SourceRank 2.0 #1916
Comments
|
The initial pass at implementing SourceRank 2.0 will be focused on realigning how scores are calculated and shown using existing metrics and data that we have, rather than collecting/adding new metrics. The big pieces are:
|
|
There are a few places where the sourcerank 1.0 details/score are exposed in the API that need to be kept around for backwards compatibility:
For the first pass, sourcerank 2.0 is going to focus on just packages published to package managers, we'll save the repository sourcerank update for later as it doesn't quite match so well with the focus on projects. So the following repo sourcerank details in the api will remain the same:
|
|
Starting to implement bits over here: #2056 |
|
One other thing that springs to mind, the first pass of the implementation will focus at a project level and only really considers the latest release. Then we'll move on to tackle #475 which will store more details at a per-version level, which will then allow us to calculate the SourceRank for each version. |
|
Making good progress on filling in the details of the calculator, current approach for scoring is to take the average of the different categories scores and for each category take the average of the different scores that go into it too, with the max being 100 for score. |
|
Example of the current breakdown of implemented scores:
|
|
Things to think about soon:
Also because scores now take into account other projects within an ecosystem, we'll likely want to recalculate lots of scores at the same time in an efficient way, for example:
|
|
Added an actual method to output the breakdown of the score: {
"popularity": {
"dependent_projects": 0,
"dependent_repositories": 0
},
"community": {
"contribution_docs": {
"code_of_conduct": false,
"contributing": false,
"changelog": false
}
},
"quality": {
"basic_info": {
"description": true,
"homepage": false,
"repository_url": false,
"keywords": true,
"readme": false,
"license": true
},
"status": 100
}
} |
|
Thinking about dependency related scores, here's my current thinking:
Eventually we should also look at the size and complexity of the package, as those rules could encourage vendoring of dependencies to avoid them reducing the score. |
|
First pass at an implementation for the calculator is complete in #2056, going to kick the tires with some data next |
|
Current output for a locally synced copy of Split: {
"popularity": {
"dependent_projects": 0,
"dependent_repositories": 0,
"stars": 0,
"forks": 0,
"watchers": 0
},
"community": {
"contribution_docs": {
"code_of_conduct": true,
"contributing": true,
"changelog": true
},
"recent_releases": 0,
"brand_new": 100,
"contributors": 100,
"maintainers": 50
},
"quality": {
"basic_info": {
"description": true,
"homepage": true,
"repository_url": true,
"keywords": true,
"readme": true,
"license": true
},
"status": 100,
"multiple_versions": 100,
"semver": 100,
"stable_release": 100
},
"dependencies": {
"outdated_dependencies": 100,
"dependencies_count": 0,
"direct_dependencies": {
"sinatra": 42.99146412037037,
"simple-random": 45.08333333333333,
"redis": 42.58333333333333
}
}
} |
|
I just found an issue with SourceRank's "Follows SemVer" scoring that is not mentioned here. I'm hoping it can be resolved in the next version of SourceRank, and that this is the right place to bring this up: The relevant standard that Python packages must adhere to for versioning is defined in PEP 440: As that page says, “the recommended versioning scheme is based on Semantic Versioning, but adopts a different approach to handling pre-releases and build metadata”. Here is an example Python package where all the release versions are both PEP 440- and SemVer-compliant. But the pre-release versions are PEP 440-compliant only. Otherwise interoperability with Python package managers and other tooling would break. The current SourceRank calculation gives this package (and many other Python packages like it) 0 points for "Follows SemVer" due to having published pre-releases. (And only counting what was published recently wouldn't fix this.) Can you please update the SourceRank calculation to take this into account? Perhaps just ignoring the SemVer requirement for pre-release versions of Python packages, which it’s impossible for them to satisfy without breaking interop within the Python ecosystem, would be a relatively simple fix? Thanks for your consideration and for the great work on libraries.io! |
|
@jab ah I didn't know that, yeah I think it that makes sense, rubygems has a similar invalid semver prerelease format. I was thinking about adding in some ecosystem specific rules/changes, this is a good one to experiment with. |
|
Sourcerank 2.0 things I've been thinking about over the long weekend:
|
|
Packagist/composer also defines similar: https://getcomposer.org/doc/04-schema.md#version It seems like "follows [ecosystem specific version schema]" would be a better criteria than "follows SemVer", but I can see that this could add a lot of additional complexity when you deal with a lot of languages. |
|
I've added Also highlights the need for #543 sooner rather than later for all the package managers that use Tags rather than Versions. |
|
Mos of the Versions updated: 11,658,167 And just for fun, the average number of runtime dependencies across: all versions: 3.03 Project data broken down by ecosystem: "NuGet"=>1.71, *CRAN doesn't use python are still running: "Pypi"=>0.08 |
|
Some other thinks to note down:
Next up I'm going to add the |
|
Here's what the breakdown looks like now for rails (on my laptop, missing some data) {
"overall_score": 81,
"popularity": {
"score": 60.0,
"dependent_projects": 0.0,
"dependent_repositories": 0.0,
"stars": 100.0,
"forks": 100.0,
"watchers": 100.0
},
"community": {
"score": 93.33333333333333,
"contribution_docs": {
"code_of_conduct": true,
"contributing": true,
"changelog": false
},
"recent_releases": 100,
"brand_new": 100,
"contributors": 100,
"maintainers": 100
},
"quality": {
"score": 80.0,
"basic_info": {
"description": true,
"homepage": true,
"repository_url": true,
"keywords": true,
"readme": true,
"license": true
},
"status": 100,
"multiple_versions": 100,
"semver": 0,
"stable_release": 100
},
"dependencies": {
"score": 89.66666666666667,
"outdated_dependencies": 100,
"dependencies_count": 89,
"direct_dependencies": {
"sprockets-rails": 72,
"railties": 83,
"bundler": 77,
"activesupport": 84,
"activerecord": 75,
"activemodel": 85,
"activejob": 83,
"actionview": 82,
"actionpack": 82,
"actionmailer": 81,
"actioncable": 81
}
}
} |
|
More fiddling with local data, tables to compare sourcerank 1 and 2 scores this time. Top 25 local ruby projects ordered by sourcerank 1:
Top 25 local ruby projects by both sourcerank 1 and 2
Same as the first table but with top 50 and github star column included:
All of these are missing a lot of the "popularity" indicators as I just synced a few hundred rubygems locally without all the correct dependent counts. |
|
And at the bottom end of the chart:
|
|
Taking text-format as a low scoring project as an example of things in possibly change: {
"overall_score": 36,
"popularity": {
"score": 0.0,
"dependent_projects": 0.0,
"dependent_repositories": 0,
"stars": 0,
"forks": 0,
"watchers": 0
},
"community": {
"score": 30.0,
"contribution_docs": {
"code_of_conduct": false,
"contributing": false,
"changelog": false
},
"recent_releases": 0,
"brand_new": 100,
"contributors": 0,
"maintainers": 50
},
"quality": {
"score": 66.66666666666666,
"basic_info": {
"description": true,
"homepage": true,
"repository_url": false,
"keywords": false,
"readme": false,
"license": false
},
"status": 100,
"multiple_versions": 0,
"semver": 100,
"stable_release": 100
},
"dependencies": {
"score": 49.0,
"outdated_dependencies": 0,
"dependencies_count": 99,
"direct_dependencies": {
"text-hyphen": 48
}
}
}
Looking inside the source of the gem, there is:
We can definitely add support for detecting changelog and readme to the version-level metadata and feed that back in here once complete. |
|
Updated the calculator to not punish projects that aren't on GitHub, here's the new breakdown for {
"overall_score": 42,
"popularity": {
"score": 0.0,
"dependent_projects": 0.0,
"dependent_repositories": 0,
"stars": null,
"forks": null,
"watchers": null
},
"community": {
"score": 50.0,
"contribution_docs": {
"code_of_conduct": null,
"contributing": null,
"changelog": null
},
"recent_releases": 0,
"brand_new": 100,
"contributors": null,
"maintainers": 50
},
"quality": {
"score": 68.0,
"basic_info": {
"description": true,
"homepage": true,
"repository_url": false,
"keywords": false,
"readme": null,
"license": false
},
"status": 100,
"multiple_versions": 0,
"semver": 100,
"stable_release": 100
},
"dependencies": {
"score": 49.0,
"outdated_dependencies": 0,
"dependencies_count": 99,
"direct_dependencies": {
"text-hyphen": 48
}
}
} |
|
Other related areas to think about when it comes to different levels of support for package manager features we have:
|
|
|
Probably also want to skip the
|
|
Three of the double false package managers in the table are editor plugins and don't really do dependencies: Alcatraz, Emacs, Sublime The others are either smaller, we don't have any support for versions or don't have a concept of dependencies: Inqlude, Nimble, PlatformIO, PureScript, Racket, WordPress |
|
Atom is also a little weird here because it depends on npm modules and uses package.json, so doesn't really have either, but is flagged as having both, basically all the editor plugins don't really work for dependent_* scores |
|
Three (very early) concepts for the popover that explains what the SourceRank 2.0 rating is A few known issues we need to tackle:
|

|
A couple other screenshots of bits I was experimenting with on Friday in this branch: https://github.com/librariesio/libraries.io/tree/sourcerank-view
|


|
Making progress on Sourcerank 2.0 (now known as Project Score because trademarks 😅) again, I've merged and deployed #2056 and have calculated the scores for all the rust packages on Cargo, will report back one the score breakdowns shortly. |
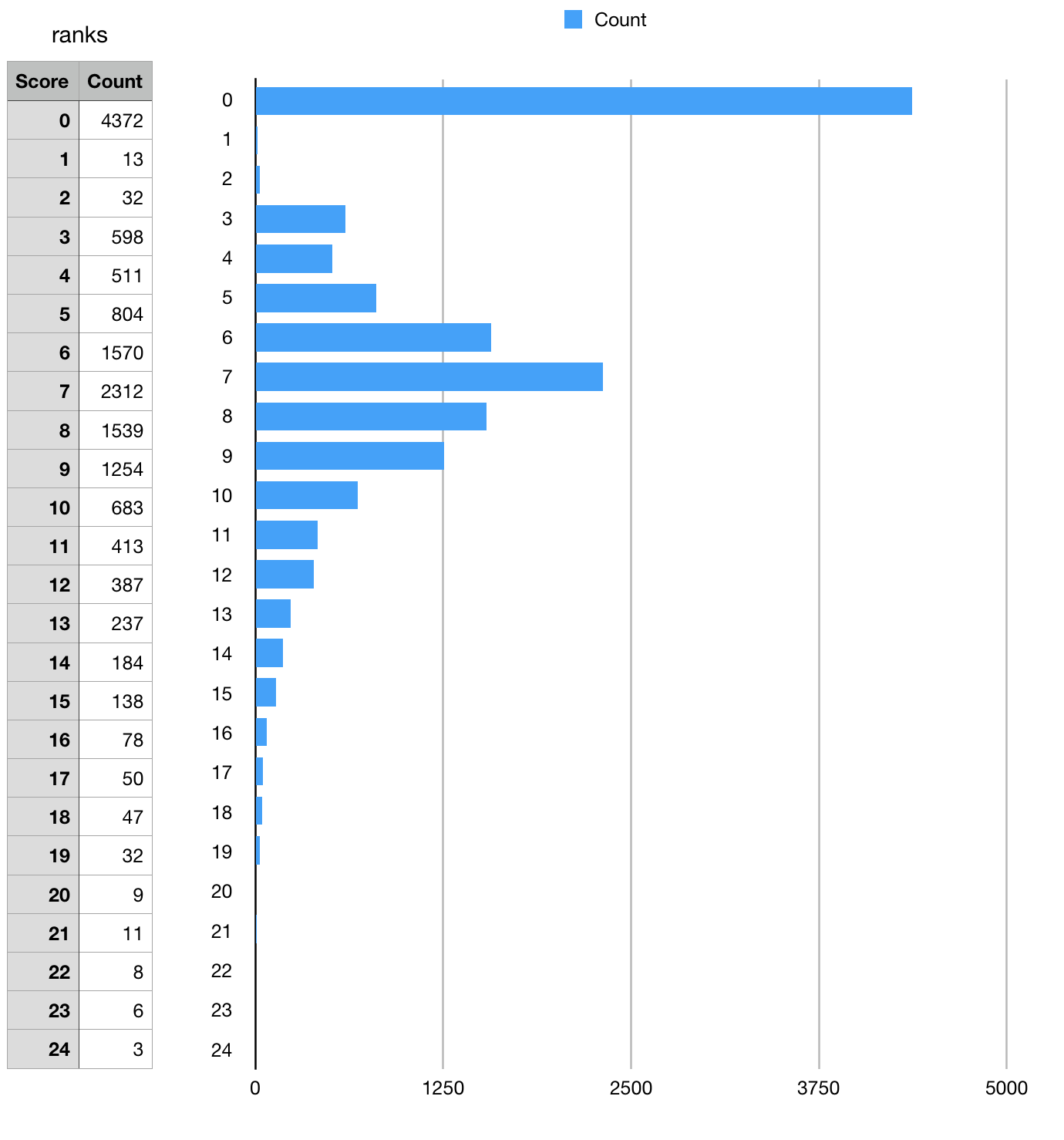

|
Similar graphs for Hex, the elixir package manager: Sourcerank 1.0 distribution:
Sourcerank 2.0 distribution:
|


|
Projects with low scores are receiving quite a large boost from having zero or very few high scoring dependencies, which made me think that maybe we should skip dependency scores for projects with no dependencies. But @kszu made a good point in slack, rake is very highly used and has no dependencies which is seen as a plus, skipping the dependencies score for that would lower its score. We do skip the whole dependency block on a per-ecosystem basis if there's no support for measuring dependencies, but if we do support it, it feels like we should keep the same set of rules for each package within a given ecosystem. |
|
Successfully generated the new scores for all rubygems, distribution curve is looking pretty good:
|

|
I've now implemented a This then has a set of queues stored in Redis (one for each platform), which contain the ids of projects that need a recalculation, which slowly empties after each run and avoids recalculating things over and over. Overall calculating the score for a number of projects in an ecosystem is much faster than sourcerank 1.0, mostly because the Projects from Rubygems, Cargo and Hex are automatically being queued for recalculation after being saved, will be enabling more platforms once the initial scores have been calculated |
|
It's now enabled on: alcatraz, atom, cargo, carthage, dub, elm, emacs, haxelib, hex, homebrew, inqlude, julia, nimble, pub, purescript, racket, rubygems, sublime, swiftpm
Next steps:
|
|
Project scores are now being calculated for all platforms, the backlog is pretty long, will likely take 24 hours to work through all the calculations. |
|
Adding a basic score overview page:
|

|
Going to work on improving the explanations around each element of the score breakdown page as well as including the raw data that goes into the breakdown object (number of stars, contributor count etc) so that it can be stored in the database in a way that doesn't require the calculator to load data on demand as well as being able to show historic changes for each element. |
|
Hello, I have a question about sourcerank: what is the point of using GitHub stars? I don't really understand what sourcerank is aiming to do: half of its elements are about the project's health, and how close it is to standards (Basic info, Readme, license...), whereas the other half is about the project's popularity (contributors, stars and dependants). If sourcerank was aiming at showing how wealthy is a package, the "popularity" information would be useless, and its whealthy requirements should be even stricter. On the other hand, if the goal is to compare it with it forks, clones or similar projects, then the impact of the "popularity" information should be more important. For instance, imagine two similar projects are doing the same thing and are perfectly well configured. They will mostly have the very same sourcerank. Some projects are one-man projects, updated once in a while. It does not reflects the project's activity. Is it planned in the 2.0 version to fix those issues? I've seen great improvements above, and was also wondering if the way those data was calculated has drastically changed or not. I really enjoy Regards, |
|
One more problem (I think I has already been posted here) is that many projects have 0 SemVer score because they didn't follow SemVer in the early releases. How do you plan to fix that? Also, there could be a problem with outdated dependencies. Maybe you could only count this if more than one dependency is outdated or depending on release type (major, minor, patch). Some problems are also with not brand new. Sometimes the score for this is 0 because project has changed name or repository. When do you plan to release SourceRank 2.0 to main website? |
SourceRank 2.0
Below are my thoughts on the next big set of changes to "SourceRank", which is the metric that Libraries.io calculates for each project to produce a number that can be used for sorting in lists and weighting in search results as well as encouraging good practises in open source projects to improve quality and discoverability.
Goals:
History:
SourceRank was inspired by google pagerank as a better alternative score to GitHub Stars.
The main element of the score is the number of open source software projects that depend upon a package.
If a lot of projects depend upon a package that implies a some other things about that package:
Problems with 1.0:
Sourcerank 1.0 doesn't have a ceiling to the score, the project with the highest score is mocha with a sourcerank of 32, when a user is shown an arbitrary number it's very difficult to know if that number is good or bad. Ideally the number should either be out of a total, i.e. 7/10, a percentage 82% or a score of some kinda like B+
Some of the elements of sourcerank cannot be fixed as they judge actions from years ago with the same level as recent actions, for example "Follows SemVer?" will punish a project for having an invalid semver number from many years ago, even if the project has followed semver perfectly for the past couple years. Recent behaviour should have more impact that past behaviour.
If a project solves a very specific niche problem or if a project tends to be used within closed source applications a lot more than open source projects (LDAP connectors, payment gateway clients etc) then usage data within open source will be small and sourcerank 1.0 would rank it lower.
Related to small usage factors, a project within a smaller ecosystem will currently get a low score even if it is the most used project within that whole ecosystem when compared to a much larger ecosystem, elm vs javascript for example.
Popularity should be based on the ecosystem which the package exists within rather than within the whole Libraries.io universe.
Quality or issues with dependencies of a project are not taken into account, if adding a package brings with it some bad quality dependencies then that should affect the score, in a similar way, the total number of direct and transitive dependencies should be taken into account.
Projects that host their development repository on GitHub currently get a much better score than ones hosted on GitLab, Bitbucket or elsewhere. Whilst being able to see and contribute to the projects development is important, where that happens should not influence the score based on the ease of access to that data.
Sourcerank is currently only calculated at the project level, but in practise the sourcerank varies by version of a project as well for a number of quality factors.
Things we want to avoid:
Past performance is not indicative of future results - when dealing with voluteeners and open source projects where the license says "THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND" we shouldn't reward extra unpaid work
Metrics that can easily be gamed by doing things bad for the community, i.e. hammering the download endpoint of a package manager to boost the numbers
Relying to heavily on any metrics that can't be collected for some package managers, download counts and dependent repository counts are
Proposed changes:
Potential 2.0 Factors/Groupings:
Usage/Popularity
Quality
Community/maintenance
Reference Links:
SourceRank 1.0 docs: https://docs.libraries.io/overview#sourcerank
SourceRank 1.0 implementation:
Metrics repo: https://github.com/librariesio/metrics
Npms score breakdown: https://api.npms.io/v2/package/redis
The text was updated successfully, but these errors were encountered: