Home
Status: In development, being tested at Janelia, and not ready for external use due to possible breaking changes.
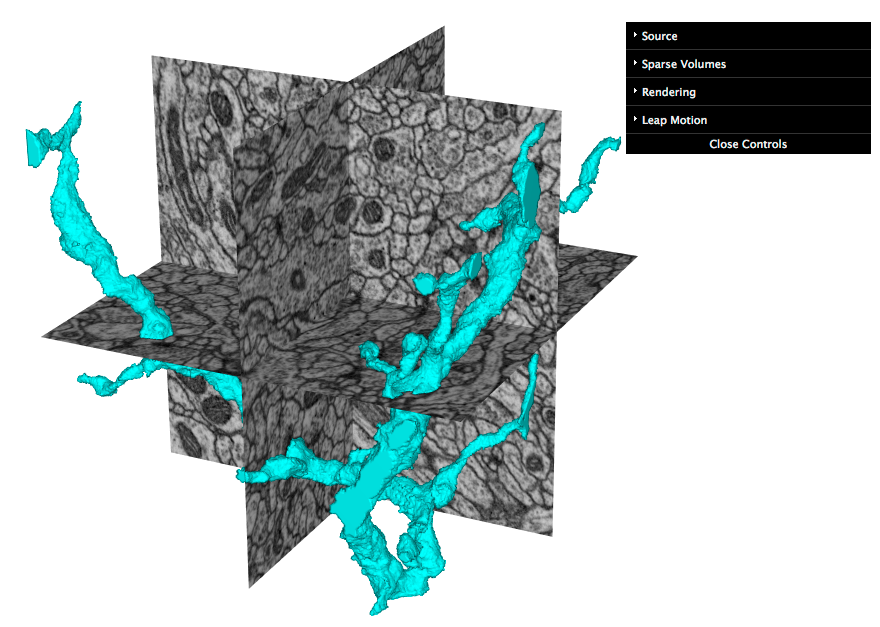
DVID is a distributed, versioned, image-oriented dataservice written to support Janelia Research Campus's brain imaging, analysis and visualization efforts.
DVID aspires to be a "github for large image-oriented data" because each DVID server can manage multiple repositories, each of which contains an image-oriented repo with related data like an image volume, labels, and skeletons. The goal is to provide scientists with a github-like web client + server that can push/pull data to a collaborator's DVID server.
Although DVID is easily extensible by adding custom data types, each of which fulfill a minimal interface (e.g., HTTP request handling), DVID's initial focus is on efficiently handling data essential for Janelia's connectomics research:
- image and 64-bit label 3d volumes
- 2d images in XY, XZ, YZ, and arbitrary orientation
- multiscale 2d images in XY, XZ, and YZ, similar to quadtrees
- low-latency sparse volumes corresponding to each unique label in a volume
- label graphs
- regions of interest represented via a coarse subdivision of space using block indices
- 2d and 3d image and label data using Google BrainMaps API
Each of the above is handled by built-in data types via a Level 2 REST HTTP API implemented by Go language packages within the datatype directory. When dealing with novel data, we typically use the generic keyvalue data type and store JSON-encoded or binary data until we understand the desired access patterns and API. When we outgrow the keyvalue type's GET, POST, and DELETE operations, we create a custom data type package with a specialized HTTP API.