深入浅出DOM基础——《DOM探索之基础详解篇》学习笔记 #9
Comments
|
提个小意见,作为读者看到这篇文章略长。可以TOC一个目录,脉路清晰点,更容易消化。 |
|
TOC是啥?只看到Segment有这个,github好像没看到自带的这个。@Expelliarmus923 |
|
Table of contents @jawil |
|
github有这个功能吗,应该说是markdown语法,好像文档没看到这个功能介绍。@Eamonnzhang |
|
可以在chrome商店安装个TOC插件,https://chrome.google.com/webstore/detail/smart-toc/lifgeihcfpkmmlfjbailfpfhbahhibba |

|
感谢推荐,太实用了@BBcaptain |
|
写的非常好,很受用 |
不可枚举属性不能被for in遍历吧?……例子貌似也没支持这个说法 |
const obj = { a: 1, b: 2, c: 3 };
Object.defineProperty(obj, "a", {
enumerable: false
});
for (let attr in obj) {
console.log(attr);
}不好意思,不可枚举属性不能被for in遍历,误导了,应该是'a' in obj是in检测对象属性会遍历对象自身的属性,以及原型属性,包括enumerable 为 false(不可枚举属性); |
|
博主,请教个问题,判断元素节点类型那一节,什么元素节点操作属性的时候用直接属性,什么时候用方法setAttribute? |
|
直接属性当然是直接挂在在元素节点上的属性,比如说 ele.textContent,input.vulue,而setAttribute是给元素节点加一个原来没有的属性,元素为了可拓展性,也允许加入自定义的属性。@yoky 举个例子吧,手和脚都是人自带的属性,但是我想飞,我可以去接(setAttribute)一双翅膀😂 |
|
那可以用setAttribute修改本身自带属性的值么? |
|
写个 demo 试一下不就知道了,这个很好实践的啊,而且印象深刻 @yoky |
|
确实确实。。比心 |
|
hello,针对9.1那块元素节点的判断,也可以用这段代码来判断,我觉得更方便点。 |
|
@sfsoul 不能过滤这种伪造的元素对象 |
|
@caihg ,感觉你这个例子就太偏激了。。。不过也的确过滤不了。不知道还有没有更好的办法呢 |
之前通过深入学习DOM的相关知识,看了慕课网DOM探索之基础详解篇这个视频(在最近看第三遍的时候,准备记录一点东西,算是对自己学习的一点总结),对DOM的理解又具体了一步,因为DOM本来就是一个抽象和概念性的东西,每深入一步了解,在脑中就会稍微具体一点,通过这次的对DOM的系统学习,对DOM有一个比较深刻的理解,明白了DOM在JavaScript这门语言中举足轻重的地位,了解了DOm的发展历史,也让我明白了存在浏览器浏览器兼容性的历史原因,对DOM的结构有了进一步的认知,对DOM的一些API也更加熟悉,对比较抽象和概念性的DOM认知稍微具体了一些。下面就是自己深入学习DOM这门课程整理的一些笔记,大部分来自学习中查阅的资料以及视频中老师讲的一些关键性知识点,当然也不可或缺的有自己的一些记录和理解。
原文收录在我的 GitHub博客 (https://github.com/jawil/blog) ,喜欢的可以关注最新动态,大家一起多交流学习,共同进步,以学习者的身份写博客,记录点滴。
文章稍长,本文只论述DOM基础概念,不涉及DOM的一些事件原理机制,页面元素的操作和常用API的讲解以及兼容性事项,所以概念性东西比较多,稍微有点抽象,其中有笔记来大部分来自老师的口述,还有一部分是查阅的文档,最后有一部分是自己的记录和理解。
学习视频地址:DOM探索之基础详解篇,老师讲的很好,有兴趣的可以结合视频学习一下,建议看完视频再看笔记,加深印象,你会受益匪浅。
1、什么是DOM?
W3C DOM由以下三部分组成:
DOM(文档对象模型)是针对xml经过扩展用于html的应用程序编程接口,我们又叫API。DOM把整个页面映射为一个多层的节点结构,html或xml页面中的每个组成部分都是某种类型的节点,这些节点又包含着不同类型的数据。
2、DOM的地位
3、DOM的发展-DOM0、DOM1、DOM2、DOM3的区别
3.1、DOM0
这实际上是未形成标准的试验性质的初级阶段的DOM,现在习惯上被称为DOM0,即:第0级DOM。由于DOM0在W3C进行标准备化之前出现,还处于未形成标准的初期阶段,这时Netscape和Microsoft各自推出自己的第四代浏览器,自此DOM遍开始出各种问题。
3.2、DOM0与DHTML
DHTML是Dynamic HTML(动态HTML)的简称。DHTML并不是一项新技术,而是将HTML、CSS、JavaScript技术组合的一种描述。即:
利用DHTML,看起来可以很容易的控制页面元素,并实现一此原本很复杂的效果(如:通过改变元素位置实现动画)。但事实并非如此,因为没有规范和标准,两种浏览器对相同功能的实现确完全不一样。为了保持程序的兼容性,程序员必须写一些探查代码以检测JavaScript是运行于哪种浏览器之下,并提供与之对应的脚本。JavaScript陷入了前所未有的混乱,DHTML也因此在人们心中留下了很差的印象。
3.3、DOM1的出现
DOM1级主要定义了HTML和XML文档的底层结构。在DOM1中,DOM由两个模块组成:DOM Core(DOM核心)和DOM HTML。其中,DOM Core规定了基于XML的文档结构标准,通过这个标准简化了对文档中任意部分的访问和操作。DOM HTML则在DOM核心的基础上加以扩展,添加了针对HTML的对象和方法,如:JavaScript中的Document对象.
3.4、DOM2
完整的DOM2标准(图片来自百度百科):
3.5、DOM3
4、认识DOM
先看一张w3school上面的一张图:
先来看看下面代码:
将HTML代码分解为DOM节点层次图:
HTML文档可以说由节点构成的集合,DOM节点有:
5、文档类型发展史
我们说DOM文档对象模型是从文档中抽象出来的,DOM操作的对象也是文档,因此我们有必要了解一下文档的类型。文档随着历史的发展演变为多种类型,如下:
5.1、GML
5.2、SGML
5.3、HTML
5.4、XML
5.5、XHTML
6、DOM节点类型
看下面这个例子:
以下引用均来自老师说的话,感觉每句话都很重要,所以就写下来了。
(1)Element(元素节点):
例子中的:
html、heade、meta、title、body、div、ul、li、script都属于Element(元素节点);(2)Attr(属性节点):
例子中的:
lang、charset、id、class都属于Attr(属性节点);(3)Text(文本节点):
例子中的:
DocumentFragment文档片段节点、test1、test2、元素节点之后的空白区域都属于Text(文本节点);(4)Comment(注释节点):
例子中的:
<!-- tip区域 -->都属于Comment(注释节点);(5)Document(文档节点) :
例子中的:
<!DOCTYPE html>、html作为Document(文档节点)的子节点出现;(6)DocumentType(文档类型节点):
例子中的:
<!DOCTYPE html>就属于DocumentType(文档类型节点);(7)DocumentFragment(文档片段节点):
例子中的:
var frag = document.createDocumentFragment();就属于DocumentFragment(文档片段节点);7、DOM的nodeType、nodeName、nodeValue
7.1 nodeType
7.2 nodeName和nodeValue
先看示例代码:
根据实验,得出以下汇总表格:
8、domReady
还记得刚开始学习JavaScript时候,经常会犯这样的错误:
最后发现结果并不是我们想要的,文字并没有变成红色,我想最先入门学习JavaScript操作DOM时候多多少少会遇到这种困惑和错误,其实出现这种问题的原因就是我们没有区分HTML标签和DOM节点的区别的缘故了,由这个问题就引出下面要说的domReady和浏览器渲染解析原理了。
8.1、什么是domReady?
8.2、那么浏览器是如何将html标签解析变成DOM节点的呢?
8.3、浏览器渲染引擎的基本渲染流程
浏览器渲染要做的事就是把CSS,HTML,图片等静态资源展示到用户眼前。
上图就是html渲染的基本过程,但这并不包含解析过程中浏览器加载外部资源,比如图片、脚本、iframe等的一些过程。说白了,上面的4步仅仅是html结构的渲染过程。而外部资源的加载在html结构的渲染过程中是贯彻始终的,即便绘制DOM节点已经完成,而外部资源仍然可能正在加载或者尚未加载。
8.4、Webkit主要渲染流程
Firefox浏览器Gecko渲染流程跟Webkit内核渲染类似,大同小异,WebKit 和 Gecko 使用的术语略有不同,但整体流程是基本相同的。这里以Webkit内核作为例子来说明浏览器渲染的主要流程。
浏览器的渲染原理并非三言两语,几个图就能说明白的,上图说的只是介绍一个大环节的过程和步骤,这里抛砖引玉象征性说个大概,更多关于浏览器内部工作原理的文章,请阅读:浏览器的工作原理:新式网络浏览器幕后揭秘
8.5、domReady的实现策略
你肯定想到了jquery中的$(document).ready(function(){})方法了,其实jquery中的domReady应该和window.onload的实现原理是大同小异的。为了解决window.onload的短板,w3c 新增了一个 DOMContentLoaded 事件。
这里提到了DOMContentLoaded事件,这里由于篇幅有限,就不多做介绍,这里面也有很多细节可以学习,有兴趣的童鞋,可以看看我之前收藏的两篇文章:
你不知道的 DOMContentLoaded
浅谈DOMContentLoaded事件及其封装方法
学习就是一个无底洞,因为深不可测,才让人不断探索。
参考jquery中domReady的实现原理,来看一下javascript中domReady的实现策略。
在页面的DOM树创建完成后(也就是HTML解析第一步完成)即触发,而无需等待其他资源的加载。即domReady实现策略:
JavaScript实现domReady,【domReady.js】
在页面中引入donReady.js文件,引用myReady(回调函数)方法即可。
感兴趣的童鞋可以看看各个主流框架domReady的实现:点击我查看
8.6、一个小栗子看二者差异性
下面通过一个案例,来比较domReady与window.onload实现的不同,很明显,onload事件是要在所有请求都完成之后才执行,而domReady利用hack技术,在加载完dom树之后就能执行,所以domReady比onload执行时间更早,建议采用domReady。
执行结果对比,发现DomReady比onload快乐2秒多。
9、元素节点的判断
为什么要判断元素的节点?
设计元素类型的判定,这里给出有4个方法:
9.1、元素节点的判定:isElement
注意代码中的!!用法:!!一般用来将后面的表达式转换为布尔型的数据(boolean).
因为javascript是弱类型的语言(变量没有固定的数据类型)所以有时需要强制转换为相应的类型,关于JavaScript的隐式转换,可以看看之前我写的一篇博客,这篇文章几乎分析到了所有的转换规则,感兴趣的童鞋可以点击查阅,学习了解一下。
从++[[]][+[]]+[+[]]==10?深入浅出弱类型JS的隐式转换
注意:上面的代码定义了一个变量a,将它的nodeType的值设为1,由于元素节点的节点类型的数值常量为1,所以这里在打印的的时候,会将a认为是元素节点,所以打印true。这种结果明显不是我们想要的,即使这种情况很少出现。下面给出解决方案:
这样,在判断a是否是元素节点时,结果就是false了。
更多关于元素节点的判断请参考:How do you check if a JavaScript Object is a DOM Object?
9.2、HTML文档元素节点的判定和XML文档元素节点的判定:isHTML and isXML
9.2.1、Sizzle, jQuery自带的选择器引擎,判断是否是XML文档
浏览器随便找个HTML页面验证一下:
9.2.1、mootools的slick选择器引擎的源码,判断是否是XML文档
不过,这些方法都只是规范,javascript对象是可以随意添加的,属性法很容易被攻破,最好是使用功能法。功能法的实现代码如下:
我们知道,无论是HTML文档,还是XML文档都支持createELement()方法,我们判定创建的元素的nodeName是区分大小写的还是不区分大小写的,我们就知道是XML还是HTML文档,这个方法是目前给出的最严谨的函数了。
判断是不是HTML文档的方法如下:
有了以上判断XML和HTML文档的方法,我们就可以实现一个元素节点属于HTML还是XML文档的方法了,实现代码如下:
9.3、判断节点的包含关系
DOM可以将任何HTML描绘成一个由多层节点构成的结构。节点分为12种不同类型,每种类型分别表示文档中不同的信息及标记。每个节点都拥有各自的特点、数据和方法,也与其他节点存在某种关系。节点之间的关系构成了层次,而所有页面标记则表现为一个以特定节点为根节点的树形结构。DOM间的节点关系大致如下。
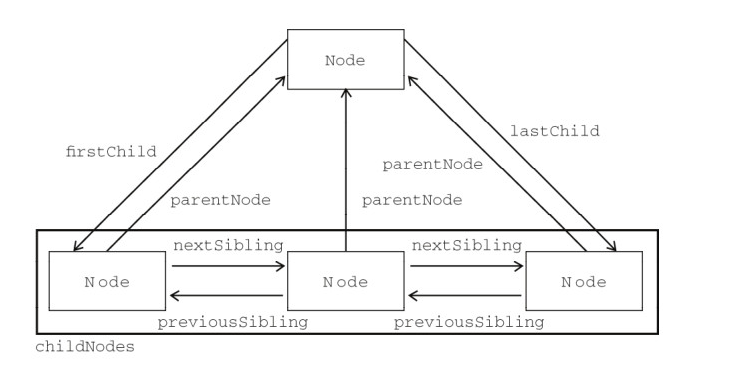
节点关系不仅仅指元素节点的关系,document文档节点也包含在内。在最新的浏览器中,所有的节点都已经装备了contains()方法,
元素之间的包含关系,用自带的contains方法,只有两个都是元素节点,才能兼容各个浏览器,否则ie浏览器有的版本是不支持的,可以采用hack技术,自己写一个contains方法去兼容。
元素之间的包含关系:contains()方法.
兼容各浏览器的contains()方法
10、DOM节点继承层次与嵌套规则
10.1、DOM节点继承层次
10.1.1、创建一个元素节点(Element)的过程
使用document.createElement("p")创建p元素,其实document.createElement("p")是HTMLParagraphElement的一个实例,而HTMLParagraphElement的父类是HTMLElement,HTMLElement的父类是Element,Element的父类是Node,Node的父类是EventTarget,EventTarget的父类是Function,Function的父类是Object。
创建一个p元素一共溯寻了7层原型链:
下面我们来分析一下创建一个元素所继承的属性分别是啥。
1.document.createElement("p")
document.createElement("p")首先就是一个实例对象,它是由构造函数HTMLParagraphElement产生的,你可以这么看这个问题:
由以上继承关系可以看出来:
document.createElement("p").constructor===HTMLParagraphElement document.createElement("p").__proto__===HTMLParagraphElement.prototype对实例对象,构造函数,以及JavaScript原型链和继承不太熟悉的童鞋,该补习一下基础看看了。
我们先来看看document.createElement("p")自身有哪些属性,遍历对象属性方法一般有三种:
先来讲一讲遍历对象属性三种方法的差异性,当做补充复习。
遍历数组属性目前我知道的有:
for-in循环、Object.keys()和Object.getOwnPropertyNames(),那么三种到底有啥区别呢?Object.defineProperty顾名思义,就是用来定义对象属性的,vue.js的双向数据绑定主要在getter和setter函数里面插入一些处理方法,当对象被读写的时候处理方法就会被执行了。 关于这些方法和属性的更具体解释,可以看MDN上的解释(戳我);简单看一个小demo例子加深理解,对于
Object.defineProperty属性不太明白,可以看看上面介绍的文档学习补充一下.有了上面的知识作为扩充,我们就可以清晰明了的知道,创建元素P标签每一步都继承了哪些属性,继承对象自身有哪些属性,由于篇幅有限,大家可以自行子在浏览器测试,看看这些对象的一些属性和方法,便于我们理解。
例如我们想看:HTMLElement对象有哪些自身属性,我们可以这么查看:
我们想看:HTMLElement的原型对象有哪些自身属性,我们可以这么查看:
HTMLElement的原型对象有哪些自身属性,根据原型链,我们也可以这么查看:
因为:
document.createElement("p").__proto__.__proto__===HTMLElement.prototype10.1.2、创建一个文本节点(Text)的过程
使用document.createTextNode("xxx")创建文本节点,其实document.createTextNode("xxx")是Text的一个实例,而Text的父类是CharactorData,CharactorData的父类是Node,Node的父类是EventTarget,EventTarget的父类是Function,Function的父类是Object。
创建一个文本节点一共溯寻了6层原型链。
因此,所有节点的继承层次都不简单,但相比较而言,元素节点是更可怕的。从HTML1升级到HTML3.2,再升级到HTML4.1,再到HTML5,除了不断地增加新类型、新的嵌套规则以外,每个元素也不断的添加新属性。
下面看一个例子:创建一个p元素,打印它第一层原型的固有的属性的名字,通过Object的getOwnPropertyNames()获取当前元素的一些属性,这些属性都是他的原始属性,不包含用户自定义的属性。
10.1.3、空的div元素的自有属性
下面看一个空的div元素,并且没有插入到DOM里边,看它有多少自有属性(不包括原型链继承来的属性)
在新的HTML规范中,许多元素的固有属性(比如value)都放到了原型链当中,数量就更加庞大了。因此,未来的发展方向是尽量使用现成的框架来实现,比如MVVM框架,将所有的DOM操作都转交给框架内部做精细处理,这些实现方案当然就包括了虚拟DOM的技术了。但是在使用MVVM框架之前,掌握底层知识是非常重要的,明白为什么这样做,为什么不这样做的目的。这也是为什么要理解DOM节点继承层次的目的。
10.2、HTML嵌套规则
块状元素:一般是其他元素的容器,可容纳内联元素和其他块状元素,块状元素排斥其他元素与其位于同一行,宽度(width)高度(height)起作用。常见块状元素为div和p
内联元素:内联元素只能容纳文本或者其他内联元素,它允许其他内联元素与其位于同一行,但宽度(width)高度(height)不起作用。常见内联元素为a.
块状元素与内联元素嵌套规则:
(1).块元素可以包含内联元素或某些块元素,但内联元素却不能包含块元素,它只能包含其他的内联元素
(2).块级元素不能放在
里面
(3).有几个特殊的块级元素提倡只能包含内联元素,不能再包含块级元素,这几个特殊的标签是:
(4).li标签可以包含div标签
(5).块级元素与块级元素并列,内联元素与内联元素并列
The text was updated successfully, but these errors were encountered: