`
This is the official implementation of the Make it Sound Good (MSG) model from our 2022 ISMIR paper "Music Separation Enhancement with Generative Modeling" [paper] [website]
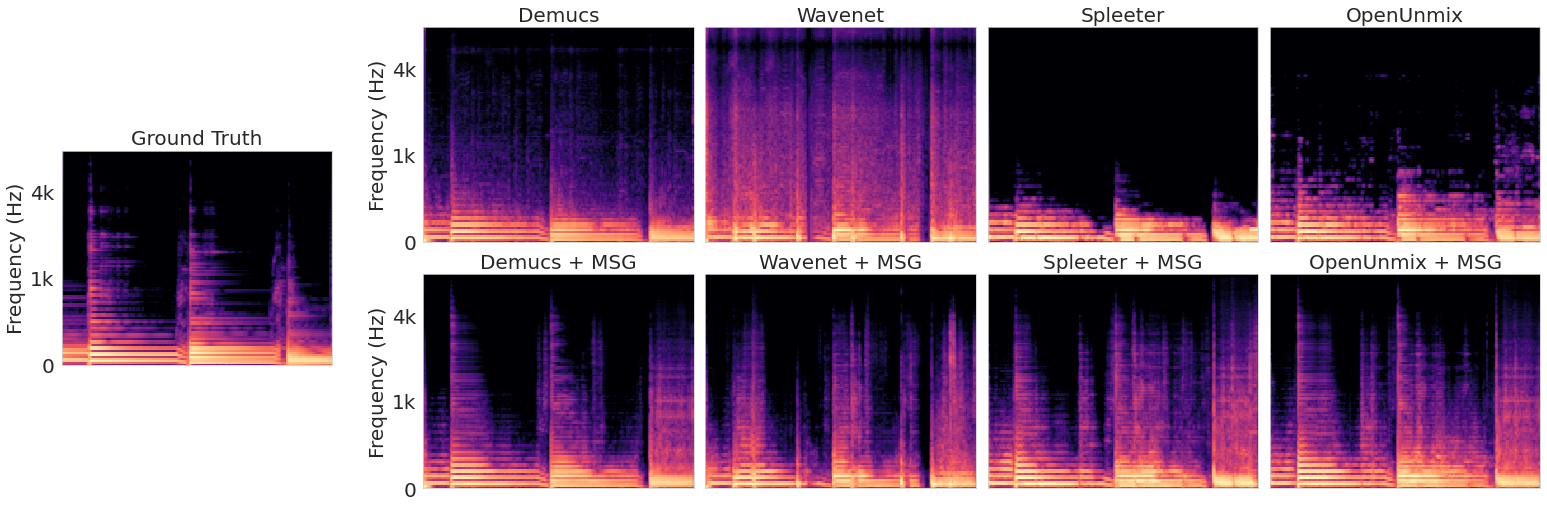
We introduce Make it Sound Good (MSG), a post-processor that enhances the output quality of source separation systems like Demucs, Wavenet, Spleeter, and OpenUnmix
- We train our model using salient source samples from the training data. To get the salient source samples, our training loop uses nussl's SalientExcerptMixSourceFolder class from the salient_mixsrc2 branch. The specific branch of the repo can be downloaded using the steps below:
$ git clone https://github.com/nussl/nussl.git
$ cd nussl
$ git checkout salient_mixsrc2
$ pip install -e .
- Download our repo from github.
$ git clone https://github.com/interactiveaudiolab/MSG.git
- Change to the MSG repo folder and download the requirements.txt.
$ cd MSG
$ pip install -r requirements.txt
- If you would like to use our pretrained checkpoints on huggingface download the model.
The directory format needs to be as follows
BaseFolder/
train/
vocals/
song1.wav
drums/
...
bass/
...
other/
...
valid/
...
test/
...
If you are training on the output of multiple separators, data from all separators must be in the same directory.
If you would like to use weights and biases, you'll need to login. (Weights and biases is integrated into our code, it should still be runable without logging in.)
To run the training loop follow the steps below:
- Copy the config template to a new file and change the parameters for file paths to match your actual file paths.
- In addition to file paths the following paramters need to be updated in the config:
a. source: list string name of the source/s getting separated for logging and dataset loading purposes. e.g: ['bass', 'drums']
b. validation_song: the file path to a specific song, this parameter allows us to see how the model's behavior changes during training using a specific example. If using weights and biases this example will be uploaded to the service.
c. song_names: Specific MSG output examples that the user would like to listen to, written locally with the corresponding song name during testing.
d. evaluation_models: Model checkpoint/s to use during evaluation if you would like to compare multiple models directly. - Run the python file main.py using the config. e.g.:
$ python main.py -e <MY_CONFIG.yml>
-
Our inference script passes an audio file through MSG loaded from a specified checkpoint. Note: The inference script is currently set to work with parameters specified in
training_config_template.yml. If you have a checkpoint with different parameters, you will need to modify the definition of the generator within the script. -
To call the inference script, use the following command
$ python Run_Inference.py -a <path to audio file> -g <path to checkpoint>
- The inference script will write to the directory
msg_outputwith the file namemsg_output/<input file name>
@inproceedings{schaffer2022music,
title={Music Separation Enhancement with Generative Modeling},
author={Schaffer, Noah and Cogan, Boaz and Manilow, Ethan and Morrison, Max and Seetharaman, Prem and Pardo, Bryan},
booktitle={International Society for Music Information Retrieval (ISMIR)},
month={December},
year={2022}
}