Project Page | Paper | BiVLC Collection | BiVLC Dataset | TROHN-Text Dataset | TROHN-Img Dataset
This is the official implementation for the paper BiVLC: Extending Vision-Language Compositionality Evaluation with Text-to-Image Retrieval
BiVLC is a benchmark for Bidirectional Vision-Language Compositionality evaluation. Each instance consists of two images and two captions. Using each of the images and captions as a base, a model is asked to select the pair that correctly represents the base versus the hard negative distractor with minor compositional changes. Thus, we can measure image-to-text and text-to-image retrieval with hard negative pairs. To obtain good results on the dataset, it is necessary that the model performs well in both directions for the same instance.

Each instance of the dataset consists of six fields:
- image: COCO 2017 validation image.
- caption: COCO 2017 validation text describing the COCO image.
- negative_caption: Negative caption generated from the COCO 2017 validation text description by SugarCrepe.
- negative_image: Negative image generated from the negative caption by BiVLC.
- type: Category of the negative instances: Replace, Swap or Add.
- subtype: Subcategory of the negative instances: Object, Attribute or Relation.
To load data with datasets:
>>> data = load_dataset("imirandam/BiVLC", split = "test")Each instance has the following structure:
{
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=500x332 at 0x7F9BFC0C5430>,
'caption': 'A man throwing a ball while smiling and on a field.',
'negative_caption': 'A man throwing a ball while a child is smiling on a field.',
'negative_image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=512x512 at 0x7F9BE45571C0>,
'type': 'add',
'subtype': 'obj',
}
test: 2,933 instances formed by 2 images and 2 captions. 11,732 retrieval instances, 50% text-to-image and 50% image-to-text.

- image and caption are from COCO 2017 validation split.
- negative_caption is a text description generated from the COCO caption by SugarCrepe.

Step 1 - Uniformly format positive and hard negative captions
Step 2 - Generate hard negative images
Step 3 - Ask to human annotators to choose the best generated image
Step 4 - Filter ambiguous instances

If you need training and validation data, you can use the datasets proposed in the paper in the following links, TROHN-Text and TORHN-Img.
Results for SOTA models on SUGARCREPE and BIVLC. For the later, we provide the three metrics I2T, T2I and Group score. Human and random performance are also depicted. Bold for the best of each model family (contrastive and generative).
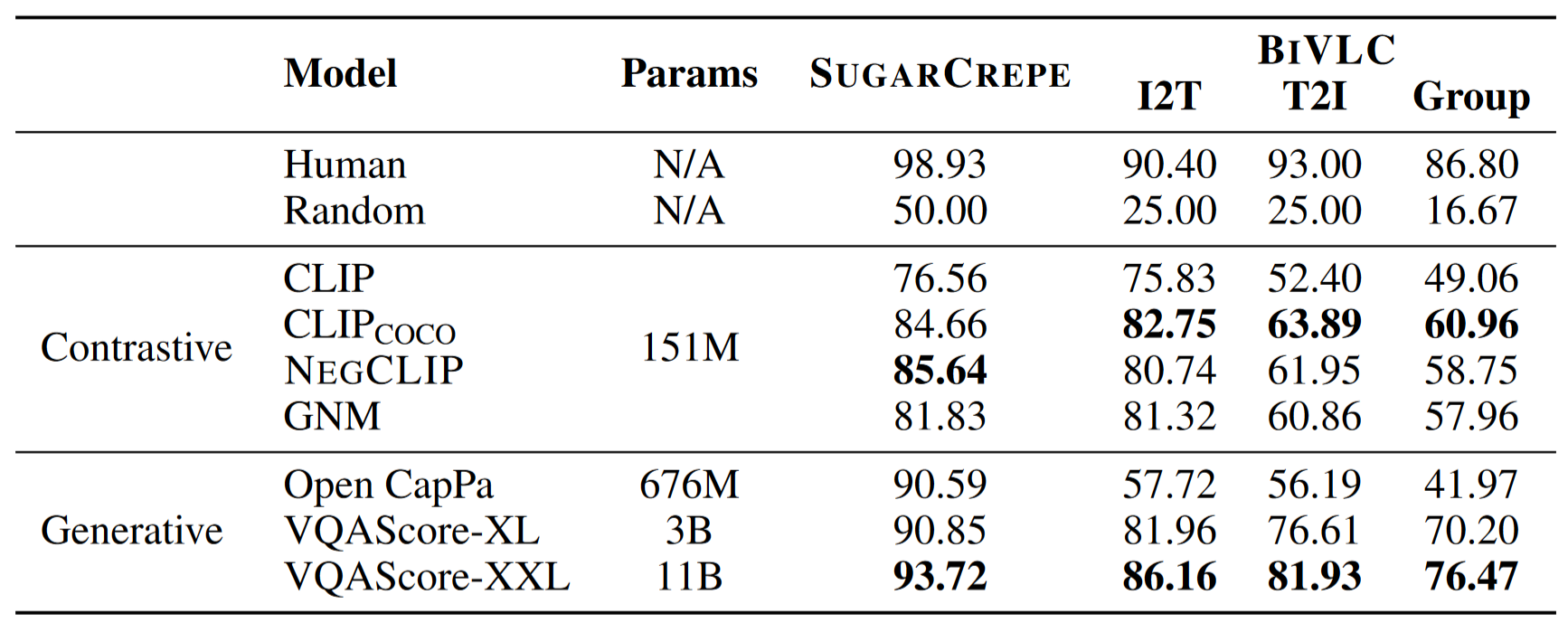
- Contrary to humans, current models underperform on text-to-image retrieval.
- The gap to humans is bigger in BiVLC than in SugarCrepe.
- SugarCrepe and BIVLC performance are not correlated.
We propose two new models:
- CLIPTROHN-TEXT using hard negative texts.
- CLIPTROHN-IMG using hard negative texts and images.
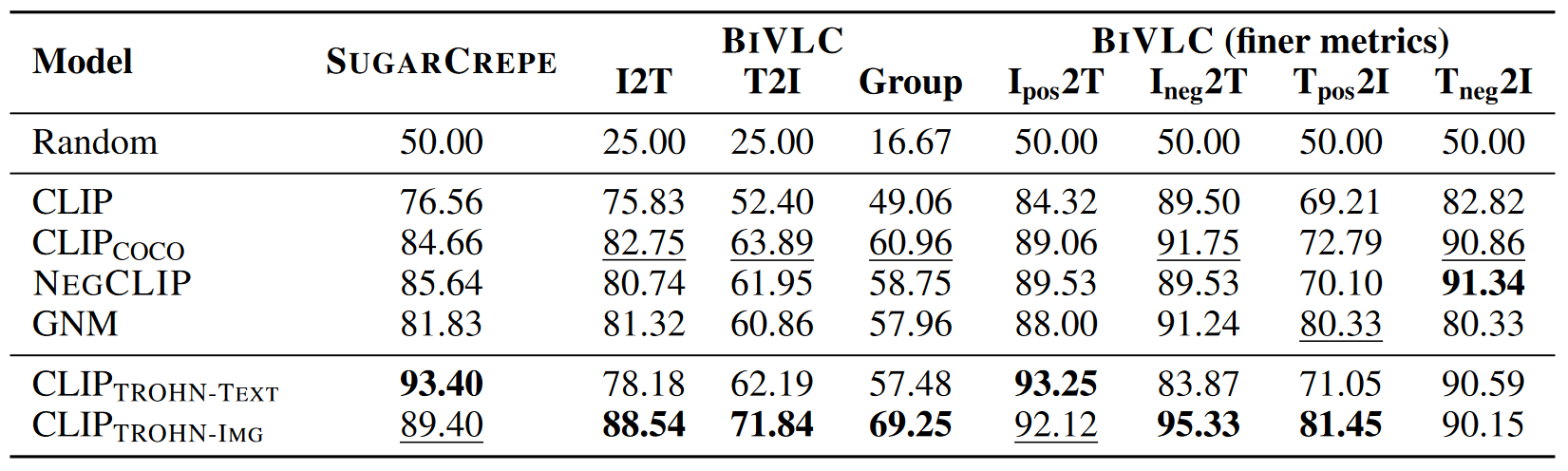
Finding: Training with hard negative images can boost the performance of multimodal contrastive models.
.
├── source_data # Directory for source data
│ ├── COCO_2017 # Folder to save COCO 2017
│ └── SugarCrepe # Folder to save SugarCrepe
│ └── concat_SugarCrepe.py # SugarCrepe 7 json files into 1 csv
├── src # Data generation and training code
│ ├── BiVLC_Generation # BiVLC data generation
│ │ ├── imgs # Folder to save the generated imgs
│ │ └── BiVLC_img_generation.py # Image generation
│ ├── Training_data # Train and val data generation
│ │ ├── TROHN-Text # TROHN-Text data generation
│ │ │ ├── data # Folder to save generated negative captions
│ │ │ └── TROHN_Text_generation.py # Negative caption generation
│ │ └── TROHN-Img # TROHN-Img data generation
│ │ ├── data # Folder to save the scored negative captions
│ │ ├── imgs # Folder to save generated negative images
│ │ ├── adversarial_refine.py # Adversarial refinement from SugarCrepe
│ │ ├── TROHN_Img_scoring.py # Scoring TROHN-Text negative captions
│ │ ├── TROHN_Img_best_selection.py # Selecting best negative captions
│ │ └── TROHN_Img_generation.py # Image generation
│ ├── CLIP_fine_tuning # CLIP fine-tuning code and ckpts
│ │ ├── ckpt # Folder to save the CLIP Checkpoints
│ │ ├── CLIP_fine_tuning.py # CLIP fine-tuning
│ │ ├── CLIP_utils.py # load model, load data, evaluations
│ │ └── scheduler.py # Cosine scheduler from OpenCLIP
│ └── Detectors # Detectors training and evaluation
│ ├── results # Detector results
│ ├── classifier_ckpt # Folder to save the classifier checkpoints
│ ├── Detector_img_classifier.py # Training img detector
│ ├── Detector_text_classifier.py # Training text detector
│ ├── Detector_evaluation_BiVLC.py # BiVLC detector evaluation
│ ├── Detector_evaluation_SugarCrepe.py # SugarCrepe detector evaluation
│ └── Detector_utils.py # load model, load data
├── main_evaluation_BiVLC.py # Contrastive models main evaluation
├── evaluation_SugarCrepe.py # Contrastive models SugarCrepe evaluation
├── VQAScore_BiVLC.py # VQAScore models main evaluation
├── VQAScore_SugarCrepe.py # VQAScore models SugarCrepe evaluation
├── OSCapPa_BiVLC.py # OSCapPa model main evaluation
├── OSCapPa_SugarCrepe.py # OSCapPa model SugarCrepe evaluation
├── results # BiVLC and SugarCrepe results
└── requirements.txt # List of libraries needed
git clone https://github.com/IMirandaM/BiVLC.git
cd BiVLC
python3 -m venv BiVLC # Create env
source BiVLC/bin/activate # Load env
pip3 install -r requirements.txt # Install dependenciesThis section provides instructions for downloading all the data needed to reproduce the results of the paper.
IMPORTANT: If you want to evaluate only BiVLC there is no need to download any data. If you want to evaluate SugarCrepe you need to download the SugarCrepe json files and the COCO 2017 Val images. If you want to reproduce the whole implementation, download all the data.
Download the COCO 2017 data from the official website, https://cocodataset.org/#download.
- Download the COCO 2017 Train/Val annotations and save captions_train2017.json in the BiVLC/source_data/COCO_2017 directory.
- Download the COCO 2017 train and val images and save the unzipped folders in the data_source/COCO_2017 directory as train2017 and val2017.
Resulting in:
├── source_data
│ └── COCO_2017
│ ├── captions_train2017.json
│ ├── train2017
│ └── val2017
Download SugarCrepe data in BiVLC/source_data/SugarCrepe from the official repository, https://github.com/RAIVNLab/sugar-crepe/tree/main/data.
Then we concatenate the 7 json files into a single CSV.
python source_data/SugarCrepe/concat_SugarCrepe.pyModel checkpoints are hosted in HuggingFace repositories. You only need to download the .pt files.
We have fine-tuned three different CLIP models. Download the .pt files from the following links, we recommend saving them in the following folder src/CLIP_fine_tuning/ckpt.
We have trained two detectors. Download the best_image and best_text .pt files from the following links, we recommend saving them in the following folder src/Detectors/classifier_ckpt.
NOTE: Alternatively you can download the checkpoints using HuggingFace-hub. For example:
from huggingface_hub import hf_hub_download
hf_hub_download(repo_id="imirandam/CLIP_COCO", filename="best_CLIP_COCO_9.pt", local_dir = "./src/CLIP_fine_tuning/ckpt")repo_id = HuggingFace repository
filename = checkpoint_name.pt
local_dir = directory to save the checkpoint
This section will show how to reproduce evaluations in BiVLC and SugarCrepe datasets.
python main_evaluation_BiVLC.py \
--model-checkpoint 'src/CLIP_fine_tuning/ckpt/best_CLIP_TROHN-Img_9.pt' \
--run_name 'CLIP_TROHN-Img'Note: In the above example we only evaluate CLIP_TROHN-Img, to evaluate any other model just change the --model-checkpoint argument and add a --run_name to identify it.
We provide the checkpoints of our models in HuggingFace repositories (See Download checkpoints section above), for NegCLIP and GNM models you should download their checkpoints directly from their official repositories. To evalute the baseline model simply do not add the --model-checkpoint argument.
To evaluate this model you will need to prepare the environment as described in the official repository CLIP-JAX, and also install the datasets library.
python OSCapPa_BiVLC.py \
--local_dir 'Define path'Note In --local_dir Define the folder where you want to save the model
To evaluate this model you will need to prepare the environment as described in the official repository t2v_metrics, and also install the datasets library.
python VQAScore_BiVLC.py \
--model 'clip-flant5-xxl'Note: In the above example we evaluate clip-flant5-xxl, change the --model argument to 'clip-flant5-xl' to evaluate the XL model.
To evaluate the different models in SugarCrepe change the model checkpoints and run names as in the BiVLC evaluation.
python evaluation_SugarCrepe.py \
--model-checkpoint 'src/CLIP_fine_tuning/ckpt/best_CLIP_TROHN-Img_9.pt' \
--run_name 'CLIP_TROHN-Img'To evaluate this model you will need to prepare the environment as described in the official repository CLIP-JAX.
python OSCapPa_SugarCrepe.py \
--local_dir 'Define path'Note In --local_dir Define the folder where you want to save the model
To evaluate this model you will need to prepare the environment as described in the official repository t2v_metrics.
python VQAScore_SugarCrepe.py \
--model 'clip-flant5-xxl'Note: In the above example we evaluate clip-flant5-xxl, change the --model argument to 'clip-flant5-xl' to evaluate the XL model.
In this section we present instructions for replicating the data generation, fine-tuning of the CLIP models and training of the detectors.
The data generation is divided into two parts, on the one hand the generation of the BiVLC benchmark and on the other hand, the training data sets, TROHN-Text and TROHN-Img.
To create BiVLC we relied on SugarCrepe negative captions and created 4 images for each caption with SDXL-DPO model. Then, through two phases of crowdsourcing, we kept the best images (see dataset curation section).
accelerate launch --num_processes=4 src/BiVLC_Generation/BiVLC_img_generation.pyNote: We have used 4 GPUs for the execution, if you want to use a different number modify --num_processes= number of GPUs.
To create TROHN-Text we have used the COCO 2017 train captions, the LLM OpenChat 3.5-0106 and the templates provided by Sugarcrepe. We have created a negative caption for the proposed subcategories in SugarCrepe for each of the COCO 2017 train captions.
python src/Training_data/TROHN_Text/TROHN_Text_generation.pyTo create TROHN-Img we used the negative captions generated for TROHN-Text. As image generation requires a lot of computational power and time, we filtered the negative captions based on plausibility and linguistic acceptability scores to obtain the best ones.
python src/Training_data/TROHN_Img/TROHN_Img_scoring.py
python src/Training_data/TROHN_Img/TROHN_Img_best_selection.pyOnce we have the best captions, we generate an image for each caption with the SDXL-DPO model.
accelerate launch --num_processes=6 src/Training_data/TROHN_Img/TROHN_Img_generation.pyNote: We have used 6 GPUs for the execution, if you want to use a different number modify --num_processes= number of GPUs.
We have fine-tuned 3 CLIP models with different data, COCO 2017 train, TROHN-Text and TROHN-Img.
python src/CLIP_fine_tuning/CLIP_fine_tuning.py \
--dataset 'COCO' --run_name 'CLIP_COCO'Note: In the above code, we fine-tuned CLIP with the COCO 2017 training dataset, change --dataset to 'TROHN-Text' or 'TROHN-Img' for the other two fine-tunings. Also, change --run_name to CLIP_TROHN-Text or CLIP_TROHN-Img to be able to identify the checkpoints correctly.
We have trained natural vs synthetic image and text detectors. To train the text detector.
python src/Detectors/Detector_text_classifier.py \
--model-checkpoint 'src/CLIP_fine_tuning/ckpt/best_CLIP_TROHN-Img_9.pt' \
--run_name 'CLIP_TROHN-Img'To train the image detector.
python src/Detectors/Detector_img_classifier.py \
--model-checkpoint 'src/CLIP_fine_tuning/ckpt/best_CLIP_TROHN-Img_9.pt' \
--run_name 'CLIP_TROHN-Img'Note: To train with the baseline model encoders simply do not add the --model-checkpoint argument.
python src/Detectors/Detector_text_classifier.py \
python src/Detectors/Detector_img_classifier.py \We evaluated the detectors in BiVLC.
python src/Detectors/Detector_evaluation_BiVLC.py \
--image-checkpoint 'src/Detectors/classifier_ckpt/best_image_CLIP_TROHN-Img_0.pt' \
--text-checkpoint 'src/Detectors/classifier_ckpt/best_text_CLIP_TROHN-Img_6.pt' \
--run_name 'CLIP_TROHN-Img'Note: In the previous example we evaluated the model based on the CLIP_TROHN-Img encoders, to evaluate the detector with the baseline encoders change the image-checkpoint and text-checkpoint provides in the HuggingFace repository (See Download checkpoints section above).
python src/Detectors/Detector_evaluation_BiVLC.py \
--image-checkpoint 'src/Detectors/classifier_ckpt/best_image_VIT-B-32_0.pt' \
--text-checkpoint 'src/Detectors/classifier_ckpt/best_text_VIT-B-32_7.pt' \
--run_name 'CLIP_baseline'We evaluated text detectors in SugarCrepe. To evaluate detector CLIP_TROHN-Img.
python src/Detectors/Detector_evaluation_SugarCrepe.py \
--text-checkpoint 'src/Detectors/classifier_ckpt/best_text_CLIP_TROHN-Img_6.pt' \
--run_name 'CLIP_TROHN-Img'As when evaluating in BiVLC, to evaluate the detector with the baseline model encoders just change the text-checkpoint and the run_name.
python src/Detectors/Detector_evaluation_SugarCrepe.py \
--text-checkpoint 'src/Detectors/classifier_ckpt/best_text_VIT-B-32_7.pt' \
--run_name 'CLIP_baseline'See the LICENSE file for details about the license under which code and data is made available.
If you find this repository useful in your research, please consider giving a star ⭐ and a citation
@misc{miranda2024bivlc,
title={BiVLC: Extending Vision-Language Compositionality Evaluation with Text-to-Image Retrieval},
author={Imanol Miranda and Ander Salaberria and Eneko Agirre and Gorka Azkune},
year={2024},
eprint={2406.09952},
archivePrefix={arXiv},
primaryClass={cs.CV}
}