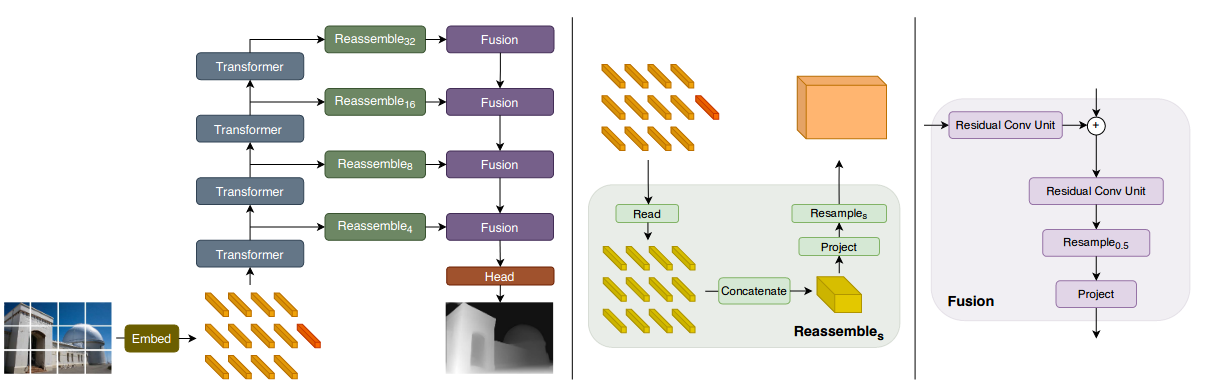
We introduce dense vision transformers, an architecture that leverages vision transformers in place of convolutional networks as a backbone for dense prediction tasks. We assemble tokens from various stages of the vision transformer into image-like representations at various resolutions and progressively combine them into full-resolution predictions using a convolutional decoder. The transformer backbone processes representations at a constant and relatively high resolution and has a global receptive field at every stage. These properties allow the dense vision transformer to provide finer-grained and more globally coherent predictions when compared to fully-convolutional networks. Our experiments show that this architecture yields substantial improvements on dense prediction tasks, especially when a large amount of training data is available. For monocular depth estimation, we observe an improvement of up to 28% in relative performance when compared to a state-of-the-art fully-convolutional network. When applied to semantic segmentation, dense vision transformers set a new state of the art on ADE20K with 49.02% mIoU. We further show that the architecture can be fine-tuned on smaller datasets such as NYUv2, KITTI, and Pascal Context where it also sets the new state of the art. Our models are available at this https URL.
To use other repositories' pre-trained models, it is necessary to convert keys.
We provide a script vit2mmseg.py in the tools directory to convert the key of models from timm to MMSegmentation style.
python tools/model_converters/vit2mmseg.py ${PRETRAIN_PATH} ${STORE_PATH}E.g.
python tools/model_converters/vit2mmseg.py https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_p16_224-80ecf9dd.pth pretrain/jx_vit_base_p16_224-80ecf9dd.pthThis script convert model from PRETRAIN_PATH and store the converted model in STORE_PATH.
| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | Device | mIoU | mIoU(ms+flip) | config | download |
|---|---|---|---|---|---|---|---|---|---|---|
| DPT | ViT-B | 512x512 | 160000 | 8.09 | 10.41 | V100 | 46.97 | 48.34 | config | model | log |
@article{dosoViTskiy2020,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={DosoViTskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={arXiv preprint arXiv:2010.11929},
year={2020}
}
@article{Ranftl2021,
author = {Ren\'{e} Ranftl and Alexey Bochkovskiy and Vladlen Koltun},
title = {Vision Transformers for Dense Prediction},
journal = {ArXiv preprint},
year = {2021},
}