Source: Book-Mathematical-Foundation-of-Reinforcement-Learning@github
Begin to read the book.
- Basic concepts of reinforcement learning
-
State
$$\mathcal{S}$$ -
Action
$$\mathcal{A}$$ - State transition $$ p(s_k|s_i, a_j) $$
- Policy $$ \pi(s_j|a_i) $$
- Reward $$ p(r=R|s_i,a_j) $$
-
Return
- return is the sum of reward along a trajectory.
-
MDPs=Markov decision processes
- Once the policy in an MDP is fixed, the MDP degenerates into an MP (Markov process).
-
State
Paper: HiDiffusion: Unlocking Higher-Resolution Creativity and Efficiency in Pretrained Diffusion Models
Project page: https://hidiffusion.github.io/
Github: https://github.com/megvii-research/HiDiffusion
- RAU: Resolution-Aware U-Net
- RAD: Resolution-Aware Downsampler
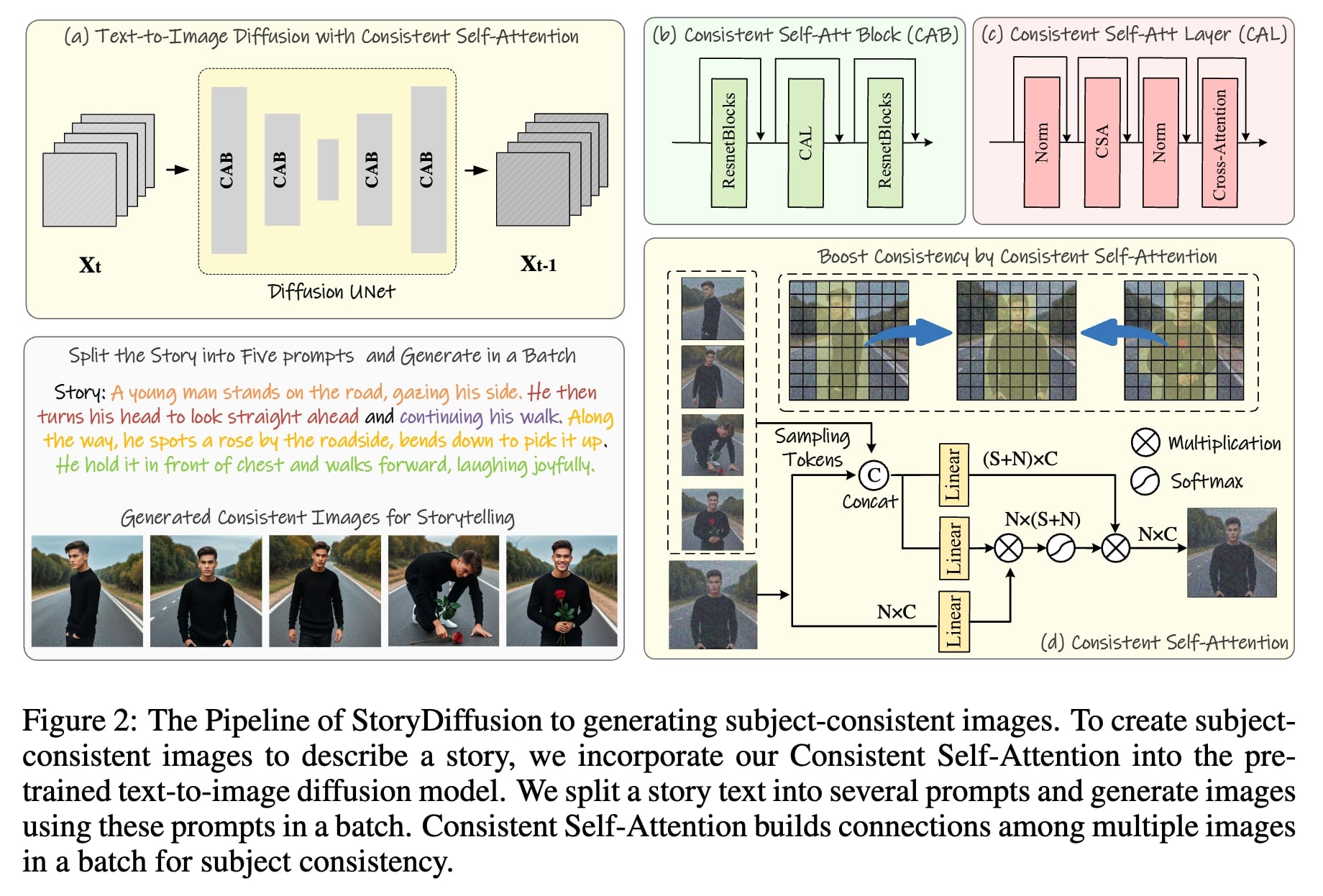
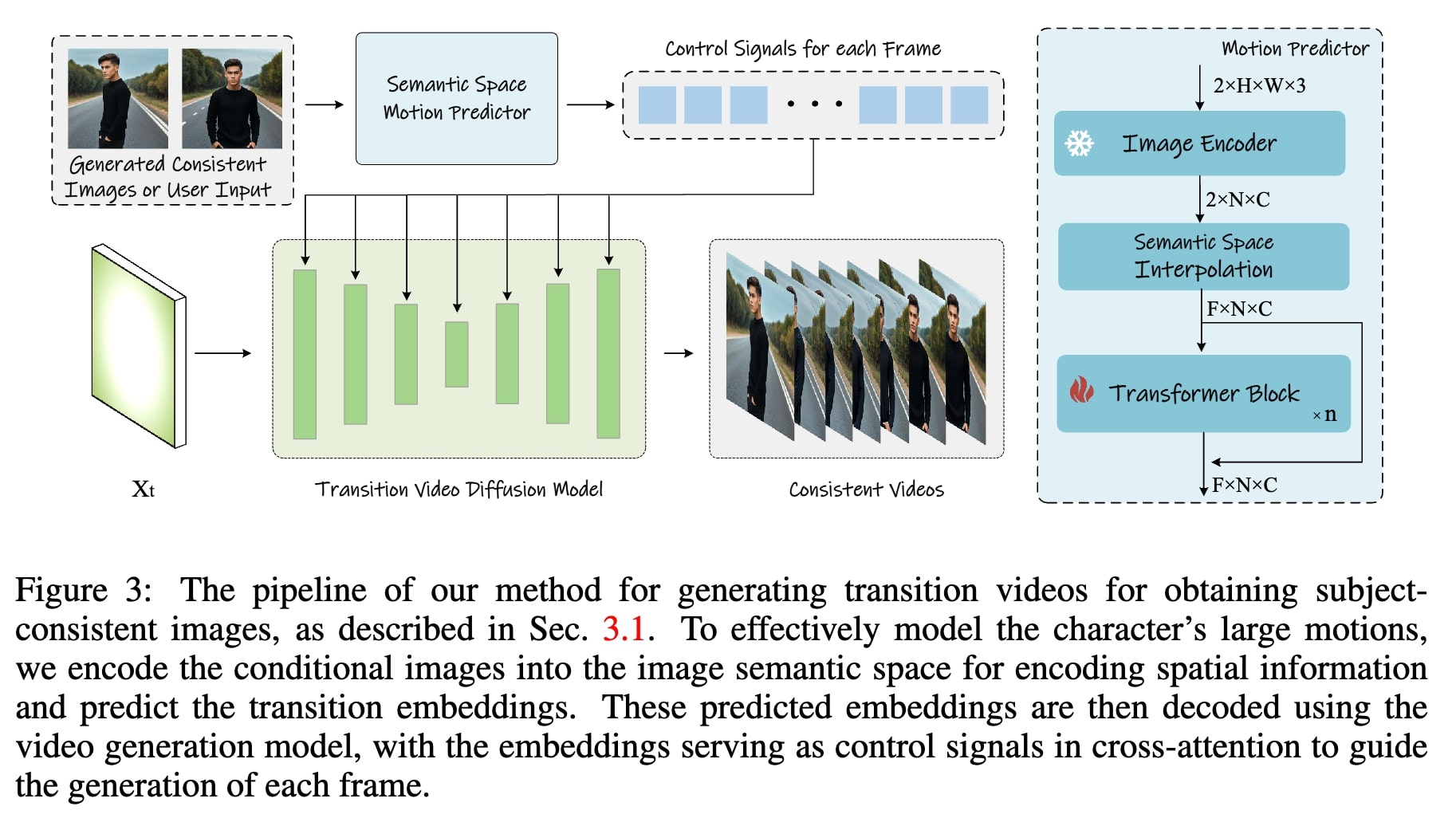
Paper: StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation
Github: https://github.com/HVision-NKU/StoryDiffusion
Project page: https://storydiffusion.github.io/
HuggingFace space: https://huggingface.co/spaces/YupengZhou/StoryDiffusion