How to understand the CrowdComp dataset #2
Comments
|
My research requires this dataset very much, but I cannot find it. Do you still have the source of this dataset or the source of the dataset? Could you please provide some information on the source of the dataset? Thank you very much. |
|
I have found this dataset, and I understand it this way. This table is more like the results returned by a complete questionnaire design. The previous ones are all explanatory information, regardless of the order of the experimental results, in Input Source ConceptBase and Input TargetConceptBase represents the two knowledge points currently being inquired about. In the AF-AL column of the table, the statistical results are presented. |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
I see that for each row there's an answer that says if there's a relation or not and an approval score that tells you how much you should trust that value.
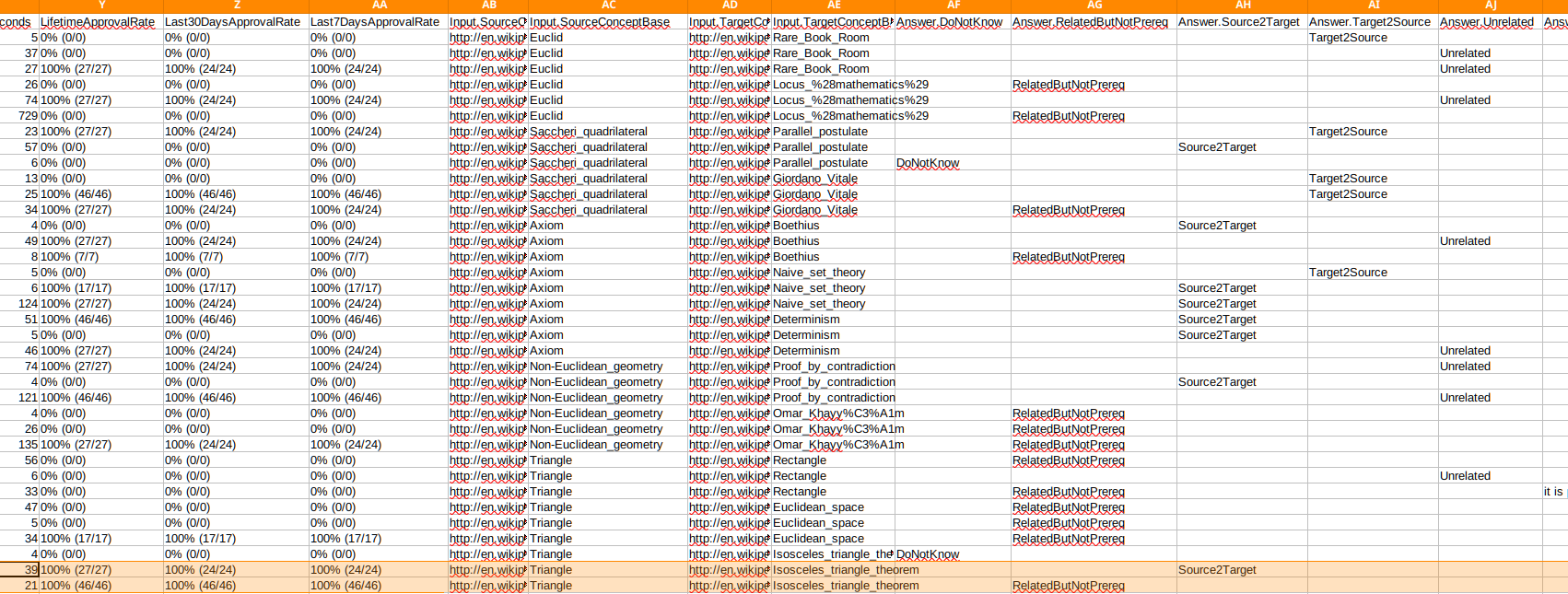
The problem is that many A B pairs have multiple rows with different answers and an approval score of 100%, like these highlighted rows for example:
These two rows contradict each other but at the same time they both are deemed as trusted sources.
Am I reading the dataset wrong? Or how are you supposed to deal with these scenarios?
The text was updated successfully, but these errors were encountered: