Resource References
Status: DRAFT
- Summary
- Rationale
- User Stories
- Scope
- Design and Implementation Plan
- Test/Demo Plan
- Unresolved Issues
The paradigm of storing data in the Opal's database appears to be limited when data are becoming very large (billions of rows, millions of variables) or when data are becoming complex (not a simple 2-dimension dataset, but possibly multiple ones, related to each other as in a domain specific database schema). With such big/complex datasets, it makes no sense to copy them in Opal's space. Only the way to access them (authentication may apply), and eventually the way to retrieve metadata (size, timestamps, description, etc.) should be needed.
When it comes to analyse these large data, most likely in a R/DataSHIELD environment, the same limitations apply because the R server computation capabilities may be limited. Therefore it should be possible to describe computation resources as well.
To address these needs, the concept of a "reference to a resource" is introduced in this specification. A resource can be a dataset (e.g. a file stored in the local file system or in a file store server, a database table, etc.) or a server with some computation capabilities (e.g. execution of the plink command through ssh, connection to some secure web services, etc.).
There is already a standard for describing the reference to a resource: Uniform Resource Locator, URL. This standard is flexible and robust enough (the Web is based on that) to define either a data or service resource location.
This will make Opal more generic, from a data repository to a data hub, and will expand DataSHIELD analytic capabilities to large/complex data.
Being able to access big or complex datasets, without facing the limitations of copying data into Opal and of enforcing a domain specific data model into a 2 dimensional one. The ultimate usage that is envisioned is the DataSHIELD context, where resources must be fully available on the server side (to conduct analytics) without disclosing private information to the client side.
Describe simply who is doing what and how to obtain the result.
| # | Who | What | How | Result |
|---|---|---|---|---|
| 1 | data manager | registers a new resource | by filling a form in a project | resource is referenced |
| 2 | data manager | applies permissions on a resource | by selecting the resource, subject type and name and level of permission | access to the resource is restricted |
| 3 | R/DataSHIELD user | assigns a resource to a R/DataSHIELD session | by specifying the project's resource unique name | the resource can be used in the R server to perform analysis |
| 4 | developer | defines a new type of resource, with its form | by developing a resource plugin | new types of resources can be created |
| 5 | R/DataSHIELD developer | makes use of a new type of resource | by developing some R code that extends the concepts associated to the resource | new type of resources can be used to access data or performing computations |
Opal internal database, web services and GUI.
In order to facilitate the creation of a resource URL, a form can be provided to capture the different parts of the URL in a meaningful manner. The type of the form is related to the scheme of the URL and/or of the usage that will be done with this form.
Examples:
| Resource type | URL example |
|---|---|
| File that can be downloaded | https://example.org/path/to/the/file.csv |
| File that can be read locally |
file:/path/to/the/file.csv or file:///path/to/the/file.csv
|
| MySQL database table | mysql://example.org/database/table |
| MongoDB database collection | mongodb://example.org:27017/database/collection |
| Directory where commands can be executed through SSH | ssh://example.org:22/path/to/data/directory?exec=plink,ls |
| File that can be downloaded through SSH | scp://example.org:22/path/to/the/file.csv |
| Application web services that can be triggered | https://app.example.org/ |
| File that can be downloaded from Amazon Web Services S3 file store | s3://bucket/path/to/the/file/object.vcf |
The resource interface is rather minimalistic as it only needs to:
- be uniquely identified at R/DataSHIELD assignment time,
- be convertible into a URL,
- have (optional) credentials when authentication applies.
| Property/Method | Description |
|---|---|
String: name |
Unique name in the project where it is defined |
String: type |
A (optional) type name that can be used by R to interpret the format of the data described by the resource, see Coercing a Resource to a R Object |
Credentials: getCredentials() |
Authentication info, see Credentials |
URL: toURL() |
Get resource as a URL |
Despite it is possible to include in the URL the user info segment in the form of user:password it is strongly not recommended to do this for obvious security reasons. If authentication is required for accessing a resource, the credentials will be stored aside of the URL. Then a DataSHIELD user having a restricted access to the resource, will be able to read the URL but not the associated credentials.
The credentials that are supported are defined by the pair:
| Property | Description |
|---|---|
String: identity |
can be a user name or a account identifier and is optional (because the secret may be used to identify the requester) |
String: secret |
can be a password or a token |
Because several resources can be involved an analysis pipeline (e.g. a computation resource and the files that are to be processed), it should be possible to group some resources, to apply consistent permissions on them and to assign into R this group of resources in one request.
A DataSHIELD user can have permission to see dataset's meta-data (the data dictionary) but not the individual level data.
For a resource, an equivalent permission would be to see the URL of the resource and its meta-data (if there are some, e.g. file size) but not the associated credentials.
| Resource permission | Description |
|---|---|
View meta-data |
Read only permission without access to the resource's credentials (DataSHIELD compliant permission) |
View |
Read only permission without restriction |
Administrate |
Edit and delete permissions |
To use the files stored in the Opal file system, similar permissions need to be applied: see file names, list directory content, but do not download file. Currently a user has all or no permission on a file directory and its content.
| File permission | Description |
|---|---|
View meta-data |
Read only permission without download (DataSHIELD compliant permission) |
View |
Read only permission without restriction |
Administrate |
Edit and delete permissions |
Opal has a plugin architecture that allows to extend some of its features (import/export format for instance). A new type of plugin can be defined, Resource Plugin, which purpose is to declare a new type of resource:
- a form to capture resource parameters in a user-friendly manner
- make a URL from these parameters
- declare the type of the data being described by the resource (if applicable)
- test the accessibility of the resource (if possible): get the meta-data (file size, timestamps etc.) or verify that credentials are valid (database or remote server connection)
Default types that will be provided by Opal:
- local files (special flavor for the ones stored in Opal's file system)
- files accessible via HTTPS
- files accessible via SCP
- database connections (MySQL, MariaDB, PostgreSQL, MongoDB)
- SSH connection
Example of a resource plugin will be based on Amazon Web Services S3 file store.
The Resource Plugin is based on the ResourceService interface that is a factory of Resource objects.
| Method | Description |
|---|---|
JSONObject: getSchemaForm() |
Get the "schema form" object to generate the resource specific form in Opal UI (the concept of schema-form already exists in Opal, see DatasourceService) |
Resource: createResource(name, parameters, credentials) |
Factory method that creates a Resource object, the parameters being the result of the schema-form data capture |
| REST | Description |
|---|---|
GET /resource-plugins |
List the resource plugins |
GET /resource-plugin/{p} |
Get a resource plugin |
GET /resource-plugin/{p}/form |
Get the schema-form of a resource plugin |
| REST | Description |
|---|---|
GET /project/{p}/resources |
List the resources of a project |
POST /project/{p}/resources |
Create a new resource in a project |
GET /project/{p}/resource/{res} |
Get a single resource of a project |
PUT /project/{p}/resource/{res} |
Update a resource of a project |
DELETE /project/{p}/resource/{res} |
Delete a resource of a project |
| REST | Description |
|---|---|
PUT /r/session/{s}/symbol/{smbl}/_resource?name={res} |
Assign a resource object to symbol in the R session |
PUT /datashield/session/{s}/symbol/{smbl}/_resource?name={res} |
Assign a resource object to symbol in the DataSHIELD session |
Resources are defined by project.
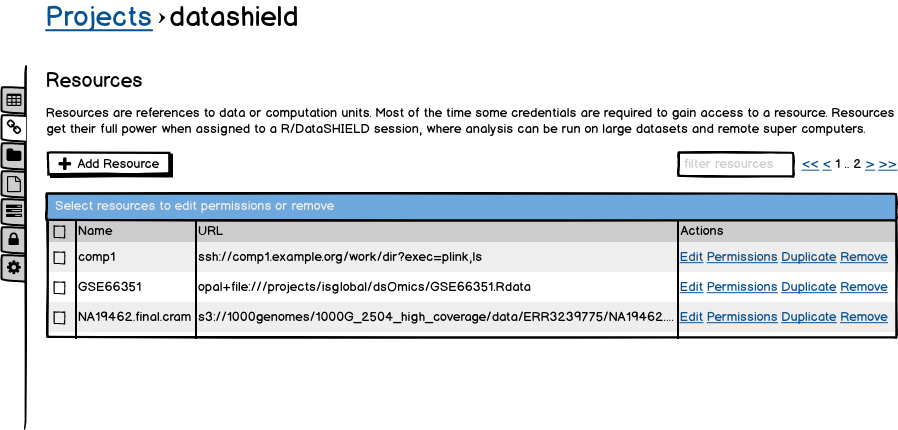
Operations can be performed in batch when selecting several resources.

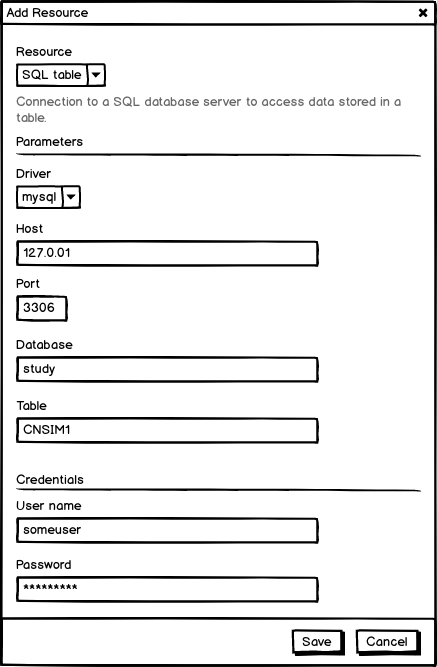
This section describes some R/DataSHIELD use cases and how R code can be structured to formalize the resources and the usage that can be made of it in a flexible way.
When a resource is assigned to a R server session, an object of class resource is created by Opal, with eventually an additional class specification to inform R about the type of the data made accessible by the resource.
res <- structure(
list(
name = "NA19462.final.cram",
url = "s3://1000genomes/1000G_2504_high_coverage/data/ERR3239775/NA19462.final.cram",
identity = "awsaccountid",
secret = "awssecret"
),
class = c("resource", "cram")
)This resource object has all the information for establishing a connection and for making use of the resource.
When relevant it may be possible to coerce the resource to a domain specific R object. This can be achieved by using the S3 class system, usually applied through the extension of as.*() functions.
For instance if the resource represents a SQL table, it should be possible to make a data.frame over it by calling as.data.frame() function.
# S3 function that coerce from a resource as a data.frame
as.data.frame.resource <- function(res) {
# ...
}
# resource to SQL table in a MySQL database
res <- structure(
list(
name = "CNSIM1",
url = "mysql://db.example.org/datashield/table",
identity = "dbuser",
secret = "dbpassword"
),
class = c("resource", "sqltable")
)
# coerce the resource to a SQL table as a data.frame
as.data.frame(res)Another example could be a resource that describes a file (to be downloaded or read locally) and make a data.frame using one of the readers provided by tidyverse.
The data.frame is a generic type. A resource could also be coerced to a domain specific type, such as a Bioconductor Expression Set in a function as.ExpressionSet().
A resource does not necessarily represent data. It can also represent a shell command or an application with web services.
For example, a omic analysis is using the plink command to delegate data computation. This command can be launched locally if the plink command exists locally and if the input file(s) are also available locally. In which case the plink resource could be declared as:
shell:/work/dir?exec=plink,bcftools,ls
Or another case would be that the plink command is to be issued through ssh, then the URL becomes:
ssh://example.org:22/work/dir?exec=plink,bcftools,ls
Whether plink is run locally or remotely affects the way the input file are handled (downloaded or accessed locally).
In the case of a remote web server exposing web services, dedicated client must exists in the R server in order to know how to authenticate and how to get data or execute some tasks. In some situation, the scheme of the URL could be expanded to qualify the application. For instance, the URL is the location of a CSV file in a Opal file system:
https://opal-demo.obiba.org/ws/files/data/sample.csv
Then the R object class would be csv because we want to be able to coerce the CSV file to a data.frame, but how to use the credentials if we don't know that this remote server is Opal? The solution could be to qualify the type of the application in the scheme, for instance:
opal+https://opal-demo.obiba.org/ws/files/data/sample.csv.
We then need to have in R two types of resolver:
- data format resolver, for driving the data transformations,
- URL scheme resolver, for driving the data retrieval.
The data format resolver will make use of the S3 method dispatch system, like with the as.*() functions.
The scheme resolvers could be managed by a resolver registry. This registry and the resolvers could be implemented as R6 classes and defined in a resourcer package.
Let's call ResourceResolver the R6 base class which public functions would be:
| ResourceResolver Function | Description |
|---|---|
isFor(x) |
Test whether the resource x can be handled by the resolver (function used by the resolver registry to find which one applies) |
newClient(x) |
Create a ResourceClient object from the resource x
|
The ResourceResolver is a factory of ResourceClient:
| ResourceClient Function | Description |
|---|---|
getResource() |
Get the resource |
downloadFile(fileext = "") |
From the resource, get the data from the URL into a file with provided file extension |
asDataFrame(...) |
Coerce the resource to a data frame |
getConnection() |
Get the raw connection object that is wrapped. It can be a connection to a file, a database or a remote application |
close() |
Close the connection with the resource |
This base class is to be inherited by specialized resource resolver implementations: OpalResolver for instance will download a file from the Opal file system, or could directly produce a data frame from a table or from the downloaded file, or could return a opal client object using the opalr package.
The resourcer package will also expose some functions:
| resourcer package Function | Description |
|---|---|
newResource(name, url, identity, secret, class) |
Create a structure object which main class attribute is "resource" |
registerResolver(x) |
Register a Resolver object (create the registry object if it does not exists) |
resolveResource(x) |
Find the Resolver object in the registry that is for the resource object x
|
Example of usage, that turns a remote file stored in an application to a data.frame:
# make a data.frame from a resource
# (this section is to be defined in the resourcer package)
as.data.frame.resource <- function(x, row.names = NULL, optional = FALSE, ...) {
# find scheme resolver
resolver <- resourcer::resolveResource(x)
if (is.null(resolver)) {
stop("No resource resolver found for ", x$url)
}
# coerce resource data to a data.frame
client <- resolver$newClient(x)
df <- client$asDataFrame(row.names = row.names, optional = optional, ...)
client$close()
df
}
# register a opal resolver
# (this section is to be done automatically when the package containing
# the OpalResolver class is loaded)
resourcer::registerResolver(OpalResolver$new()) # opal+https
# other resolvers
resourcer::registerResolver(SshResolver$new()) # ssh or scp
resourcer::registerResolver(LocalFileResolver$new()) # file
resourcer::registerResolver(SqlTableResolver$new()) # mysql, mariadb or postgre
resourcer::registerResolver(S3Resolver$new()) # s3
# etc.
# make a csv file resource on a opal server
# (this section is to be done by opal at resource assignment time)
res <- resourcer::newResource(
name = "CNSIM1",
url = "opal+https://opal-demo.obiba.org/ws/files/data/CNSIM1.csv",
identity = NULL,
secret = "WTxCVpOy3dbNYwQbEAzQrPV2KZQFeQCa",
class = "csv"
)
# coerce the csv file in the opal server to a data.frame
# (this section is a assignment operation triggered by the R client)
df <- as.data.frame(res)Another example of usage, that explicitly use the connection object:
# make an application resource on a ssh server
# (this section is to be done by opal at resource assignment time)
res <- resourcer::newResource(
name = "supercomp1",
url = "ssh://server1.example.org/work/dir",
identity = "sshaccountid",
secret = "sshaccountpwd",
class = NULL
)
# get ssh client from resource object
resolver <- SshResolver$new()
client <- resolver$newClient(res) # does a ssh::ssh_connect()
# SshClient has some additional functions
files <- client$exec("ls") # exec 'cd /work/dir && ls'
# or use ssh package directly (see examples https://ropensci.org/technotes/2018/06/12/ssh-02/)
session <- client$getConnection()
ssh::ssh_exec_internal(session, command = "ls")
# release connection
client$close() # does ssh::ssh_disconnect(session)Here is a list of R packages that can help in the implementation of some URL scheme resolvers:
| URL Scheme | R Package |
|---|---|
s3 |
aws.s3 |
ssh |
ssh |
scp |
ssh |
mysql |
DBI, RMySQL |
mongodb |
nodbi, mongolite |
https |
httr |
opal+https |
opalr |
| ... | ... |
The httr package has a function for parsing URLs, parse_url(), which can be conveniently used to extract the scheme, host, port, path, query, etc. elements.
How can the feature be tested or demonstrated. It is important to describe this in fairly great details so anyone can perform the demo or test.
This should highlight any issues that should be addressed in further specifications, and not problems with the specification itself; since any specification with problems cannot be approved.