notes from 2022-02-01 meeting with Khachik #70
Labels
documentation
Improvements or additions to documentation
Comments
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
notes
sparse quadrature
can different sampling methods per-variable improve the accuracy / efficiency of the surrogate?
here's an example of a sparse sampling method that the authors call "Smolyak sparse grid from the extrema of Chebyshev polynomials (Clenshaw-Curtis quadrature)"
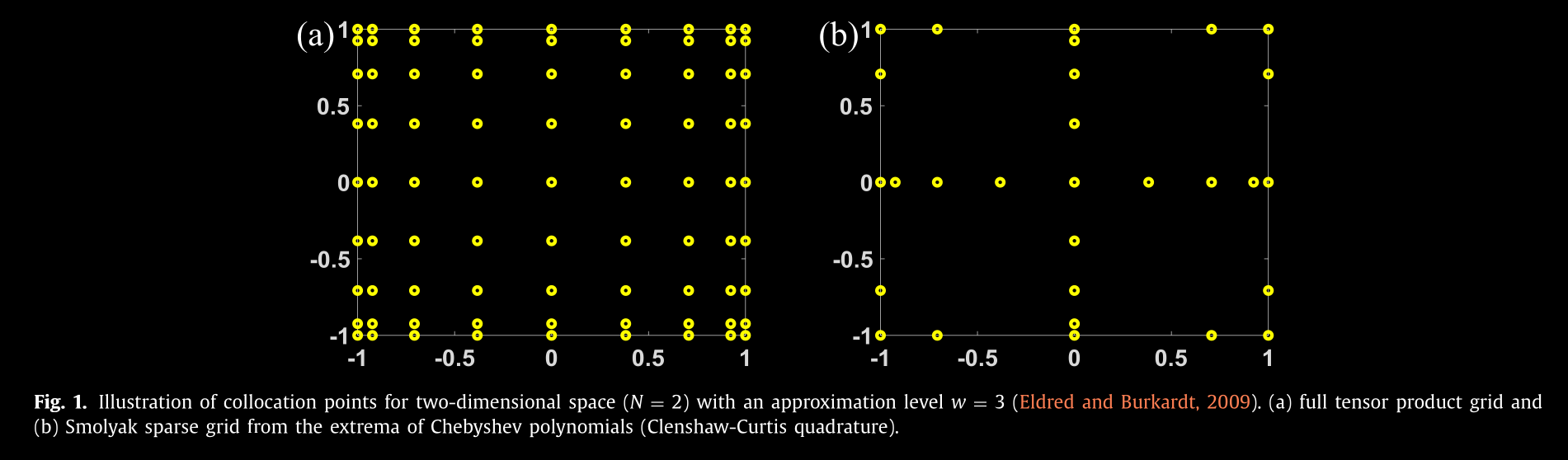
from https://www.sciencedirect.com/science/article/pii/S0098135419310026
methods and constraints
polynomial order / count determination
the number of expanded polynomials
Mcan be found bywhere
Nis the number of variables andPis the highest order.This is equation 5 from https://www.sciencedirect.com/science/article/pii/S0098135419310026:
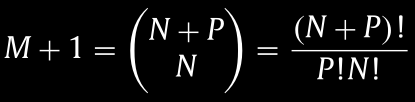
Therefore, a 3rd order polynomial with 4 variables expands to 34 polynomials (plus a zeroth order polynomial)
as a rule of thumb, with an L2 constraint the number of data points
Dshould be approxHowever, Lasso-Type Regularization and Bayesian Compressed Sensing can both fit against a large fraction of polynomials vs data points less than
10 * Mmesh perturbation
next steps
The text was updated successfully, but these errors were encountered: