class: center, middle

Helge Pfeiffer, Associate Professor,
Research Center for Government IT,
IT University of Copenhagen, Denmark
ropf@itu.dk
class: center, middle
class: center, middle
Are you just counting or does it really display the latest processed event?
The purpose of the /latest end-point is to provide a status over the latest processed event from the simulator.
In case you need to change your URLs in the repositories.py file, please inform us about it.
Just sending a pull-request is not enough, since we have to restart the simulator for your group then.
After restart, the simulator continues from where it stopped.

March 8th theme from the United Nations: "Equal rights. Equal opportunities. Equal power."
In the preparation material, I was asking you:
Can you figure out the following properties of your ITU-MiniTwit with your group fellows?
- CPU load during the last hour/the last day.
- Average response time of your application's front page.
- Amount of users registered in your system.
- Average amount of followers a user has.
Keep a log of what you are doing to figure out these values.
For each of the above properties into, categorize them by potentially interested parties in an organization. For example, business department (hypothetical), operator, etc.
Which of the above categories do you consider the most important? In which role are you then?
From a technology perspective, monitoring is the tools and processes by which you measure and manage your IT systems. But monitoring is much more than that. Monitoring provides the translation between business value and the metrics generated by your systems and applications. Your monitoring system translates those metrics into a measurable user experience. That measurable user experience provides feedback to the business to help ensure it’s delivering what customers want. The user experience also provides feedback to IT to indicate what isn’t working and what’s delivering insufficient quality of service.
Your monitoring system has two customers:
The business
Information Technology
James Turnbull "The Art of Monitoring"
Monitoring is for asking questions.
—Dave Josephsen, Monitorama 2016
That is, monitoring doesn’t exist to generate alerts: alerts are just one possible outcome. With this in mind, remember that every metric you collect and graph does not need to have a corresponding alert.
Mike Julian "Practical Monitoring"
--
Important for your projects and for your future careers:
Without monitoring you are not doing your job.
James Turnbull "The Art of Monitoring"
According to James Turnbull on https://www.kartar.net/posts/a-monitoring-maturity-model.markdown/
- Manual, user-initiated, or no monitoring
- Reactive
- Proactive
- Monitoring is largely manual, user initiated, or not done at all.
- If monitoring is performed, it’s commonly managed via checklists, simple scripts, and other non-automated processes.
- The focus here is entirely on minimizing downtime and managing assets.
- Monitoring in this way provides little or no value in measuring quality of service.
- Typical in small organizations with limited IT staffing, no dedicated IT staff.
Adapted from https://www.kartar.net/posts/a-monitoring-maturity-model.markdown/
- Monitoring is mostly automatic with some remnants of manual or unmonitored components.
- Broad focus on measuring availability and managing IT assets.
- There may be some movement towards using monitoring data to measure customer experience.
- Monitoring provides some data that measures quality or service
- Most of this data needs to be manipulated or transformed before it can be used
- A small number of operationally-focused dashboards exist
- Typical in small to medium enterprises and common in divisional IT organizations inside larger enterprises
Adapted from https://www.kartar.net/posts/a-monitoring-maturity-model.markdown/
-
Monitoring is considered core to managing infrastructure and the business.
-
Monitoring is automatic and often driven by configuration management tooling.
-
Metrics will focus on measuring application performance and business outcomes rather than stock concerns like disk and CPU.
-
Performance data will be collected and frequently used for analysis and fault resolution. --
-
Focus on measuring quality of service and customer experience.
-
Monitoring provides data that measures quality or service
-
Much of this data is provided directly to business units, application teams and other interested parties via dashboards and reports. --
-
Typical in web-centric organizations and many mature startups.
-
Products will not be considered feature complete or ready for deployment without monitoring and instrumentation.
Adapted from https://www.kartar.net/posts/a-monitoring-maturity-model.markdown/

From James Turnbull "The Art of Monitoring"
- Most monitoring systems are pull/polling-based:
- E.g., Nagios usually queries monitored sub-systems
- I.e., the more hosts and services in production the more checks Nagios executes
- In a push-based architecture, hosts, services, and applications send data to a central collector.
- The collection is fully distributed on the hosts, services, and applications that emit data.
Note, Prometheus can be considered a push-based monitoring system or a hybrid as each monitored application pushes its metrics which are then pulled by the central Prometheus system.
Blackbox monitoring probes the outside of a service or application [...] You query the external characteristics of a service: does it respond to a poll on an open port, return the correct data or response code. An example of blackbox monitoring is performing an HTTP check and confirming you have received a 200 OK response code.
James Turnbull "The Art of Monitoring"
--
Whitebox monitoring instead focuses on what’s inside the service or application. The application is instrumented and returns its state, the state of internal components, or the performance of transactions or events. Most whitebox monitoring is done either via emitting events, logs and metrics to a monitoring tool, the approach we’ve detailed about in our push-based model, or exposes this information on a status page of some kind, which a pull-based system would query.
James Turnbull "The Art of Monitoring"
Synthetic, script-based
- to determine if application is up or down
- to verify availability even without current end-users
- essential to establish a performance baseline before a new release
--
Passive "sniffing" to observe what real users observe
- based on real users interaction data
- measures users' experience under their conditions, such as location etc.
Both adapted from: https://web.archive.org/web/20170601101557/https://www.moviri.com/2014/01/active-passive-monitoring/

Picture from Mike Julian "Practical Monitoring"
- Monitoring the Business
- Frontend Monitoring
- Application Monitoring
- Server Monitoring (Infrastructure Monitoring)
- Network Monitoring
- Security Monitoring
From Mike Julian "Practical Monitoring"
Business stakeholders ask other questions than software developers.
Key Performance Indicators (KPI) should be able to tell how a business is doing.
With regards to our ITU-MiniTwit these might be questions like:
- Are users able to use ITU-MiniTwit in their daily lives?
- Are the numbers of active users growing, declining, or stagnant?
- Are the users happy?
- Can we/are we making money?
- Are we profitable?
--
Possible metrics:
- Net promoter score
- Revenue per customer
- Cost per customer
- Burn rate
- ...
For Mike Julian in "Practical Monitoring" the frontend are all artifacts "that are parsed and executed on the client side via a browser or native mobile app. When you load a web page, all of the HTML, CSS, JavaScript, and images constitute the frontend."
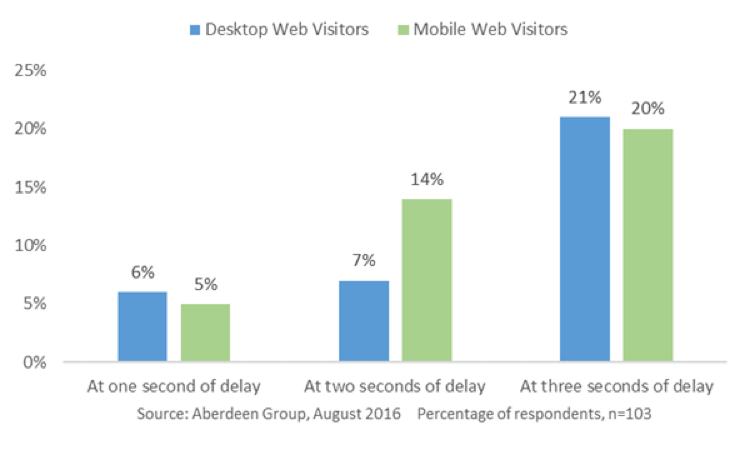
Around 5% of organizations say that users have left their website after a one second delay. [...] After a two second delay, the abandonment rate stays about the same for traditional, browser-based desktop web users, but the rate of abandonment for mobile websites nearly triples.
https://www.aberdeen.com/cmo-essentials/aberdeens-surprising-insights-2016/
--
Amazon:
Every 100ms delay costs 1% of sales
Instrumenting applications with metrics. This is what we a going to do today, see below.
Example questions:
- How long do our database queries take?
- How long does some external vendor API takes to respond?
- How many logins happen throughout the day?
https://www.digitalocean.com/docs/monitoring/how-to/install-agent/

https://collectd.org/$ top
top - 14:24:42 up 13 days, 23:42, 1 user, load average: 0.00, 0.00, 0.00
Tasks: 85 total, 1 running, 46 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.3 us, 0.3 sy, 0.0 ni, 99.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 1009172 total, 187524 free, 98916 used, 722732 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 728164 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
29200 root 20 0 44540 4112 3520 R 0.3 0.4 0:00.04 top
1 root 20 0 159928 9500 7056 S 0.0 0.9 0:10.70 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.01 kthreadd
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H$ uptime
15:50:34 up 14 days, 1:08, 1 user, load average: 0.00, 0.00, 0.00$ free -m
total used free shared buff/cache available
Mem: 985 96 183 0 705 711
Swap: 0 0 0Finding if a program was killed (by OOMKiller) due to excessive memory consumption:
$ grep -i -r 'killed process' /var/log/
$ dmesg | grep -i 'killed process'sudo apt-get install iftop
sudo apt-get install nethogs$ iftop
12.5Kb 25.0Kb 37.5Kb 50.0Kb 62.5Kb
└───────────────┴───────────────┴───────────────┴───────────────┴───────────────
webserver => nat-10.itu.dk 4.34Kb 4.57Kb 4.55Kb
<= 2.23Kb 2.23Kb 2.21Kb
webserver => 67.207.67.3 0b 0b 48b
<= 0b 0b 81b
webserver => static-28.108.248.49-tata 0b 0b 16b
<= 0b 0b 21b
webserver => 185.156.73.54 0b 0b 8b
<= 0b 0b 16b
────────────────────────────────────────────────────────────────────────────────
TX: cum: 49.2KB peak: 6.25Kb rates: 4.34Kb 4.57Kb 4.62Kb
RX: 28.0KB 4.23Kb 2.23Kb 2.23Kb 2.33Kb
TOTAL: 77.2KB 9.73Kb 6.58Kb 6.80Kb 6.95Kb
$ nethogs
NetHogs version 0.8.5-2
PID USER PROGRAM DEV SENT RECEIVED
29948 root sshd: root@pts/0 eth0 0.757 0.490 KB/sec
? root ...225.103.230:21-104.206 0.000 0.000 KB/sec
? root ...225.103.230:4071-45.13 0.000 0.000 KB/sec
? root ...225.103.230:23-75.165. 0.000 0.000 KB/sec
28239 do-age.. ..pt/digitalocean/bin/do- eth0 0.000 0.000 KB/sec
? root unknown TCP 0.000 0.000 KB/sec
TOTAL 0.757 0.490 KB/sec
$ df -h
Filesystem Size Used Avail Use% Mounted on
udev 481M 0 481M 0% /dev
tmpfs 99M 620K 98M 1% /run
/dev/vda1 29G 4.9G 25G 17% /
tmpfs 493M 0 493M 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 493M 0 493M 0% /sys/fs/cgroup
/dev/vda15 105M 3.6M 101M 4% /boot/efi
tmpfs 99M 0 99M 0% /run/user/0
$ du -hSee chapters 9 and 10 in Mike Julian "Practical Monitoring". I skip them here as they are likely part of the security class and out of scope of this class.
Likely, once Mircea talks to you about security, you might want enhance you monitoring setup including some security concerns.
- Nagios https://www.nagios.com/products/nagios-log-server/
- Munin http://munin-monitoring.org/
- Netdata https://my-netdata.io/
- Shinken http://www.shinken-monitoring.org/
- StatsD https://github.com/statsd/statsd
- Prometheus https://prometheus.io/
... and many more
Monitoring with Prometheus (https://prometheus.io/)
- Basically a time series key-value storage
- Supports both, pulling and pushing data
- We will only use data pull
- Targets (for pulling) via service discovery or config
- client libraries for instrumenting application code

- Go
- Java or Scala
- Python
- Ruby
- Rust
Unofficial third-party client libraries:
- Bash
- C and C++
- Common Lisp
- Dart
- Elixir and Erlang
- Haskell
- Lua for Nginx and Tarantool
- .NET / C#
- Node.js
- OCaml
- Perl
- PHP
- R
See, https://prometheus.io/docs/instrumenting/clientlibs/
The client libraries offer four core metric types:
- Counter
- Gauge
- Histogram
- Summary
They are only differentiated in the client libraries. The Prometheus server currently flattens all data into untyped time series.
See: https://prometheus.io/docs/concepts/metric_types/

$ git clone git@github.com:itu-devops/itu-minitwit-monitoring.git
$ cd itu-minitwit-monitoring
$ docker compose up --build
OBS: Remember that this example runs a single application without any proper web server, load balancer, or similar "in front" of it. In case you want to collect metrics of one "logical" application running as many instances you might want to read the following for an example of how to solve it: https://blog.codeship.com/monitoring-your-synchronous-python-web-applications-using-prometheus/
ITU-MiniTwit at http://localhost:5000

ITU-MiniTwit Metrics for This Node at http://localhost:5000/metrics

The Prometheus Web-client at http://localhost:9090

Grafana at http://localhost:3000
Default login and password: admin

The dependency to the Prometheus client library in requirements.txt:
prometheus_client==0.7.1
from prometheus_client import Counter, Gauge, Histogram
from prometheus_client import generate_latest
CPU_GAUGE = Gauge(
"minitwit_cpu_load_percent", "Current load of the CPU in percent."
)
REPONSE_COUNTER = Counter(
"minitwit_http_responses_total", "The count of HTTP responses sent."
)
REQ_DURATION_SUMMARY = Histogram(
"minitwit_request_duration_milliseconds", "Request duration distribution."
)
# Add /metrics route for Prometheus to scrape
@app.route("/metrics/")
def metrics():
return Response(
generate_latest(), mimetype="text/plain; version=0.0.4; charset=utf-8"
)
@app.before_request
def before_request():
"""Make sure we are connected to the database each request and look
up the current user so that we know he's there.
"""
request.start_time = datetime.now()
g.db = connect_db()
g.user = None
if "user_id" in session:
g.user = query_db(
"select * from user where user_id = ?",
[session["user_id"]],
one=True,
)
CPU_GAUGE.set(psutil.cpu_percent())
@app.after_request
def after_request(response):
"""Closes the database again at the end of the request."""
g.db.close()
REPONSE_COUNTER.inc()
t_elapsed_ms = (datetime.now() - request.start_time).total_seconds() * 1000
REQ_DURATION_SUMMARY.observe(t_elapsed_ms)
return responseglobal:
scrape_interval: 15s # By default, scrape targets every 15 seconds.
evaluation_interval: 15s # Evaluate rules every 15 seconds.
# Attach these extra labels to all timeseries collected by this Prometheus instance.
external_labels:
monitor: 'codelab-monitor'
rule_files:
- 'prometheus.rules.yml'
scrape_configs:
- job_name: 'prometheus'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
static_configs:
- targets: ['prometheus:9090']
- job_name: 'itu-minittwit-app'
# Override the global default and scrape targets from this job every 5 seconds.
scrape_interval: 5s
static_configs:
- targets: ['minitwit:5000']
labels:
group: 'production'Navigate your browser to http://localhost:9090/graph?g0.range_input=1h&g0.expr=minitwit_cpu_load_percent&g0.tab=0&g1.range_input=1h&g1.expr=minitwit_http_responses_total&g1.tab=0&g2.range_input=1h&g2.expr=minitwit_request_duration_milliseconds_bucket&g2.tab=0 to see some of your metrics through Prometheus inbuilt dashboard.
- Just because you can include everything does not mean you should!
- Keep them organized
- Try to "tell a story", i.e., you will likely have different dashboards for you and the operators
- Include more than infrastructure monitoring, remember 'Monitor close to the User' from the beginning of the session.
- See more here: https://www.metricly.com/devops-dashboard-best-practices/
- See https://grafana.com/dashboards
- https://codeascraft.com/2011/02/15/measure-anything-measure-everything/
Grafana dashboards support alerts. For active monitoring, you might want to setup some alarms and get notified when something goes wrong. You can get alerts either on the dashboard or -likely more suitable- via other channels such as: Mail, PagerDuty, Slack, Telegram
To configure the dashboard you have to use queries in PromQL, see more here: https://prometheus.io/docs/prometheus/latest/querying/basics/
- Grafana can connect to multiple backends
- When querying Prometheus you need to use the PromQL syntax
minitwit_cpu_load_percentminitwit_cpu_load_percent{group="production",instance="minitwit:5000",job="itu-minittwit-app"}rate(minitwit_cpu_load_percent[5m])sum(rate(minitwit_cpu_load_percent[5m])) by (job)

- To prepare for your project work, practice with the exercises
- Do the project work until the end of the week
- And prepare for the next session