Model Parallelism for Bert Models #10151
Comments
|
We already have naive vertical MP implemented in t5 and gpt, and there is a much easier version of Bart MP - but it's not merged (#9384). The problem with naive MP is that it's very inefficient. That's why at the moment the rest of transformers isn't being ported. Until then try HF Trainer DeepSpeed integration: https://huggingface.co/blog/zero-deepspeed-fairscale Pipeline is the next in line, but it's very complicated. Naive vertical MP is Pipeline with chunks=1. See my work in progress notes on Parallelism: #9766 |
|
Thanks @stas00 for sharing your work. I'll implement DeepSpeed with HF.. |
|
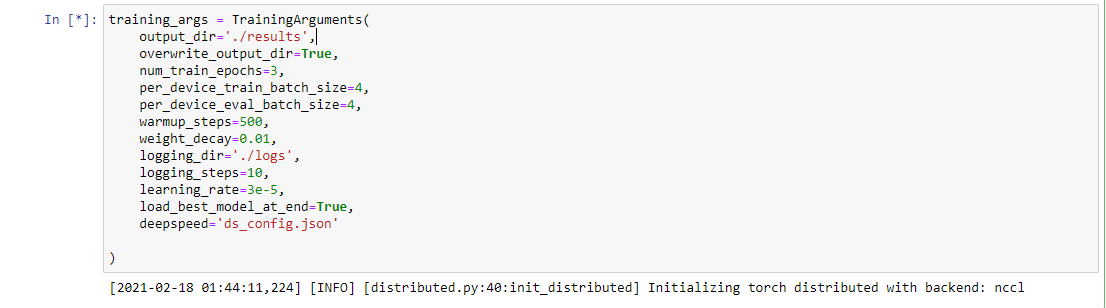
Hi @stas00 , As mentioned above, I installed deepspeed and used HF Trainer to train instead of native pytorch. Without DeepSpeed, I'm able to complete the training but with DeepSpeed, execution is stuck at - complete log is - I'm passing below in cmd - Here's my simple script - Plz let me know if I missed anything.. |
|
This looks like a pytorch distributed issue, can you launch your script as following? Deespeed requires a distributed env even with one gpu. so in this experiment we remove DeepSpeed completely but launch a similar distributed environment for a single process. What's the output of: Also, I'm noticing your trying to run it from a notebook. This could be related as well. Any reason why you're not using a normal console? Are you on colab or some restricted environment? Though I checked I can launch deepspeed just fine from the notebook. via Alternatively you can launch your script via the native notebook, i.e. no script, using this: But let's see if we can resolve the distributed hanging, by first ensuring your are on a recent pytorch. I see bug reports for this in older pytorch versions (from 2018-2019) |
|
Hi @stas00 , with the above command, execution got hanged and below is the output - I'm using transformers-4.3.0 and below is the detailed output for I am using kubeflow notebook servers provided by my company. So that's why I'm running commands in notebook itself.. I tried by setting env variables as mentioned in https://huggingface.co/transformers/master/main_classes/trainer.html#deployment-in-notebooks and execution got hanged in below cell - |
|
Thank you for your detailed answers, @saichandrapandraju It feels like your environment can't run pytorch distributed. Here is a very simple test to check that the launcher + dist init works: you can copy-n-paste it as is into a new cell including bash magic and then run it. It should print And if it fails, perhaps trying a different backend instead of If this test fails let me know and I will ask if Deepspeed can support any other way. Normally distributed isn't needed for 1 gpu, but since the cpu acts as a sort of another gpu, they use the distributed environment to communicate between the two units. |
|
This looks like a potential thread to explore for the hanging " Initializing torch distributed with backend: nccl ": See if you have any luck identifying the problem with the suggestions in that thread. |
|
Hi @stas00 , with below command it got hanged again But returned same after trying https://discuss.pytorch.org/t/unexpected-hang-up-when-using-distributeddataparallel-on-two-machines/92262 Below versions are different. Is it fine? |
|
So this is a pure pytorch issue, you may want to file an Issue with pytorch: https://github.com/pytorch/pytorch/issues If you can't launch distributed then DeepSpeed won't work for you. Also I'd try pytorch-nightly - I read in one thread they have been tweaking this functionality since the last release. https://pytorch.org/get-started/locally/ - you should be able to install that locally.
Shouldn't be a problem. Pytorch comes with its own toolkit. This system-wide entry is useful for when building pytorch CPP extensions (which incidentally Deepspeed is). There ideally you want to have the same version for both, but sometimes minor version difference is not a problem. |
|
Thanks @stas00 , Raised an issue pytorch/pytorch#52433 and https://discuss.pytorch.org/t/hanging-torch-distributed-init-process-group/112223 Even I'm thinking of nightly. Will give it a try... |
|
If this is sorted out, I hope HFTrainer and deepspeed will work with single and multi gpu setting.. |
|
I'd help for you to augment your pytorch Issue with the information they request - at the very least the output of |
|
Thanks @stas00 , I installed But it got hanged again with script and below are the logs - Also tried with nightly build( used the same script for both - Updated same in pytorch issues and forums as well ... |
That's a good step forward, I'm glad it worked. From what I understand system-wide cuda shouldn't have impact on whether distributed works or not, but clearly in your case it did. How can I reproduce your setup? I don't know where you got your dataset from. As suggested earlier if you want to save my time, please setup a public google colab notebook (free) and then me and others can easily look at the situation without needing to figure out how to set up our own. |
|
Hi @stas00 , Here is the colab version of my script. I used IMDB from kaggle in local but in colab I gave a download and extractable version. Also, I included torch and transformers versions that I'm using. |
|
Thank you, but have you tried running it? It fails in many cells, perhaps I wasn't clear but the idea was to give us a working notebook and then it's easier to spend the time trying to understand the problem, rather than trying to figure out how to make it run - does it make sense? |
|
Hmm, you're running on a system with multi-gpus, correct? In one threads I found out that if a vm is used and NVLink they may not work unless properly configured, and that person solved the problem with: which disables NVLink between the 2 cards and switches to the slower PCIe bridge connection. Could you try and check that this is not your case? |
|
So sorry for that.. I have 3 VM's where 1 is having 2 GPU's and rest with single GPU. Currently I'm trying in one of the VM with single GPU and if everything is fine we'll replicate this to 2 GPU VM or combine all 4 V100-32GB GPU's for bigger models. This is the higher level roadmap.
I tried exact colab that I shared in my notebook server and it is hanging here -
same with But now it's not hanging at ' Initializing torch distributed with backend: nccl ' anymore - |


|
Will there be any potential configuration issue..? |
|
Hi @stas00 , It's working with both of the below were working now - and Not sure exactly what it's doing internally. I will check in other scenarios like multi-GPU and let you know... |
|
Yay, so glad to hear you found a solution, @saichandrapandraju! Thank you for updating the notebook too! If the issue has been fully resolved for you please don't hesitate to close this Issue. If some new problem occurs, please open a new dedicated issue. Thank you. |
|
Tested DeepSpeed on multi-GPU as well and it worked !! By setting Thanks a lot @stas00 |
Hi,
I'm trying to implement Model parallelism for BERT models by splitting and assigning layers across GPUs. I took DeBERTa as an example for this.
For DeBERTa, I'm able to split entire model into 'embedding', 'encoder', 'pooler', 'classifier' and 'dropout' layers as shown in below pic.
With this approach, I trained on IMDB classification task by assigning 'encoder' to second GPU and others to first 'GPU'. At the end of the training, second GPU consumed lot of memory when compared to first GPU and this resulted in 20-80 split of the entire model.
So, I tried splitting encoder layers also as shown below but getting this error - "TypeError: forward() takes 1 positional argument but 2 were given"
Plz suggest how to proceed further..
The text was updated successfully, but these errors were encountered: