In the long run every program becomes rococo - then rubble. 1
C 语言中指针和数组的关系是非常紧密的。当指针指向数组元素时,C 语言允许对指针进行算术运算(加减),通过这种运算我们可以用指针取代数组下标对数组进行处理。
int a[10] = {0};
int* p = &a[0];我们可以通过 p 访问 a[0]:
*p = 5;
printf("%d", a[0]); // 5C 语言只支持 3 种格式的指针算数运算:
- 指针加上整数
- 指针减去整数
- 两个指针相减
指针 p 加上整数 j 产生指向特定元素的指针,这个特定元素是 p 原先指向的元素的后的 j 个位置。也就是说如果 p 指向 a[i],那么 p + j 指向 a[i + j],前提是 a[i + j] 存在。如图:
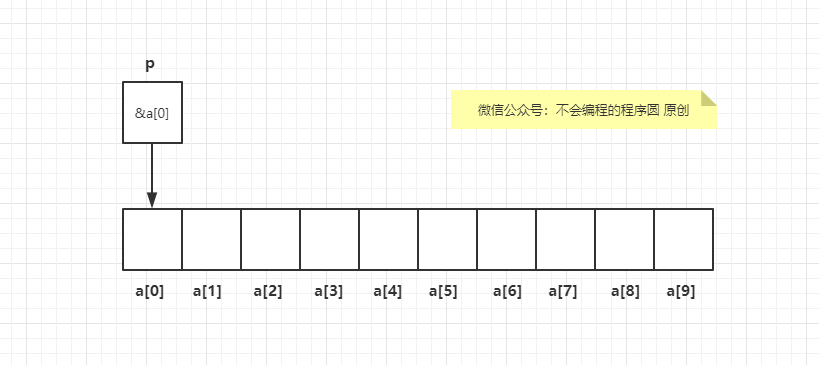
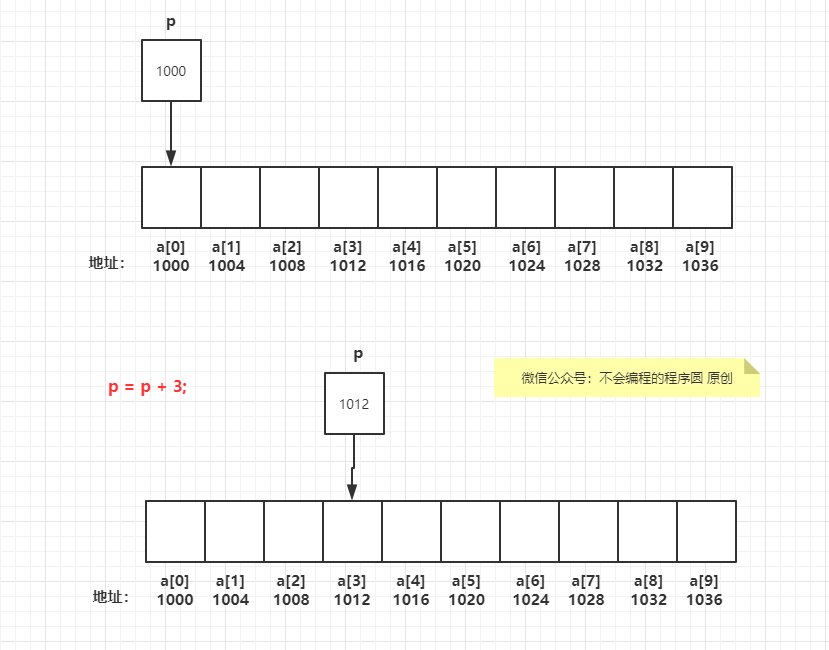
如果指针 p 指向数组元素 a[i],那么 p - j 指向 a[i - j] 。例如:
两个指针相减结果是指针之间的距离(用数组元素个数来度量)。
如果 p 指向 a[i],q 指向 a[j],q - p 等于 j - i 。例如:
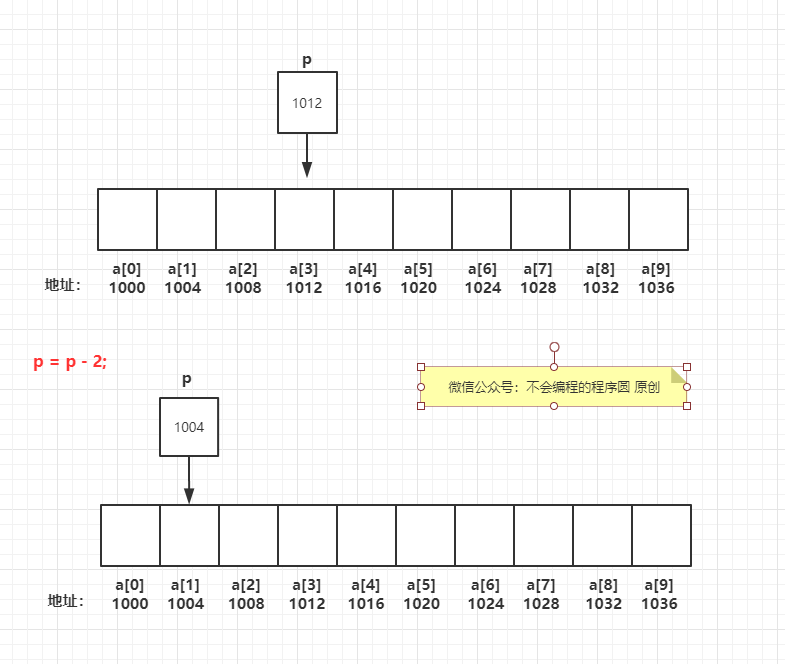
注意:
在一个不指向任何数组元素的指针上执行算数运算会导致未定义行为。此外,只有在两个指针指向同一个数组时,把他们相减才有意义。
可以用关系运算符(<,>,<=,>=)和判等运算符(==和 !=)进行指针比较。只有在两个指针指向同一数组时,用关系运算符进行指针比较才有意义。比较的结果依赖于数组种两个元素的相对位置。如图:
略。
通过对指针变量进行重复自增来访问数组元素。
#define N 10
int a[N], sum, *p;
sum = 0;
for(p = &a[0]; p < &a[N]; p++)
sum += *p;for 语句中的条件 p < &a[N]值得特别说一下。尽管 a[N] 元素不存在(数组下标是 a[0] 到 a[N - 1]),但是对它使用取地址运算符是合法的。因为循环不会检查 a[N] 的值,所以使用 &a[N] 是十分安全的。执行循环体时,p 依次等于 &a[0], &a[1], ..., &a[N - 1],但是当 p 等于 &a[N] 时,循环终止。
当然,改用下标可以很容易写出不使用指针的循环。支持采用指针算术运算的最常见论调是,这样作可以节省执行时间。但是这依赖于具体实现——对于有的编译器来说,实际上依靠下标的循环会产生更好的代码。
对于语句:
a[i++] = j;我们可以用指针改写为:
*p++ = j;因为后缀 ++ 的优先级高于 * ,所以上面的语句等同于:
*(p++) = j;先将 j 赋值给 p 指向的对象,然后 p 指向数组下一个元素。
| 表达式 | 含义 |
|---|---|
| (*p)++ | *p 自增(后置) |
| *++p 或 *(++p) | 先自增 p,然后解引用 |
| ++*p 或 ++(*p) | *p 自增 (前置) |
我们最常用到的就是 *p++ 。
对数组元素求和时,我们可以将前面写的 for 循环改写为:
p = &a[0];
sum = 0;
while(p < &a[N])
sum += *p++;* 和 -- 的组合和 ++ 类似。
之前我们用整型变量 top 记录栈顶的位置。现在我们用一个指针变量替换 top ,这个指针变量初始为 NULL(不指向任何对象)。
int* top_ptr = &stack[0];下面是新的 push 和 pop 函数:
void push(int* top_ptr, int i){
if(is_full())
stack_overflow();
else
*++top_ptr = i;
}
int pop(int* top_ptr){
if(is_empty())
stack_underflow();
else
return *top_ptr--;
}可以用数组名作为指向数组第一个元素的指针
int a[5] = {1, 2, 3, 4, 5};
printf("%d\n", *a); // 1
printf("%d\n", *(a + 4)); // 5
*(a + 1) = 1; // a[1] is now 1明白了这个原理,我们可以改写 for 语句求和数组元素的程序:
for(p = a; p < a + N; p++)
sum += *p;**注意:**数组名是被 const 保护的指针:
int a[5];
// 类似于:
int* const a;所以,数组名 a 的指向不能被改变。
int a[5], b[10];
a = b; // wrong
a++; // wrong这一限制不会给我们造成什么损失:我们可以把 a 赋值给一个指针变量,然后改变该指针变量:
p = a;
p++;前面我们讲过一个逆序输出数列的程序。
原来的程序利用下标来访问数组中的元素。我们用指针的算数运算取代数组的取下标操作:
#include<stdio.h>
#define SIZE 5
int main(void) {
int a[SIZE];
int* p;
printf("Enter %d numbers: ", SIZE);
for (p = a; p < a + SIZE; p++)
scanf("%d", p);
printf("Reverse array: ");
for (p = a + SIZE - 1; p >= a; p--)
printf("%d ", *p);
printf("\n");
return 0;
}数组名在传递给函数时,总是被视为指针。
-
在给函数传递普通变量时,变量的值会被复制;任何对形参的改变都不会影响到实参。
在给函数传递数组时,数组本身没有复制,而是将首元素的指针赋值给形参;所以对数组形参的改变是可以改变实参的。
比如我们之前写的将数组的每个元素赋值为 0
void store_zero(int a[], int n){ int i; for(i = 0; i < n; i++) a[i] = 0; }
为了指明数组形参不能被改变,可以在其声明中包含单词 const :
void find_largest(const int a[], int n){ }
如果参数有 const,编译器会核实 find_largest 函数体中确实没有对 a 中元素的赋值。
-
因为向函数传递数组没有对数组进行复制,所以传递大数组不会降低效率,浪费空间。
-
可以把数组型形参声明为指针。例如:
void find_largest(int* a, int n){ }
声明 a 是指针就相当于声明它是数组。编译器把这两类声明看作是完全一样的。
注意:
对形参而言,声明为数组和指针是一样的;但是对变量而言,这是不同的。声明
int a[10];
编译器会预留 10 个整数的空间,但声明
int* a;
编译器只会预留一个指针变量的空间。在后一种情况下,a 不是数组,试图把它当作数组来使用可能会导致糟糕的后果。例如:
*a = 0;
因为我们不知道 a 指向哪里,修改 a 指向的对象的结果是无法预料的。
-
可以给向形参传递数组“片段”。比如:
largest = find_largest(&a[5], 10);
上面函数调用的含义就是:从 a[5] 开始检查,检查 10 个元素,从中找出最大值。
既然数组名可以作为指针,指针也是可以看作数组名进行取下标操作的。
#define N 10
int a[N], *p = a,sum = 0, i;
for(i = 0; i < N; i++)
sum += p[i];编译器将 p[i] 看作是 *(p + i) 。后面我们会进一步讨论它的其他用法。
指针可以指向多维数组的元素。简单起见,我们在这里只讨论二维数组,但所有内容可以应用于更高维的数组。
如果把多维数组看作一维数组,可以这样遍历数组:
#include<stdio.h>
#define ROW 2
#define COL 3
int main(void) {
int a[ROW][COL] = {
{1, 2, 3},
{4, 5, 6}
};
for (int* p = &a[0][0]; p <= &a[ROW - 1][COL - 1]; p++)
printf("%d ", *p);
printf("\n");
return 0;
}p 从数组的第一个元素地址开始遍历到数组的最后一个元素的地址。
虽然这种写法对大多数 C 的编译器都是合法的。但是明显破坏了程序的可读性,对一些老的编译器来说这种方法提高了效率。但是对许多现代编译器这样所获得的速度优势往往极少甚至没有。
以下内容初学者可以仅作了解即可
为了访问到二维数组的第 i 行的元素,需要初始化 p 使其指向第 i 行的首元素:
p = &a[i][0];等价于:
p = a[i];原理:对于任意数组 a 来说,a[i]等价于 *(a + i)。因此,对于二维数组来说,&a[i][0]等同于 &(*(a[i] + 0)),因为 & 和 * 可以抵消,所以该表达式等价于a[i]
对上面的二维数组第一行的遍历可以这样写:
for (int* p = a[0]; p < a[0] + COL; p++)
printf("%d ", *p);对于 find_largest 函数来说,我们可以传入某一行的首元素地址,然后让它帮我们计算该行的最大元素:
find_largest(a[i], COL);处理列就要复杂一些。下面的循环遍历数组第 i 列:
int (*p)[COL];
for (p = &a[0]; p < &a[ROW]; p++)
printf("%d ", (*p)[i]);这里把 p 声明为指向长度为 COL 的整型数组的指针。在声明 int (*p)[COL] 中 *p 是需要带括号的,如果没有括号,编译器将认为 p 是指针数组,而不是指向数组的指针。表达式 p++ 将 p 移动到下一行开始的位置。表达式 (*p)[i] 中,*p 代表 a 的一整行,因此 (*p)[i] 选中了该行第 i 列那个元素;括号也是必要的,因为编译器会将 *p[i] 解释为 *(p[i])
对于多维数组 int a[ROW][COL] 来说,a 不是指向 a[0][0] 的指针而是指向 a[0]的指针。从 C 语言的观点来看,这样是有意义的。C 语言不认为 a 是二维数组而是一维数组,且这个一维数组每个元素又是一个一维数组。用作指针时,a 的类型是 int (*)[COL](指向长度为 COL 的整型数组的指针) 。
了解 a 指向的是 a[0] 有助于简化处理二维数组元素的循环。例如,简化上面的遍历数组第 i 列的循环:
int (*p)[COL];
for (p = a; p < a + ROW; p++)
printf("%d ", (*p)[2]);调用 find_largest 找到数组最大的元素时,如果我们这样写:
find_largest(a, ROW * COL);这条语句不能通过编译,因为 find_largest 函数期望的实际类型是 int* 而 a 的类型是 int (*)[COL] 。正确的调用写法是:
find_largest(a[0], ROW * COL);a[0]指向 0 行的第 0 个元素。
程序圆寄语:
以上部分可以说是到目前为止我们接触到的指针的最难的层面了。如果你看不懂,那请往下看:
如果你是初学者,那这部分内容对你太过于深了。不建议你现在着急去搞懂它,你需要大量的应用指针编程练习才能对指针有一个比较立体的认识。你只需要掌握前 3 部分内容即可。
如果你在看这篇文章之前已经学过了指针,并且想搞懂这部分内容,那可以去我的【C 进阶】系列查看相关的文章。
后面很快我们就会回过头来继续深挖指针,敬请期待!
略。
参考资料:《C语言程序设计:现代方法》
Footnotes
-
程序终将成为洛可可,然后是碎石。Epigrams on Programming 编程警句 ↩