本项目收集了2004年(第一届)至今(2024年第二十一届),中(全)国研究生数学建模竞赛获奖数据,使用R语言开展了数据处理和数据可视化工作。
这个项目的起因是,本人和队友在2015、2016、2017年参赛并获奖后,好奇一共有多少人连续获奖以及他们来自于哪个省份、哪个学校。于是2017年底,开始收集数据、写代码。当时正值毕业,也准备放弃MATLAB学习一门新的编程语言,认准R语言后,我开始尝试用R写这个项目,所以第一版的东西惨不忍睹。2018年9月15日,台风山竹登陆广州深圳,被迫居家办公后,我发现当日正是一年一度研究生数学建模开赛的日子,因此我决定再把这个项目重写一遍,并发布到github上。2020年初,由于新冠疫情,再一次被迫居家隔离,学习了Hadley编写的Advanced R一书后,我回顾自己前一年所学,开始重新审视自己的编程水平,于是决定再一次修改这个代码,并且以后每年都要来改一次,把这个项目延续下去,一是纪念当时和队友参赛的经历,二是检验自己的在过去一年的学习和进步。
关于项目的几个说明:
- 中国研究生数学建模竞赛(原名全国研究生数学建模竞赛,官方网址),2004年开办,每年9月开赛、11月~12月公布当年获奖结果,旧网址曾经有历年获奖数据,不过目前站点无法访问了;
- 本例收集自官方公布的最终获奖名单,大部分年份包含一等奖、二等奖、三等奖以及成功参与(参赛、参加)奖。由于参赛、提交并未被认定为作弊就能拿到成功参与奖,所以这里将获奖名单视为参赛名单,其中的一二三等奖视为获奖(部分年份未公布成功参与奖,因此这些年份无法统计参赛队伍数量和获奖率);
- 部分年份未公布获奖者选择的题型,因此定义这些年份的题型全部为N;
- 对于个人“连续获奖”这个概念,每个版本可能有不同算法,但基本原则是:
- 鉴于信息有限,只考虑同名、同学校在连续年份的获奖情况为“连续获奖”,即忽略“山大张三在2005年获奖后转学到中大并于2006年获奖”
- 鉴于信息有限,不区分同名不同人、但同校名的获奖情况,即将“山大张三于2005年获奖然后另一个也叫张三的山大学生于2006年获奖”,视为连续2次获奖
- 如果张三于2005年获奖,并于2007、2008年获奖,则将其视为两次连续获奖,第一次为1连,第二次为2连。注意第二次中,2007年为1连、2008年为2连,此做法为了精确统计某一年或某年段中,确定连续次数的连续获奖人数
- 其他详细说明见每个版本内的README文件
研究生三年的数模比赛经历,有惊喜也有遗憾,非常感谢我的队友。本人R语言水平有限,出于爱好编写这些代码,本项目仅限学习使用,切勿用于营利或其他违法目的。同时,也欢迎提出问题、讨论和交流。
最后,希望这个项目对你有所帮助。
可视化内容展示(应用已部署至阿里云:npmcm)
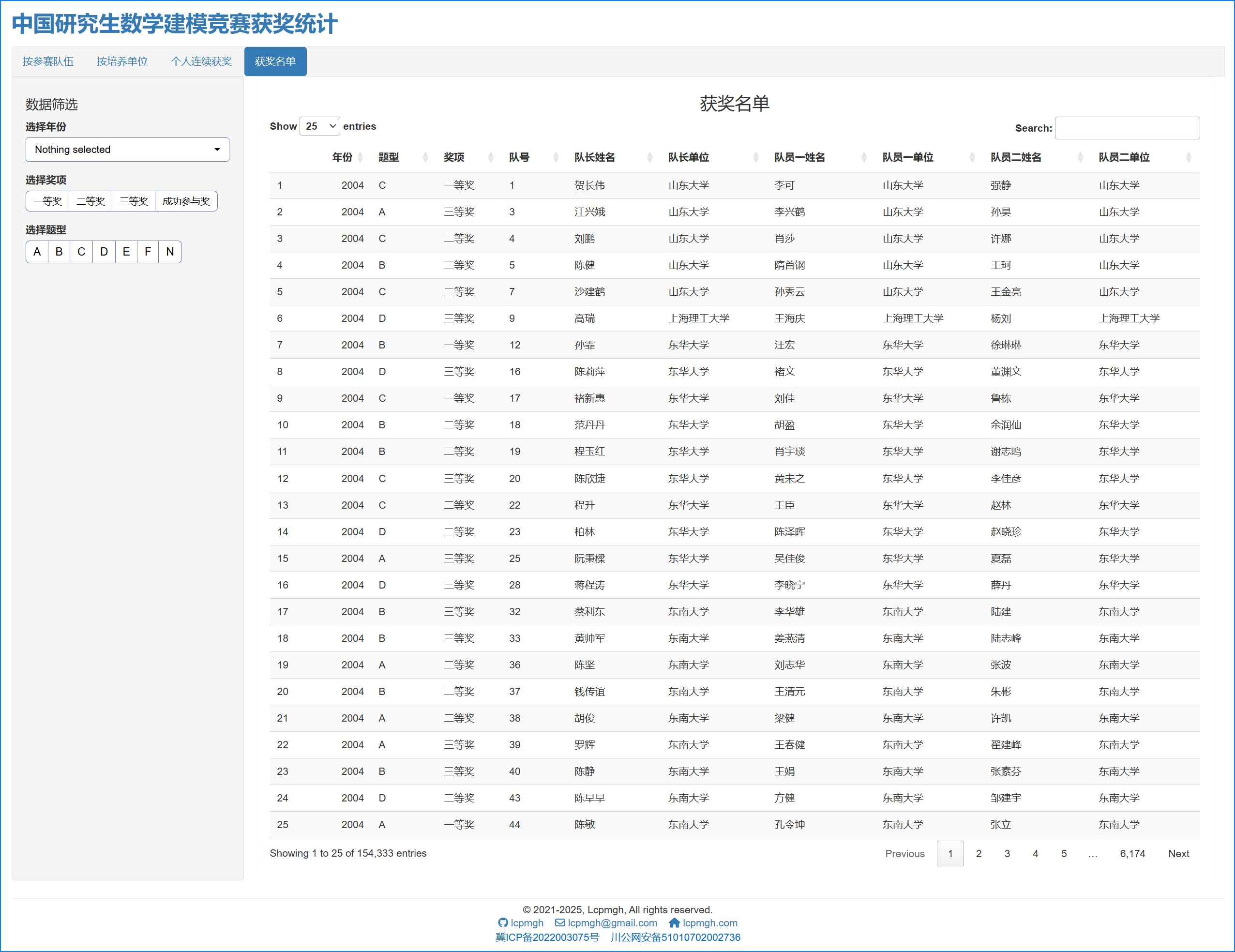
- 数据库查询
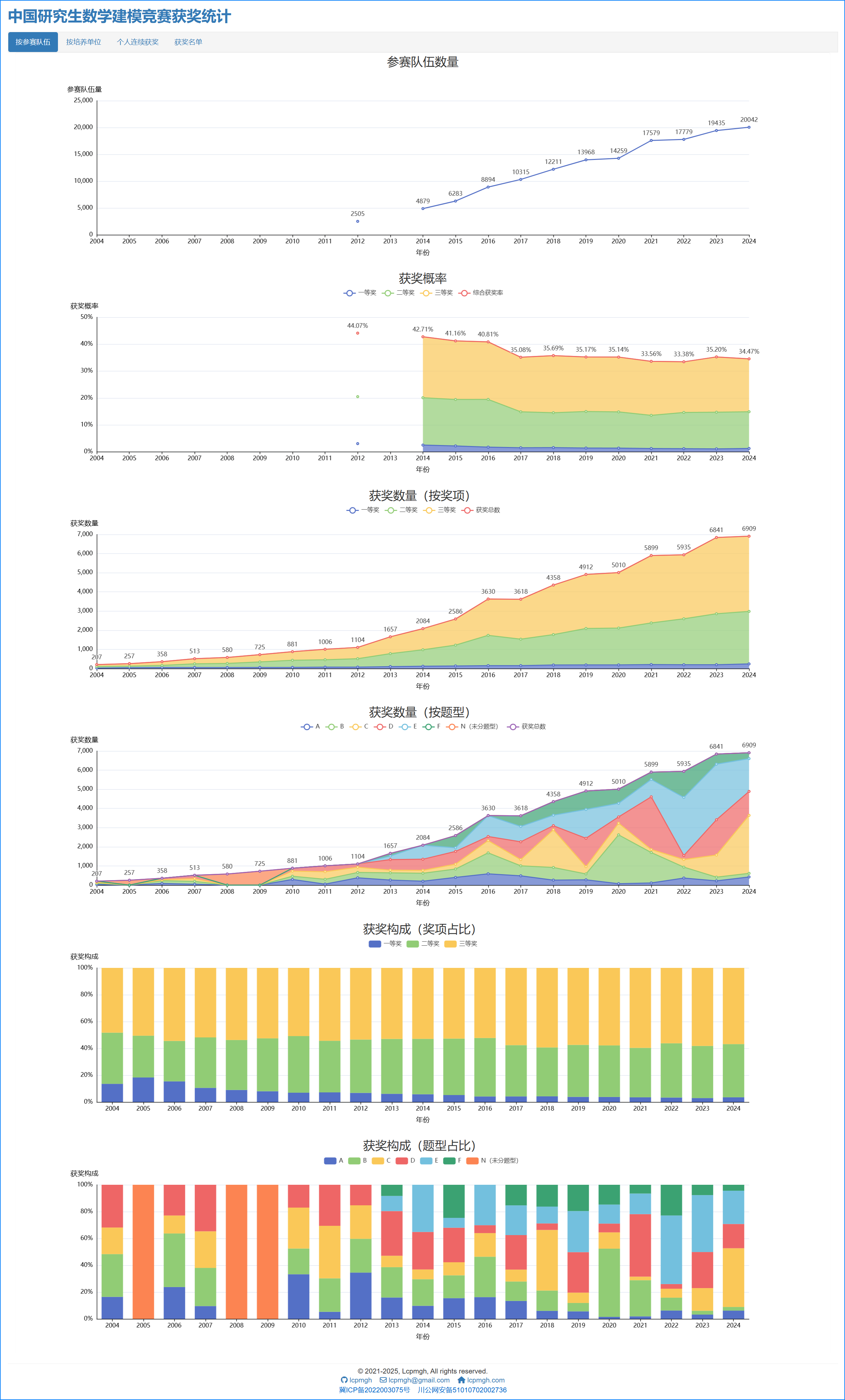
- 队伍获奖统计
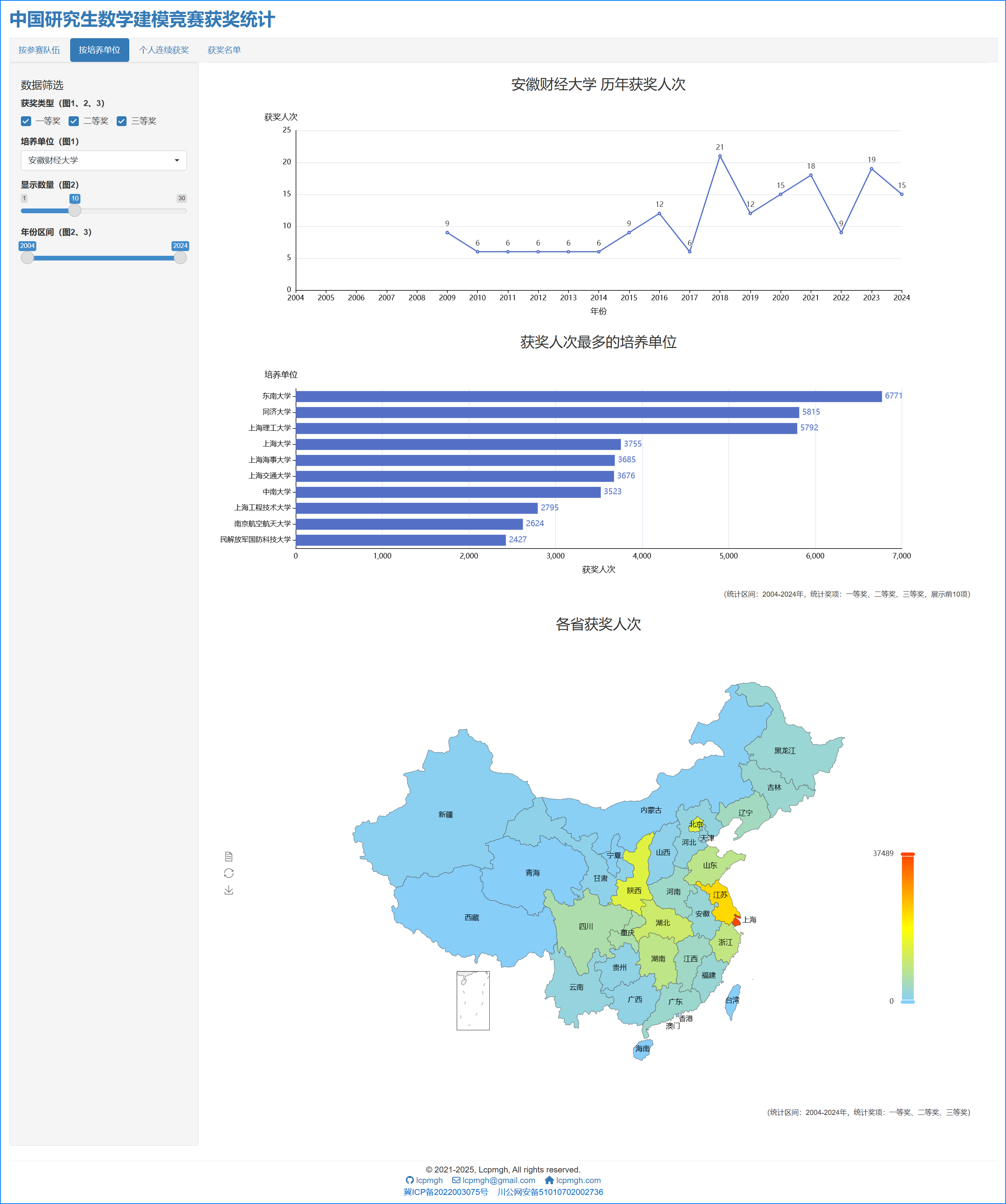
- 个人获奖统计
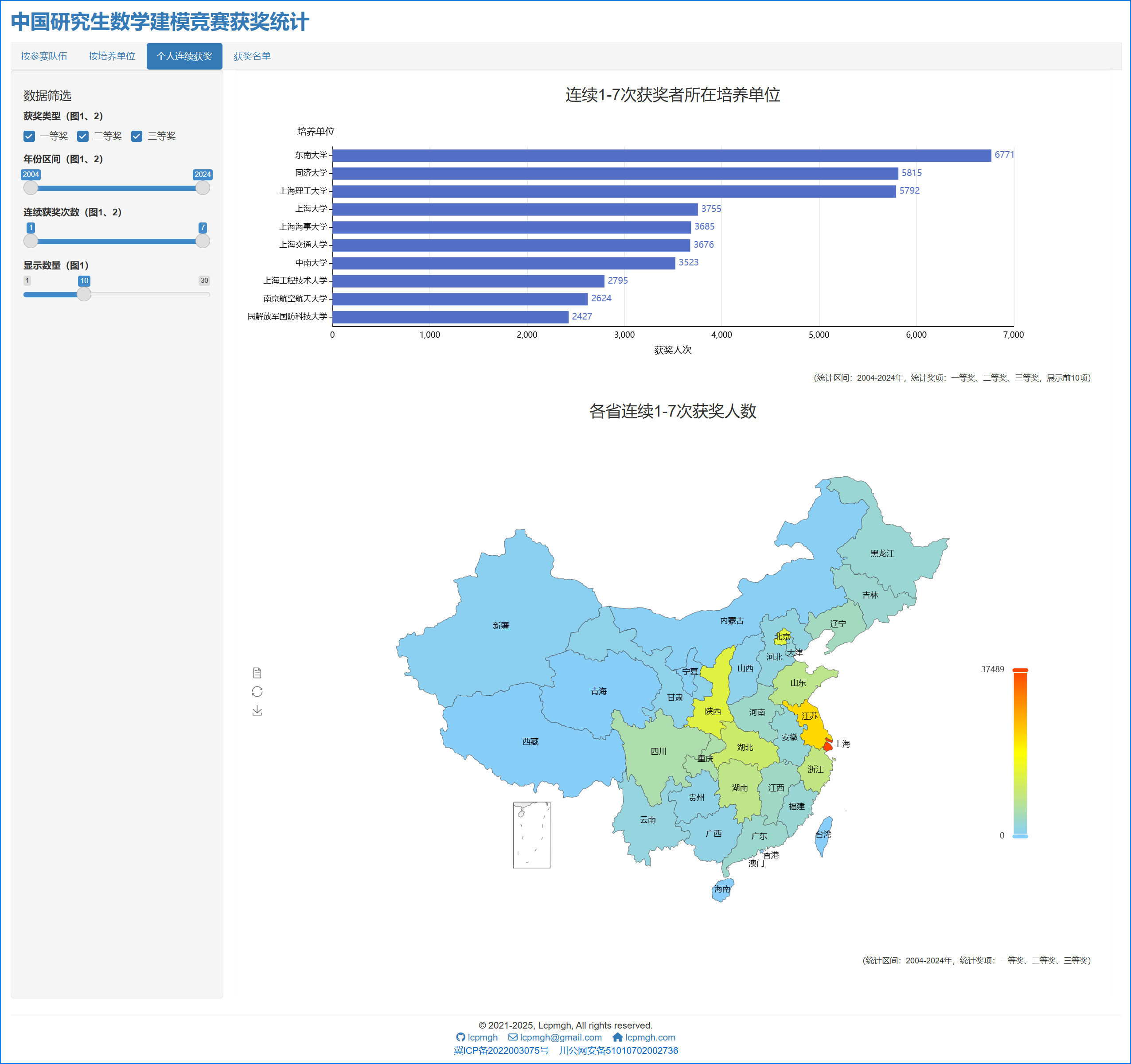
- 个人连续获奖统计
- 更新数据:获奖数据更新到2024年第二十一届。
- 数据问题:
- 2024年起,新增了国际赛道题目,目前仅两条数据,因此所有统计信息中,都没有考虑此类题型(题型为H、G,见2024.csv最后两行)。
- 目前已在3-unit_info_dataset.csv中添加了所有培养单位的所在的国家级、省级、地级信息,然而由于渲染地图非常耗时,因此并没有进一步分析、展示数据在地级行政区划上的分布信息,后续版本再去考虑。
- 添加了历年比赛题目数据,见@npmcm_questions_archive.csv,位于awardlist目录下。目前仅收集了赛题名,后续将对题目与获奖数据进行关联分析(具体赛题体量达GB级别,且赛题发布后官方还会通过多种途径补充、更正、解读等,本项目没有收集这些内容,如需查看请参见数学建模网)。
- 精简文件夹结构,将最新版本的文件夹放置至根目录下,其余旧版统一放于"Previous versions"文件夹。
- 更换、精简R包:
- 用
echarty包替换ECharts2Shiny包:后者可调参数少、版本旧、与绘制交互地图的REmap等包冲突。 - 用
echarty包替换ggplot2包:后者静态图并不适合shinyapp。 - 用
echarty包替换REmap包:后者很久没更新,现在画地图有bug。
- 用
- 更换页面顺序:最早版本将队伍信息放在第一页,然而由于
REmap与ECharts2Shiny冲突,因此将获奖名单改为了第一页,如今两个包都被替换,冲突问题得以解决,因此恢复了更为适合的页面顺序。 - 更改图类型:第一页中的获奖概率、获奖数量(按体型)和获奖数量(按奖项)三个图改为折线堆叠图,并且中堆叠图中添加了一个普通的折线图层,标记总和。
- 更改页面内容:将原第三页(现第二页)标题名改为”按培养单位“,并且添加了一个图,用以显示某特定培养单位历年获奖情况。
- 其他细节:优化了页面整体siderbar和mian的布局效果。
- 声明:第二、三页的省级区划地图下载自GeoJSON,为提高在app中的渲染速度和美观性,使用在线网站以及本地优化,精简了多边形(除澳门和十段线以外,因为这些区域优化过程中容易被完全删除)、将南海诸岛图位置移动至左下并更改了部分省份label的出现位置(即json中的cp属性,最终修改结果见
./v7.0/shiny_app/data/0-china_province_simplified.json)。因此,该地图仅作为本app数据分布的示意图,不附带作者的任何政治立场,其json数据也仅供此app使用,特此声明。
- 更新数据:获奖数据更新到2023年第二十届。
- 添加图:第二页,添加参与队伍数量折线图。
- 更新数据:获奖数据更新到2022年第十九届。
- 更新工具和数据:使用Centos7.9.2009平台编程,其中R语言版本为v4.1.2,Rstudio Server版本为2021.09.2 Build 382,Shiny Server版本为v1.5.17.973,所有涉及到的packages在使用前都已于2022年01月升级到最新版本。获奖数据更新到2021年第十八届。
- 更改关键R包:可视化程序中,使用REmap包代替之前版本中的rgdal包,进行获奖数据省域分布图的绘制,相比之下REmap绘制的地图有以下优点,1不再需要处理shap数据从而提高效率,2动态化地图更易于交互界面查看。
- 更改数据中省份名称:由于改用REmap包,由原来rgdal使用的省份长名(如“北京市”),转变为REmap包使用的省份短名(如“北京”),因此将数据1-unit_info_internet.csv和3-unit_info_dataset.csv中的省份名称改为短名,同样的,数据处理结果中,相应文件中的省份名称也转变为短名。
- 更改可视化程序中的页面布局顺序:编写shinyapp过程中发现,REmap包显示地图,与其他控件不兼容(推测),表现为若先点击REmap地图所在页面,则其他页面的部分控件(包括shinyWidgets控件、DT表格、reactable表格)将无法显示,此bug我暂时无法解决。权宜之计,改变之前版本的页面布局顺序,将之DT包展示的获奖数据库页面,调整为可视化程序的首页。
- 更改可视化程序的代码结构:简化shinyapp中的UI函数,改用uiOutput和renderUI,优点是可以根据数据内容生成控件参数值,避免每次更新数据后都要修改控件(例如UI中年份选择范围);另外,按UI的tablepanels页面(而不是之前版本中的按数据和模块)组织代码,尽量做到将renderUI和对应数据、output函数放在一起,便于维护。
- 部署shinyapp至云服务器:此项目的shinyapp已部署在云服务器上,欢迎访问npmcm。
- 其他细节:在data_processing.R中补充说明了仅更新获奖数据时的执行步骤;在shiyapp中调整了队伍页面的展示图,改为获奖率、获奖数量和获奖构成相关的五个图;修改了shinyapp中的其他一些细节问题;修改了data文件夹中readme文件,添加了对该文件夹中的数据的说明。
- 更新工具和数据:R语言版本为v4.0.5,Rstudio版本为1.4.1106,所有涉及到的packages在使用前都已于2021年04月26日升级到最新版本。获奖数据更新到2020年第十七届;
- 优化代码:将数据处理部分的代码整理到一个文件中,修改了相关函数名和变量名;
- 优化文件(夹)名:规范了文件和文件夹的名称,在文件名中区分了读取或是生成顺序,便于查找和识别。
- 优化文件存储路径:将获奖名单的原始数据保存在根目录下的文件夹中,今后每个版本都在此读取原始文件,将中间过程所需或所产生的数据文件保存在./shiny_app/data中,便于可视化;
- 修复问题:进一步完善了获奖名单中,培养单位名称不统一问题,即进一步更新了0-unit_name_convert.csv文件;
- 添加可视化图表:在shiny的第一页中添加了“获奖率年际变化“图和”获奖题型构成比例年际变化“图,其中,部分年份获奖名单中没有出现成功参与奖,则此年度获奖率空缺,此外,为避避免歧义,修改了可视化中图表的标题、图例、坐标轴名称等部分文字描述;
- 其他:由于此版本强制规定读取和保存的csv文件为UTF-8编码,导致在我的电脑上,shiny部分第四页的获奖信息查询系统不能正常使用了,猜想是由于windows中Rstudio打开的shinyui为GB2312,在此部分查找信息时的输入文字为GB2312,与底层数据编码矛盾导致的。然而,虽然强制规定了编码,但还是由于编码问题,此shinyapp并不能上传到shinyapps.io。
- 数据更新到最近的2019年;
- 规范、明确了整个数据处理流程,并试图兼容以后的数据更新(但是shinyui部分还做不到,现在那里的代码必须写成年份的确切数字,还没想到如何根据获奖数据自行生成);
- 添加了对获奖数据中,同一培养单位名称不统一的处理工作(由于这里需要人工建立名字的识别替换数据集,所以只能尽力统计,难免有遗漏);
- 优化代码运行效率,尽量避免循环语句和代码重复;
- 重新设计了求连续获奖年份的算法,其核心是data.table包的分而治之方法和采用差分算法的自编函数find_series,具体内容见代码文件./v2.0/3_create_award_team_member.r;
- 除爬虫收集的原始数据和地图数据外,所有csv文件改用GB2312编码,以避免本地运行时出现乱码;
- 之前的代码和数据被放在v1.0文件夹中,但原始代码没有改动,修改文件夹路径会造成运行不了的情况;
- 一些小问题,比如2013年有一位队员只有名字没有培养单位名,已经按队友的信息进行补全,且由于全数据中只有一个,所以没做代码上的识别判断,直接在原数据上修改了。
- 项目第一次修改,更新说明见./v1.0/READ_v1.0.md
- 项目创建