high write load on hdd #4689
Comments
|
Did you start seeing this with this version of LND, or did you notice it also before? |
|
I'm seeing a similar problem, LND is running on on AWS t2.small (Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz with 2 GB RAM) mounted on gp2 SSD storage. Only running LND on that host. After a recent LND update kernel consistency maxed out on iowaiting: I checked with atop that the writes are coming from lnd only Versions
|
|
That's weird. Do you see any writes to the swap area? As in, is the box running out of physical memory? Could you maybe get a goroutine profile to find out what exactly |
|
Swap is disabled and I don't suspect that writes are coming from page cache. I don't have cycles to run the profile. I'm running another experiment for #4669 Maybe it would be useful for internal testing to spin up a node on AWS with 2GB RAM. Here is the monitoring of my CPU (%1 actually means 1 core here) and memory: |

|
How much memory is |
In your logs, if you crank |
|
@halseth there has always been a constant write load by lnd. It increased five times about two weeks ago. I can not tell any more if this was rc4 or rc5. Strangely the write load decreased to the normal high load of 50kb/s after restarting rc5 yesterday. |


|
@Roasbeef memory usage with around 50 active channels is at ~300MB resident memory and ~2.4GB virtual memory.
|

|
|


|
I am also having issues with LND (0.11.1-beta) writing excessively (several GB in a few hours). I only had one channel at the time (now I have zero). I don't know what's normal, but I'm seeing about 5000 log lines/minute from PEER on debug. |
What are the log lines? Channel Updates? |
|
@hpbock so you're saying the increased I/O is correlated with your update to 0.11.1? |
Mostly channel updates, yes |
|
I had the same issue. |


|
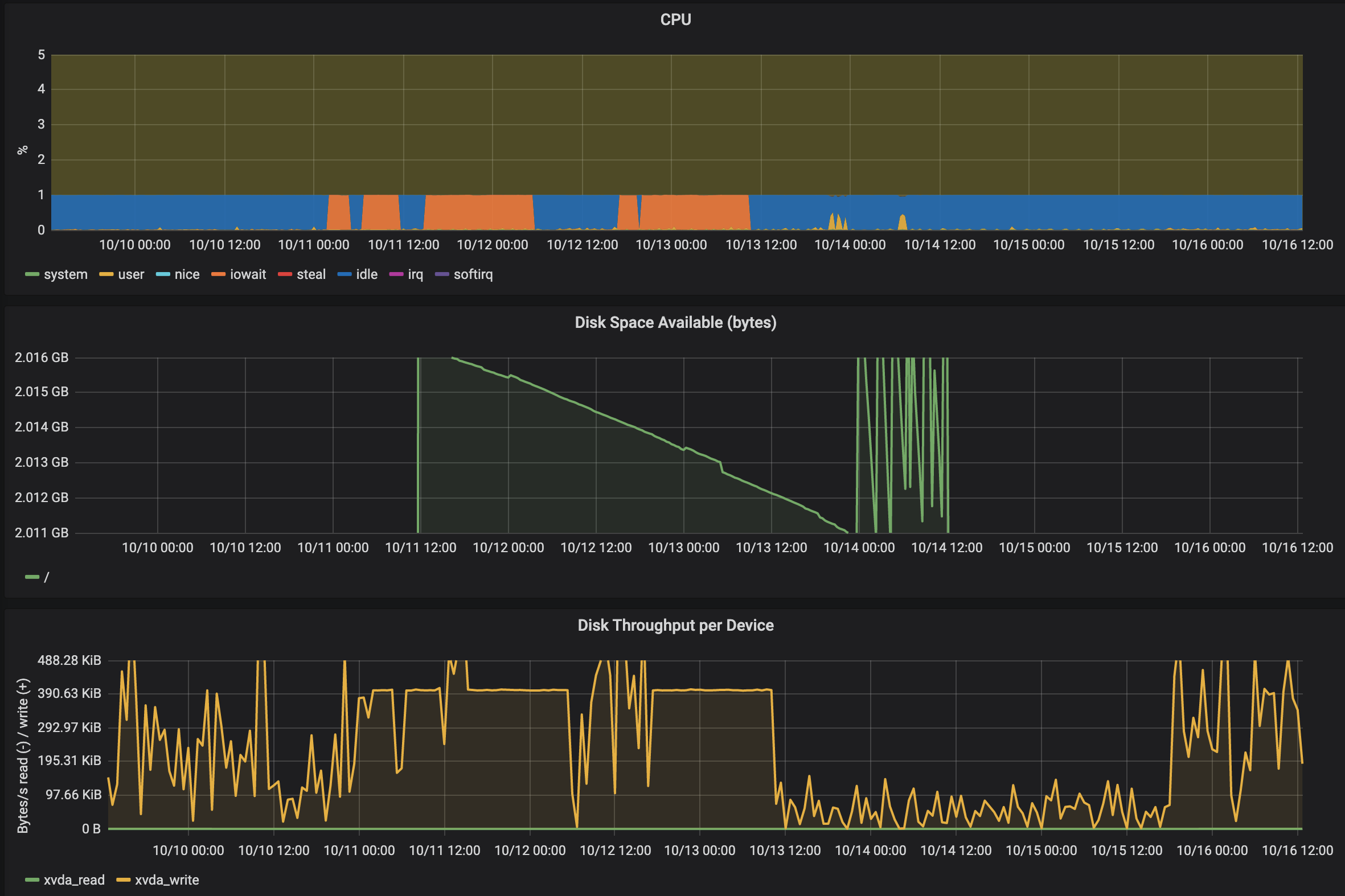
@Roasbeef I can not say, if the load is directly correlated with 0.11.1. What I currently observe is, that the load yesterday suddenly raised by 6 times as you can see in the attached graphs below. Beside the different levels of write load I wonder, why LND writes much more data onto the filesystem than it ever reads. (on average reading 10kb/s vs writing 60 kb/s)
It seems that there are a lot of channel updates right now. $ grep PEER .lnd/logs/bitcoin/mainnet/lnd.log | grep Received\ ChannelUpdate | cut -c 254-319 | sort | uniq | while read peer a; do echo -n $peer; grep $peer ~/.lnd/logs/bitcoin/mainnet/lnd.log | wc; done
024a8228d764091fce2ed67e1a7404f83e38ea3c7cb42030a2789e73cf3b341365 975 14536 328164
02572c2e1b43a78bb060e7d322b033443efc0d8d60fc2b111dd8bb999aa940d1f5 92 1031 21400
0260fab633066ed7b1d9b9b8a0fac87e1579d1709e874d28a0d171a1f5c43bb877 50 418 7934
02ad6fb8d693dc1e4569bcedefadf5f72a931ae027dc0f0c544b34c1c6f3b9a02b 68 640 13342
02dfdcca40725ca204eec5d43a9201ff13fcd057c369c058ce4f19e5c178da09f3 54 460 9072
0311cad0edf4ac67298805cf4407d94358ca60cd44f2e360856f3b1c088bcd4782 444 6311 139841
03205b045b0126c0d3fb826a38b9befc4babf51689544908c704d8e51fdec75ffb 46 380 7248
033d8656219478701227199cbd6f670335c8d408a92ae88b962c49d4dc0e83e025 974 14512 325430
037f990e61acee8a7697966afd29dd88f3b1f8a7b14d625c4f8742bd952003a590 1020 14959 335235
03abf6f44c355dec0d5aa155bdbdd6e0c8fefe318eff402de65c6eb2e1be55dc3e 1856 27616 620938
03aca0142349abf19e96a3c9231d556a1525182b659e8b2ae5328efbd01ff227e1 987 14678 333144There seem to be some either frequent or redundant channel updates: $ grep PEER .lnd/logs/bitcoin/mainnet/lnd.log | grep Received\ ChannelUpdate | cut -c 137-168 | sort | uniq | wc
2752 2752 90816
$ grep PEER .lnd/logs/bitcoin/mainnet/lnd.log | grep Received\ ChannelUpdate | cut -c 137-168 | sort | wc
3258 3258 107514 |


|
@hpbock this is really cool, i'm looking at |
|
I'm having the same issue after updating to v0.11.1-beta a week go, disk I/O went crazy. I'm running with Neutrino if that helps, not sure if somebody else is also using Neutrino but might not be related to it. |
|
I'm seeing this issue on AWS with neutrino as well. Disk I/O is hosed. |
|
Are the others in this thread also running neutrino? At a glance, I don't think that would affect things at all though, given it only will write to disk when doing transaction updates, or rescanning blocks. @alevchuk's comment re the relationship between disk writes and total consumed space makes me think this might indeed be channel updates. For those active in the thread: are you running with sync free list mode on (the non-default), and also when was the last time you compacted your database? Another:
|
|
compact channel.db weekly. 22 peers, 11 channels |
|
@Roasbeef i am running LND with bitcoind. I think sync freelist is false since I have not yet heard about that option. Same with compact database, how can I do that? Here is my graph of peers and channels: |

|
@Roasbeef Running LND with Neutrino. Brand new instance with 6 LND's, 8gb ram, 4 cores and 100gb SDD. Never compacted the database since the nodes are a week old or so. Each node has 1 peer and 1 channel.
Never experienced this problem before upgrading to v0.11. Seeing this in the logs every 5 seconds, I'm running my own Knots server: |
|
I ran an experiment with a new mainnet Neutrino node on Digital Ocean. Both version v0.10.4 and v0.11.1 stabilizes between 200-600 kb/s of writes for me. No significant difference between the two version as far as I can tell. Which leads me to think what has changed is the amount of network activity (channel updates), not lnd itself. |
|
@Roasbeef I was not running Neutrino |
Update: every 20 minutes I see a spike to about 1 MB/s. This is probably related to swithcing the active sync peer. |
I'd like to disagree with your assumption. It is a very sudden spike. How can the network activity become 5 times bigger in one hour? And then stay constant? Is this a way (hack) to make nodes using SD-Cards unusable? To break their disks to get their funds? |

|
on my node lnd writing average is steadily over 2MiB/sec. I have no historic data because I started monitoring it today after seeing this issue, but it seems to me that it has always been this way.
|

|
I just got another repro after 9 days of healthy. Attaching the goroutine profile as @guggero asked. Logs have a lot of channel updates: 10+/second, at one spot going to 134 updates in 1 second
lnd-profile.1.2020-10-18.healthy.log |

|
Possibly related: #4714 Connection issues would create more gossip? |
|
My high write load disappeared again without me doing anything or any increase or decrease in channel number, peers, firewall throughput. Strange... |
|
The reason was increased channel update gossip on the network. It has now gone back to more normal levels, which should result in less IO. |
|
Is there a need to persist every channel update gossip? It seems that they are overwriting the same spot on disk. Flushing memory periodically would make the the I/O usage constant - not vulnerable to gossip elevations. |
Please help me understand this. I'm new to this. Do we know what has caused the increase? Has someone with bad intentions flooded the network with these messages? Or does that occur naturally? I mean this could do harm to hardware especially if you use a PI with SD Cards as a hard disk. |

We have more gossip throttling planned, but I don't think that would change the ratio much ultimately. Access pattern wise, lnd will write more than it reads since most reads occur due to RPC calls or on start up. |
|
What causes it to be necessary to persist every gossip update to disk? (sorry, it's a noob question. i'll start reading the book - i promise) |
It is not, we are working on better filtering of uninteresting gossip. Will track this in #4724. Thank you all for the reports and feedback that got us to the bottom of this! ❤️ |
|
I know a solution is in the works, but just reinforcing this issue one last time. With a brand new lnd wallet and no channels open, my desktop pc nearly grinds to a halt from disk i/o from channel updates. It is an older pc so others probably handle it better, but lnd is basically unusable for me currently. Love lnd though - thank you! |
|
Hey guys, as of 12 hours ago, this issue started happening again in most of my nodes, not sure if everyone is experiencing the same |
Background
LND is constantly writing around 500 kb/s onto its volume while only reading 0,5kB/s. LND has 51 peers and 48 channels with about 8 forwarding events per day. I wonder what it is constantly writing. I fear that this write load already wore off my previously used and meanwhile broken sd card.
Your environment
lnd version 0.11.1-beta.rc5 commit=v0.11.1-beta.rc5
Linux odroid 4.14.180-176 #1 SMP PREEMPT Tue May 19 00:40:55 -03 2020 armv7l armv7l armv7l GNU/Linux
Bitcoin Core Daemon version v0.17.1
Steps to reproduce
I am happy to provide you any helpful information, please tell me what you need to investigate this.
Expected behaviour
I would expect LND to rarely write to the file system unless channel states changed.
Actual behaviour
dm-0 is the bitcoin blockchain volume and dm-1 is the lnd volume. Both are on sda.
$ iostat 8 avg-cpu: %user %nice %system %iowait %steal %idle 3,27 0,00 3,39 13,81 0,00 79,54 Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn sda 157,25 382,00 531,00 3056 4248 dm-0 9,12 382,00 0,00 3056 0 dm-1 149,12 0,00 528,00 0 4224The text was updated successfully, but these errors were encountered: