是否始终由一个子进程来处理。
如果客户是无状态的,可以用不同的子进程处理一个客户的不同请求服务
如果客户任务是上下相关的,应该以至于用同一个子进程为之服务
-
epoll的EPOLLONESHOT事件可以确保一个客户连接在整个生命周期仅被一个线程处理。
-