我们说一个topic可以分成多个partition,每一个partition的消息数据都存储在某个broker server的磁盘文件中,但是,当某个partition所在的broker server挂掉了,那么这个partition的消息就不能对外服务了,为了解决这个问题,Kafka设计了ISR机制,其实基本的思想就是将一个partition的数据备份到多个broker server上(和HDFS的Block备份的思想是一样的),这样就可以提高每一个patition的高可用性。
我们先用下面的命令,创建一个topic,名称为kafka-isr,我们设置这个topic为3个分区,每一个分区3个备份
## 在master机器上执行:
cd ~/bigdata/kafka_2.11-1.0.0
## 创建一个名为kafka-isr的topic,分区数是3,每一个分区的备份数设置为3
bin/kafka-topics.sh --create --zookeeper master:2181 --topic kafka-isr --partitions 3 --replication-factor 3执行完上面的命令后,我在在每一台机器上执行下面的命令:
ll /home/hadoop-twq/bigdata/kafka-logs截图如下:
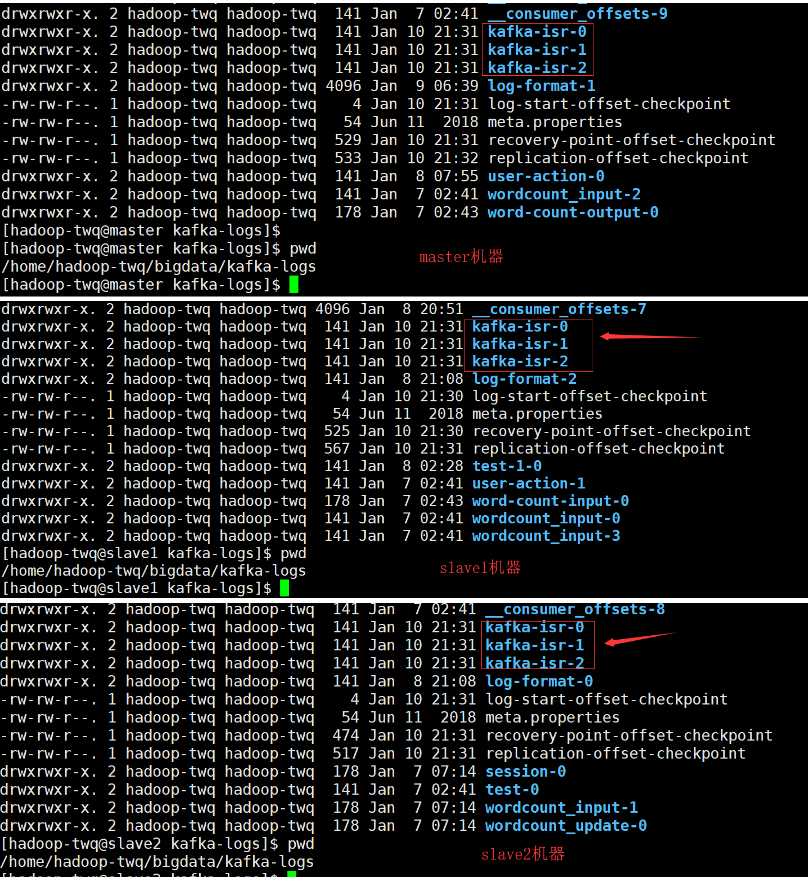
可以看出,3个分区的数据都存储在3个broker server上了,也就是说每一个分区都有3个备份的数据了,他们都是均匀的分布在3个broker server上。
上图中每一个文件目录存储的数据就是每一个分区的每一个备份的数据,里面存储数据的结构和我们在 [partition log file.md](partition log file.md) 中讲解的是一模一样的
我们接下来再使用下面的命令查看下kafka-isr这个topic的信息:
bin/kafka-topics.sh --describe --zookeeper master:2181 --topic kafka-isr输出结果如下:

从上图我们可以看出:
- 这个
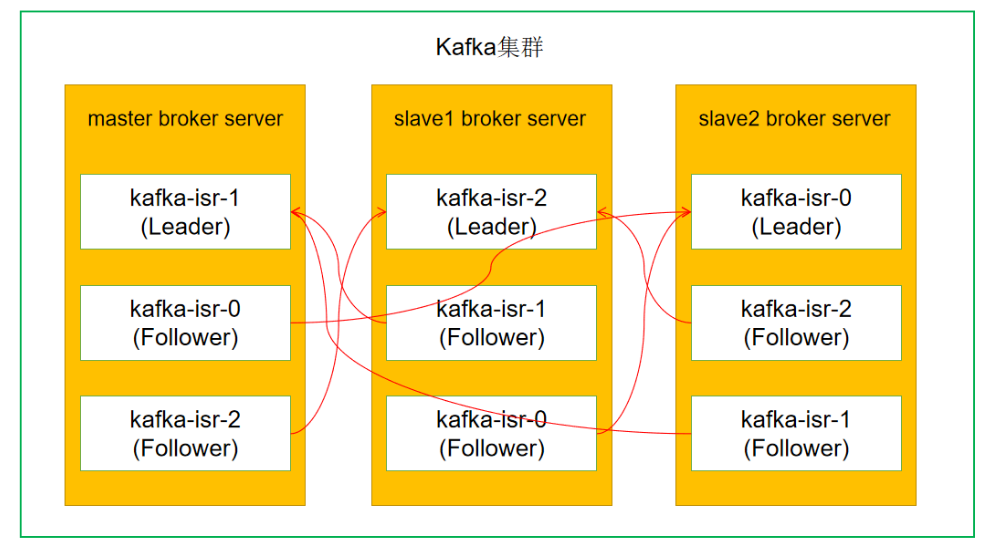
topic有3个分区,每个分区有3个备份(也可以称之为副本) Replicas:是指每一个分区的副本数据存储的broker server id的列表(我们在server.properties中有配置broker.id的),比如分区0的副本数据存储在broker.id等于[2, 0, 1]三个broker server中Leader:是指每一个分区的3个副本的Leader备份。一个分区中的若干个副本中,肯定会有1个Leader副本,0个会多个Follower副本;Leader副本处理分区的所有的读写请求并维护自身以及Follower副本的状态信息,Follower副本作为消费者从Leader副本拉取消息进行同步;当Leader副本失效时,通过分区Leader选举器从Isr列表中选出一个副本作为新的Leader副本Isr:是in sync replicas的缩写,其实,说白了就是一个分区存活的备份列表,那么如果一个备份符合下面的两个要求,则表名它是存活的:- 这个
备份必须和zookeeper保持通讯(通过Zookeeper的心跳机制) - 这个
备份必须正在同步Leader备份的消息,并且不能落后很多
- 这个
- 当一个
备份不符合上面的两个条件,即认为这个备份是死的状态,那么就会从这个ISR列表中移除掉
一定要注意:上图中的
Leader: 2这个2是指broker.id=2,其实就是slave2上的broker server。Replicas以及Isr后面的数字列表也是指broker.id列表
我们再看下下面的图,可能会更清晰点:
我们现在尝试将slave1上的broker server杀掉,命令如下:
# 在slave1上执行
cd /home/hadoop-twq/bigdata/kafka_2.11-1.0.0
bin/kafka-server-stop.sh我们接下来再使用下面的命令查看下kafka-isr这个topic的信息:
bin/kafka-topics.sh --describe --zookeeper master:2181 --topic kafka-isr截图如下:

我们可以看出以下的改变点:
- 所有分区的
Isr的列表中现在只有两个broker server id了,因为slave1上的broker server挂了,即broker.id=1的节点被移除了 - 第三个分区的
Leader副本变成了2了
我们再尝试将slave1上的broker server启动起来,命令如下:
nohup ~/bigdata/kafka_2.11-1.0.0/bin/kafka-server-start.sh ~/bigdata/kafka_2.11-1.0.0/config/server.properties >~/bigdata/kafka_2.11-1.0.0/logs/server.log 2>&1 &我们接下来再使用下面的命令查看下kafka-isr这个topic的信息:
bin/kafka-topics.sh --describe --zookeeper master:2181 --topic kafka-isr截图如下:
 我们可以看出:所有分区的
我们可以看出:所有分区的Isr又恢复了3个broker.id的列表了
如果一个分区至少有一个副本存活的话,那么Kafka可以保证这个分区的消息记录不会丢,但是当整个分区的所有副本所在的broker server都挂了的话,那么,Kafka就不一定能保证消息不丢失了。
当你真的遇到这种情况后,对于你来说,最重要的是要知道接下来会发生什么事情,一般的话有下面两种行为中的一种行为可能会发生:
- 等待在这个分区中的
ISR列表中的副本恢复,然后将这个恢复的副本作为Leader副本(当然是希望所有的数据仍然都在) - 选择第一个副本(不一定是在
ISR列表中的副本)进行恢复,并作为Leader副本
上面两种行为其实是在可用性和一致性之间做的一个取舍平衡,等待ISR列表中的副本恢复作为Leader,可能可以保证数据的一致性(数据不会丢),但是需要时间,在等待的过程中,那么这个分区就不可用了;如果直接选择第一个副本进行恢复并作为Leader,不需要时间,这个分区立马可以工作有用,但是数据可能丢失了,因为它不一定在ISR列表中。Kafka默认的是选择第二种策略了,当然我们可以通过配置unclean.leader.election.enable=true来禁用第二种策略了