graph LR
dispatch-->initialize_request
initialize_request-->get_parsers
get_parsers-->request.data
request.data-->判断是否设置了_full_data值
判断是否设置了_full_data值-->None
判断是否设置了_full_data值-->True
None-->_load_data_and_files
_load_data_and_files-->self._parse
self._parse-->select_parser选择解析器
select_parser选择解析器-->返回数据,文件
返回数据,文件-->self._full_data

一、在django中客户端发来的请求会执行视图类的as_view方法,而as_view方法会执行dispatch方法,然后进行反射执行相应的方法(get、post等)
反射:通过字符串的形式操作对象相关的属性
https://www.chenshaowen.com/blog/reflection-of-python.html
1. getattr(object,‘name‘,‘default’)
如果存在name的属性方法,则返回name的属性方法,否则返回default的属性方法。
2. hasattr(object, ’name‘)
判断对象object是否包含名为name的属性方法,存在则返回True,否则返回False。hasattr是通过调用getattr(ojbect, ’name‘)是否抛出异常来实现)。
3. setattr(object,‘name’,’default‘)
设置对象object的name属性值为default,如果没有name属性,那么创建一个新的属性。
4. delattr(object,’name’)
删除对象object的name属性值。
举个栗子
import requests
class Http(object):
def get(self,url):
res = requests.get(url)
response = res.text
return response
def post(self,url):
res = requests.post(url)
response = res.text
return response
# 使用反射后
url = "https://www.jianshu.com/u/14140bf8f6c7"
method = input("请求方法>>>:")
h = Http()
if hasattr(h,method):
func = getattr(h,method)
res = func(url)
print(res)
else:
print("你的请求方式有误...")
https://www.chenshaowen.com/blog/reflection-of-python.html
二、drf中的APIView中只要重写as_view()方法
重写dispatch方法,就能加入相对应的功能,我们来看下drf中APIView中as_view()方法# 类方法
@classmethod
def as_view(cls, **initkwargs):
"""
Store the original class on the view function.
This allows us to discover information about the view when we do URL
reverse lookups. Used for breadcrumb generation.
"""
# 检查类中定义的queryset是否是这个models.query.QuerySet类型,必行抛异常
if isinstance(getattr(cls, 'queryset', None), models.query.QuerySet):
def force_evaluation():
raise RuntimeError(
'Do not evaluate the `.queryset` attribute directly, '
'as the result will be cached and reused between requests. '
'Use `.all()` or call `.get_queryset()` instead.'
)
cls.queryset._fetch_all = force_evaluation
# 执行父类的as_view方法
view = super().as_view(**initkwargs)
view.cls = cls
view.initkwargs = initkwargs
# Note: session based authentication is explicitly CSRF validated,
# all other authentication is CSRF exempt.
# 返回view,由于是前后端分离就取消csrf认证
return csrf_exempt(view)小结
这个方法是APIView里面的,我们可以看到他执行了父类的as_view方法,
也就相当于初始化父类,我们接下来看下最基础django中父类View中的as_view方法是怎么样的class View:
# 类方法
@classonlymethod
def as_view(cls, **initkwargs):
"""Main entry point for a request-response process."""
for key in initkwargs:
if key in cls.http_method_names:
raise TypeError("You tried to pass in the %s method name as a "
"keyword argument to %s(). Don't do that."
% (key, cls.__name__))
if not hasattr(cls, key):
raise TypeError("%s() received an invalid keyword %r. as_view "
"only accepts arguments that are already "
"attributes of the class." % (cls.__name__, key))
def view(request, *args, **kwargs):
self = cls(**initkwargs)
if hasattr(self, 'get') and not hasattr(self, 'head'):
self.head = self.get
self.request = request
self.args = args
self.kwargs = kwargs
return self.dispatch(request, *args, **kwargs)
view.view_class = cls
view.view_initkwargs = initkwargs
# take name and docstring from class
update_wrapper(view, cls, updated=())
# and possible attributes set by decorators
# like csrf_exempt from dispatch
update_wrapper(view, cls.dispatch, assigned=())
return view小结
父类绕来绕去还是去执行self.dispatch了,下面我们来总结下上面的执行过程
1、View 的执行顺序:
as_view()方法-----》返回view函数名称(一旦有请求来了就必须要执行as_view方法,然后再执行dispatch方法)
2、APIView 的执行顺序
执行父类as_view方法---》执行dispath方法(APIView重写dispath方法)
==问==:这个看来没有封装什么,只是检查了是否queryset值的类型,然后由于前后端分取消csrf认证
==答==:他执行了
view = super().as_view(**initkwargs)
就一定会执行dispatch()方法
==疑问==:会不会重写了dispatch()方法呢?,搜索一下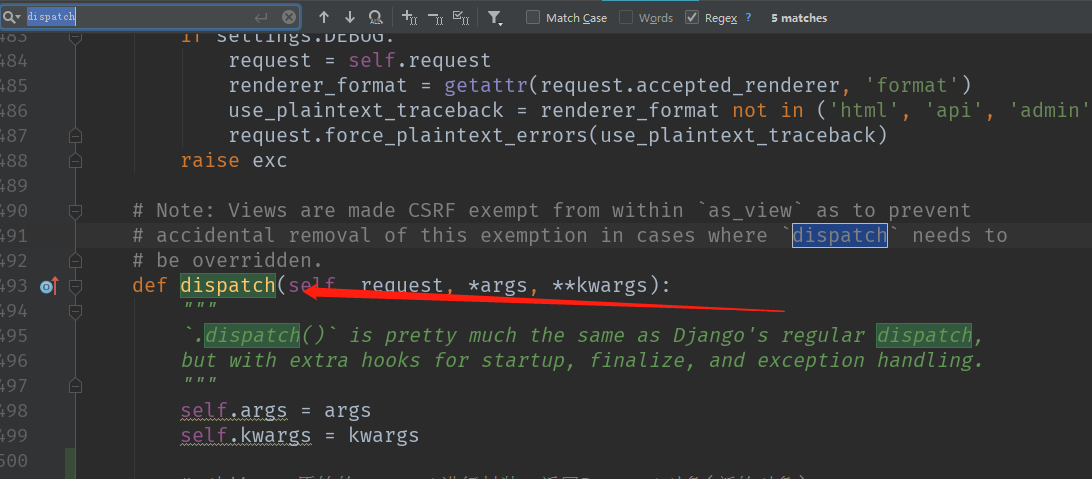
def dispatch(self, request, *args, **kwargs):
"""
`.dispatch()` is pretty much the same as Django's regular dispatch,
but with extra hooks for startup, finalize, and exception handling.
"""
self.args = args
self.kwargs = kwargs
# 对django原始的request进行封装,返回Request对象(新的对象)。
request = self.initialize_request(request, *args, **kwargs)
self.request = request
self.headers = self.default_response_headers # deprecate?
try:
# 这里的request是新封装的request,然后进一步封装,加入新的一些功能,比如认证,限速,权限
self.initial(request, *args, **kwargs)
# Get the appropriate handler method
if request.method.lower() in self.http_method_names:
handler = getattr(self, request.method.lower(),
self.http_method_not_allowed)
else:
handler = self.http_method_not_allowed
response = handler(request, *args, **kwargs)
except Exception as exc:
response = self.handle_exception(exc)
self.response = self.finalize_response(request, response, *args, **kwargs)
return self.response小结
这里我们可以知道APIView 重写了父类View的dispatch
1. 从这里我们可以知道
2. 对django原始的request进行封装,返回Request对象(新的对象)。
request = self.initialize_request(request, *args, **kwargs)
我们接下来看看他在原有的request基础上封装了什么
def initialize_request(self, request, *args, **kwargs):
"""
Returns the initial request object.
"""
parser_context = self.get_parser_context(request)
# 这里将原来的request封装进来,加入新的功能
return Request(
request,
parsers=self.get_parsers(),
# 加入认证
authenticators=self.get_authenticators(),
negotiator=self.get_content_negotiator(),
parser_context=parser_context
)这里我们可以知道返回了一个新的Request,到低封装了什么呢?
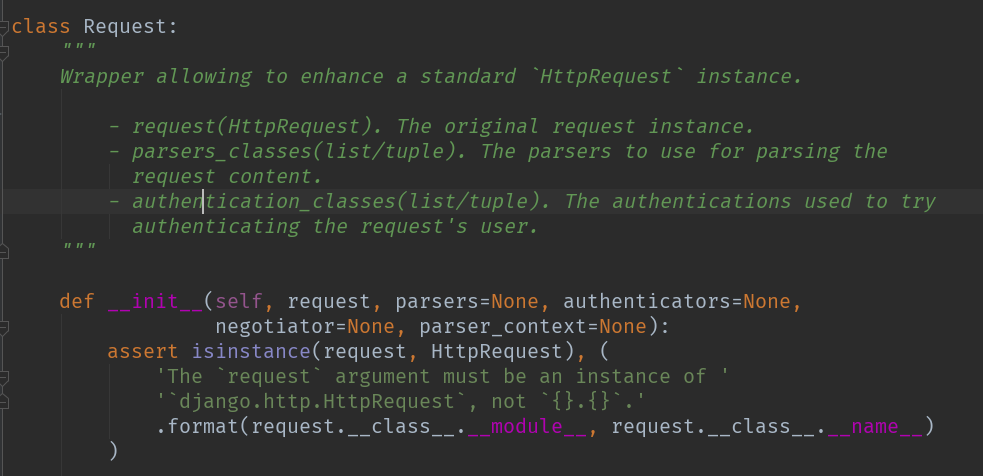
新的Request他封装了
- 请求(HttpRequest)。原始请求实例
- 解析器类(列表/元组)。用于分析
- 请求内容。
- 身份验证类(列表/元组)。用于尝试的身份验证
这里我们由于是分析他的认证就不对他封装的其他进行说明,我们还是回到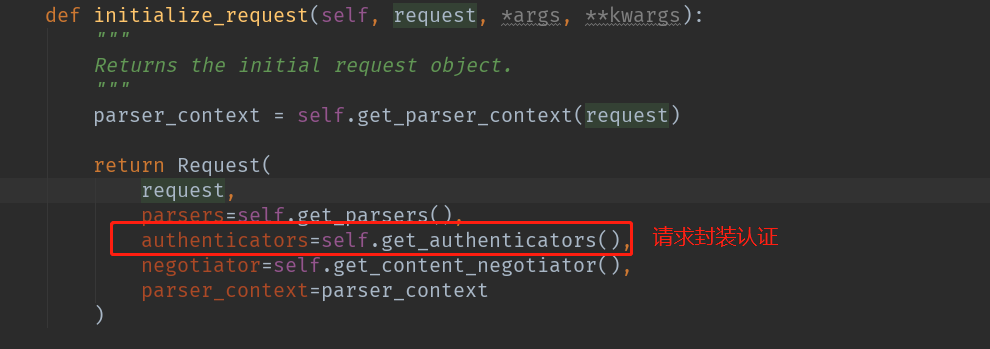
def get_parsers(self):
"""
Instantiates and returns the list of parsers that this view can use.
"""
# 列表生成式获取解析器实例
return [parser() for parser in self.parser_classes]小结
这里用列表生成式获取解析器实例,然后就是看是否我们在类中是否定义了解析类
1. 设置了就执行设置的解析类
2. 没有设置则解析获得下面默认解析类parser_classes = api_settings.DEFAULT_PARSER_CLASSES@property
def data(self):
if not _hasattr(self, '_full_data'):
# 执行_load_data_and_files() ,获取请求体数据获取文件数据
self._load_data_and_files()
return self._full_data
小结
解析类最终作用的是request请求的数据,所以我们在Request类中查看下下data属性是如何获得
的,上面正是data数据属性,如果Ruquest类中为设置**_full_data**属性,
就返回_full_data的值,如果没设置那么就执行**self._load_data_and_files()**,我们跟踪看下
def _load_data_and_files(self):
"""
Parses the request content into `self.data`.
"""
# 如果设置了request._data="xxx",且值为空的话
if not _hasattr(self, '_data'):
# 执行self._parse(),获取解析器,并对content_type进行解析,选择解析器,返回元组
# (数据,文件)
self._data, self._files = self._parse()
# 判断文件流数据,存在则加入到self._full_data(也就是我们的request.data)中
if self._files:
# 浅拷贝赋值
self._full_data = self._data.copy()
self._full_data.update(self._files)
else:
# 不存在将无文件流的解析完成的数据赋值到self._full_data(request.data)
self._full_data = self._data
# if a form media type, copy data & files refs to the underlying
# http request so that closable objects are handled appropriately.
if is_form_media_type(self.content_type):
self._request._post = self.POST
self._request._files = self.FILES小结
# 如果设置了request._data="xxx",且值为空的话,或未设置_data属性的话就调取解析器
# self._data, self._files = self._parse()
# 执行self_parse(),获取解析器,并对content_type进行解析,选择解析器,返回数据def _parse(self):
"""
Parse the request content, returning a two-tuple of (data, files)
May raise an `UnsupportedMediaType`, or `ParseError` exception.
解析请求内容,返货两个元组(数据、文件)
可能引发"UnsupportedMediaType"或者“ParseError”异常
"""
# 获取请求体中的content-type
media_type = self.content_type
try:
# 如果是文件数据,则获取文件流数据
stream = self.stream
except RawPostDataException:
if not hasattr(self._request, '_post'):
raise
# If request.POST has been accessed in middleware, and a method='POST'
# request was made with 'multipart/form-data', then the request stream
# will already have been exhausted.
# 如果是form表单
if self._supports_form_parsing():
# 处理文件类型数据
return (self._request.POST, self._request.FILES)
stream = None
# 如果文件流为空,和media_type也为空
if stream is None or media_type is None:
if media_type and is_form_media_type(media_type):
empty_data = QueryDict('', encoding=self._request._encoding)
else:
empty_data = {}
empty_files = MultiValueDict()
return (empty_data, empty_files)
# 选择解析器
parser = self.negotiator.select_parser(self, self.parsers)
# 没有解析器则抛出异常
if not parser:
raise exceptions.UnsupportedMediaType(media_type)
try:
# 执行解析器的parse方法(从这里可以看出每个解析器都必须有该方法),对请求数据进行解析
parsed = parser.parse(stream, media_type, self.parser_context)
except Exception:
# If we get an exception during parsing, fill in empty data and
# re-raise. Ensures we don't simply repeat the error when
# attempting to render the browsable renderer response, or when
# logging the request or similar.
self._data = QueryDict('', encoding=self._request._encoding)
self._files = MultiValueDict()
self._full_data = self._data
raise
# Parser classes may return the raw data, or a
# DataAndFiles object. Unpack the result as required.
try:
# 返回解析结果, 元组,解析后的数据parsed.data(在load_data_and_files中
# 使用self._data和self._files进行接受)
# 文件数据咋parsed.files中
return (parsed.data, parsed.files)
except AttributeError:
empty_files = MultiValueDict()
return (parsed, empty_files)小结
这里根据请求content_type作为判断,确定到底是表单、json还是其他数据类型
中间还是先判断了是否是文件流类型
parser = self.negotiator.select_parser(self, self.parsers)
选择解析器,最后返回元祖(数据,文件)我们看下怎么获取的。self.negotiator 是在新的封装在request里面的属性,他有select_parser这个方法,
接收self.parsers参数,这个参数就是所有解析器类的实例列表。
## 解释:有很多解析类,但不能所有解析类都去解析数据吧。我们要有一个东西,自动判断去拿一个解析器去解析数据-
选择分析器
-
给定解析器列表和媒体类型,返回处理传入请求的分析器。

"""
Content negotiation deals with selecting an appropriate renderer given the
incoming request. Typically this will be based on the request's Accept header.
"""
from django.http import Http404
from rest_framework import HTTP_HEADER_ENCODING, exceptions
from rest_framework.settings import api_settings
from rest_framework.utils.mediatypes import (
_MediaType, media_type_matches, order_by_precedence
)
class BaseContentNegotiation:
def select_parser(self, request, parsers):
raise NotImplementedError('.select_parser() must be implemented')
def select_renderer(self, request, renderers, format_suffix=None):
raise NotImplementedError('.select_renderer() must be implemented')
class DefaultContentNegotiation(BaseContentNegotiation):
settings = api_settings
def select_parser(self, request, parsers):
"""
Given a list of parsers and a media type, return the appropriate
parser to handle the incoming request.
"""
for parser in parsers:
if media_type_matches(parser.media_type, request.content_type):
return parser
return None
def select_renderer(self, request, renderers, format_suffix=None):
"""
Given a request and a list of renderers, return a two-tuple of:
(renderer, media type).
"""
# Allow URL style format override. eg. "?format=json
format_query_param = self.settings.URL_FORMAT_OVERRIDE
format = format_suffix or request.query_params.get(format_query_param)
if format:
renderers = self.filter_renderers(renderers, format)
accepts = self.get_accept_list(request)
# Check the acceptable media types against each renderer,
# attempting more specific media types first
# NB. The inner loop here isn't as bad as it first looks :)
# Worst case is we're looping over len(accept_list) * len(self.renderers)
for media_type_set in order_by_precedence(accepts):
for renderer in renderers:
for media_type in media_type_set:
if media_type_matches(renderer.media_type, media_type):
# Return the most specific media type as accepted.
media_type_wrapper = _MediaType(media_type)
if (
_MediaType(renderer.media_type).precedence >
media_type_wrapper.precedence
):
# Eg client requests '*/*'
# Accepted media type is 'application/json'
full_media_type = ';'.join(
(renderer.media_type,) +
tuple('{}={}'.format(
key, value.decode(HTTP_HEADER_ENCODING))
for key, value in media_type_wrapper.params.items()))
return renderer, full_media_type
else:
# Eg client requests 'application/json; indent=8'
# Accepted media type is 'application/json; indent=8'
return renderer, media_type
raise exceptions.NotAcceptable(available_renderers=renderers)
def filter_renderers(self, renderers, format):
"""
If there is a '.json' style format suffix, filter the renderers
so that we only negotiation against those that accept that format.
"""
renderers = [renderer for renderer in renderers
if renderer.format == format]
if not renderers:
raise Http404
return renderers
def get_accept_list(self, request):
"""
Given the incoming request, return a tokenized list of media
type strings.
"""
header = request.META.get('HTTP_ACCEPT', '*/*')
return [token.strip() for token in header.split(',')]小结
我们可以看到这个最后是返回:
return parser,返回单个解析器类的实例- 解析器基类
- 必须要执行parse方法,返回解析内容
class BaseParser:
"""
All parsers should extend `BaseParser`, specifying a `media_type`
attribute, and overriding the `.parse()` method.
"""
# 解析的Content-type类型
media_type = None
def parse(self, stream, media_type=None, parser_context=None):
"""
Given a stream to read from, return the parsed representation.
Should return parsed data, or a `DataAndFiles` object consisting of the
parsed data and files.
"""
raise NotImplementedError(".parse() must be overridden.")
- json解析器
- 本质是使用json类进行解析
class JSONParser(BaseParser):
"""
Parses JSON-serialized data.
"""
# 解析的Content-type类型
media_type = 'application/json'
renderer_class = renderers.JSONRenderer
strict = api_settings.STRICT_JSON
# 该方法用于解析请求体
def parse(self, stream, media_type=None, parser_context=None):
"""
Parses the incoming bytestream as JSON and returns the resulting data.
"""
parser_context = parser_context or {}
encoding = parser_context.get('encoding', settings.DEFAULT_CHARSET)
try:
decoded_stream = codecs.getreader(encoding)(stream)
parse_constant = json.strict_constant if self.strict else None
# 本质使用json类进行解析
return json.load(decoded_stream, parse_constant=parse_constant)
except ValueError as exc:
raise ParseError('JSON parse error - %s' % str(exc))
- form 表单解析
class FormParser(BaseParser):
"""
Parser for form data.
"""
# form表单解析
media_type = 'application/x-www-form-urlencoded'
def parse(self, stream, media_type=None, parser_context=None):
"""
Parses the incoming bytestream as a URL encoded form,
and returns the resulting QueryDict.
"""
parser_context = parser_context or {}
encoding = parser_context.get('encoding', settings.DEFAULT_CHARSET)
return QueryDict(stream.read(), encoding=encoding)
- 文件上传解析
class FileUploadParser(BaseParser):
"""
Parser for file upload data.
"""
# 文件上传解析
media_type = '*/*'
errors = {
'unhandled': 'FileUpload parse error - none of upload handlers can handle the stream',
'no_filename': 'Missing filename. Request should include a Content-Disposition header with a filename parameter.',
}
def parse(self, stream, media_type=None, parser_context=None):
"""
Treats the incoming bytestream as a raw file upload and returns
a `DataAndFiles` object.
`.data` will be None (we expect request body to be a file content).
`.files` will be a `QueryDict` containing one 'file' element.
"""
parser_context = parser_context or {}
request = parser_context['request']
encoding = parser_context.get('encoding', settings.DEFAULT_CHARSET)
meta = request.META
upload_handlers = request.upload_handlers
filename = self.get_filename(stream, media_type, parser_context)
if not filename:
raise ParseError(self.errors['no_filename'])
# Note that this code is extracted from Django's handling of
# file uploads in MultiPartParser.
content_type = meta.get('HTTP_CONTENT_TYPE',
meta.get('CONTENT_TYPE', ''))
try:
content_length = int(meta.get('HTTP_CONTENT_LENGTH',
meta.get('CONTENT_LENGTH', 0)))
except (ValueError, TypeError):
content_length = None
# See if the handler will want to take care of the parsing.
for handler in upload_handlers:
result = handler.handle_raw_input(stream,
meta,
content_length,
None,
encoding)
if result is not None:
return DataAndFiles({}, {'file': result[1]})
# This is the standard case.
possible_sizes = [x.chunk_size for x in upload_handlers if x.chunk_size]
chunk_size = min([2 ** 31 - 4] + possible_sizes)
chunks = ChunkIter(stream, chunk_size)
counters = [0] * len(upload_handlers)
for index, handler in enumerate(upload_handlers):
try:
handler.new_file(None, filename, content_type,
content_length, encoding)
except StopFutureHandlers:
upload_handlers = upload_handlers[:index + 1]
break
for chunk in chunks:
for index, handler in enumerate(upload_handlers):
chunk_length = len(chunk)
chunk = handler.receive_data_chunk(chunk, counters[index])
counters[index] += chunk_length
if chunk is None:
break
for index, handler in enumerate(upload_handlers):
file_obj = handler.file_complete(counters[index])
if file_obj is not None:
return DataAndFiles({}, {'file': file_obj})
raise ParseError(self.errors['unhandled'])
def get_filename(self, stream, media_type, parser_context):
"""
Detects the uploaded file name. First searches a 'filename' url kwarg.
Then tries to parse Content-Disposition header.
"""
try:
return parser_context['kwargs']['filename']
except KeyError:
pass
try:
meta = parser_context['request'].META
disposition = parse_header(meta['HTTP_CONTENT_DISPOSITION'].encode())
filename_parm = disposition[1]
if 'filename*' in filename_parm:
return self.get_encoded_filename(filename_parm)
return force_str(filename_parm['filename'])
except (AttributeError, KeyError, ValueError):
pass
def get_encoded_filename(self, filename_parm):
"""
Handle encoded filenames per RFC6266. See also:
https://tools.ietf.org/html/rfc2231#section-4
"""
encoded_filename = force_str(filename_parm['filename*'])
try:
charset, lang, filename = encoded_filename.split('\'', 2)
filename = parse.unquote(filename)
except (ValueError, LookupError):
filename = force_str(filename_parm['filename'])
return filename
#全局使用
REST_FRAMEWORK = {
#解析器
"DEFAULT_PARSER_CLASSES":["rest_framework.parsers.JSONParser","rest_framework.parsers.FormParser"]
}
#单一视图使用
parser_classes = [JSONParser,FormParser]
解析器是按请求头Content-Type来实现的,不同的类型选择不同的解析器