LiDAR-based or RGB-D-based object detection is used in numerous applications, ranging from autonomous driving to robot vision. Voxel-based 3D convolutional networks have been used for some time to enhance the retention of information when processing point cloud LiDAR data. However, problems remain, including a slow inference speed and low orientation estimation performance. We therefore investigate an improved sparse convolution method for such networks, which significantly increases the speed of both training and inference. We also introduce a new form of angle loss regression to improve the orientation estimation performance and a new data augmentation approach that can enhance the convergence speed and performance. The proposed network produces state-of-the-art results on the KITTI 3D object detection benchmarks while maintaining a fast inference speed.
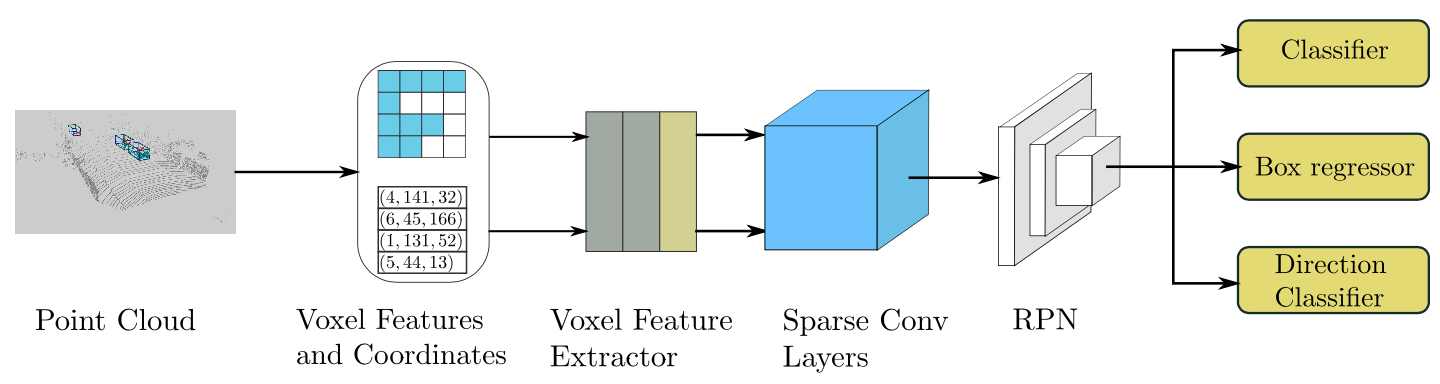
We implement SECOND and provide the results and checkpoints on KITTI dataset.
| Backbone | Class | Lr schd | Mem (GB) | Inf time (fps) | mAP | Download |
|---|---|---|---|---|---|---|
| SECFPN | Car | cyclic 80e | 5.4 | 79.07 | model | log | |
| SECFPN (FP16) | Car | cyclic 80e | 2.9 | 78.72 | model| log | |
| SECFPN | 3 Class | cyclic 80e | 5.4 | 65.74 | model | log | |
| SECFPN (FP16) | 3 Class | cyclic 80e | 2.9 | 67.4 | model | log |
| Backbone | Load Interval | Class | Lr schd | Mem (GB) | Inf time (fps) | mAP@L1 | mAPH@L1 | mAP@L2 | mAPH@L2 | Download |
|---|---|---|---|---|---|---|---|---|---|---|
| SECFPN | 5 | 3 Class | 2x | 8.12 | 65.3 | 61.7 | 58.9 | 55.7 | log | |
| above @ Car | 2x | 8.12 | 67.1 | 66.6 | 58.7 | 58.2 | ||||
| above @ Pedestrian | 2x | 8.12 | 68.1 | 59.1 | 59.5 | 51.5 | ||||
| above @ Cyclist | 2x | 8.12 | 60.7 | 59.5 | 58.4 | 57.3 |
Note:
- See more details about metrics and data split on Waymo HERE. For implementation details, we basically follow the original settings. All of these results are achieved without bells-and-whistles, e.g. ensemble, multi-scale training and test augmentation.
FP16means Mixed Precision (FP16) is adopted in training.
@article{yan2018second,
title={Second: Sparsely embedded convolutional detection},
author={Yan, Yan and Mao, Yuxing and Li, Bo},
journal={Sensors},
year={2018},
publisher={Multidisciplinary Digital Publishing Institute}
}