If you would like to experiment with smaller open models yourself, Google Colab offers a T4 GPU for free. (Note that it might not be available all the time as those GPUs might be prempted based on demand and availability.) An example notebook is given here.
Alternatively, below is a list of potential language models we can offer/serve as open alternatives to commercially available services.
Here are 3 popular foundational models we could let you use: Llama 2, Mistral, and Mixtral.
Llama 2 is an umbrella term for a family of LLMs, in particular any combination of:
- Parameters: 7B parameters, 13B, 34B, and 70B.
- Fine tuning data set: programming, chatting, or following instructions.
Separately, there is Mistral, a smaller 7B model, but with extensive training data. It is fast and performs better than the corresponding Llama 2, 7B parameter models in many tasks.
The large alternative to Mistral is Mixtral, with a different architecture totaling 8*7B=56B. Each inference step only uses 7B parameters, which makes inference fast, yet more powerful.
None of the models perform as well as GPT-4, some of them are comparable to GPT-3.5.
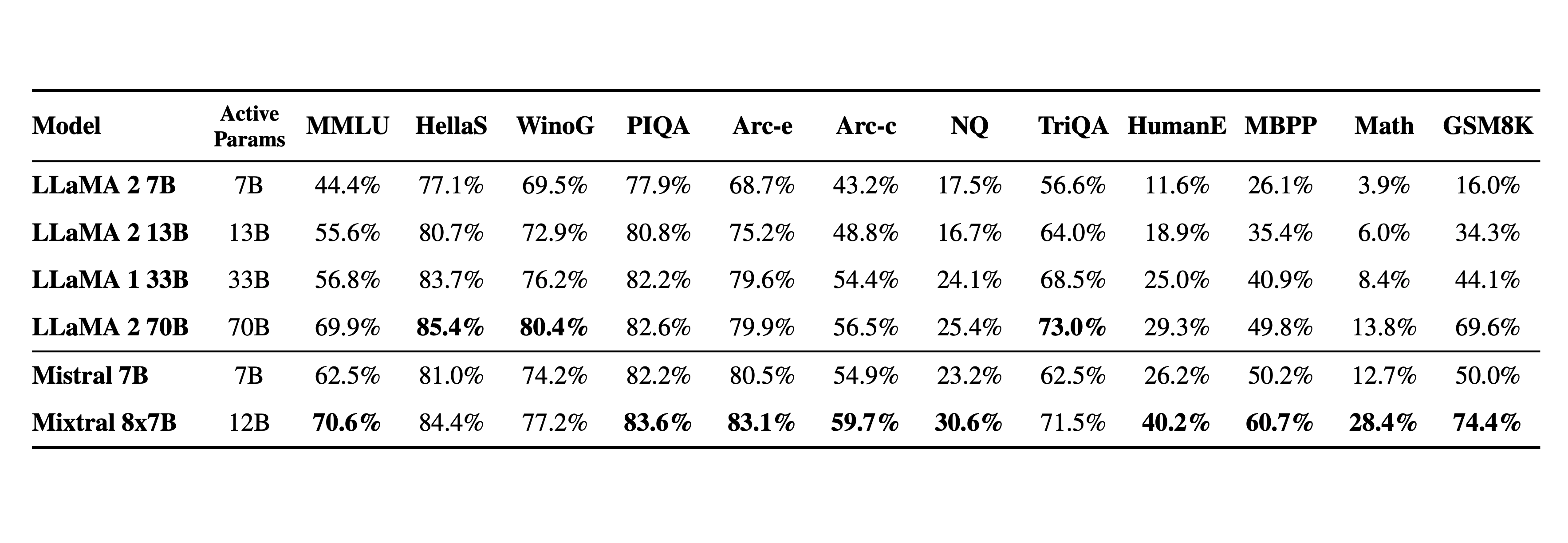
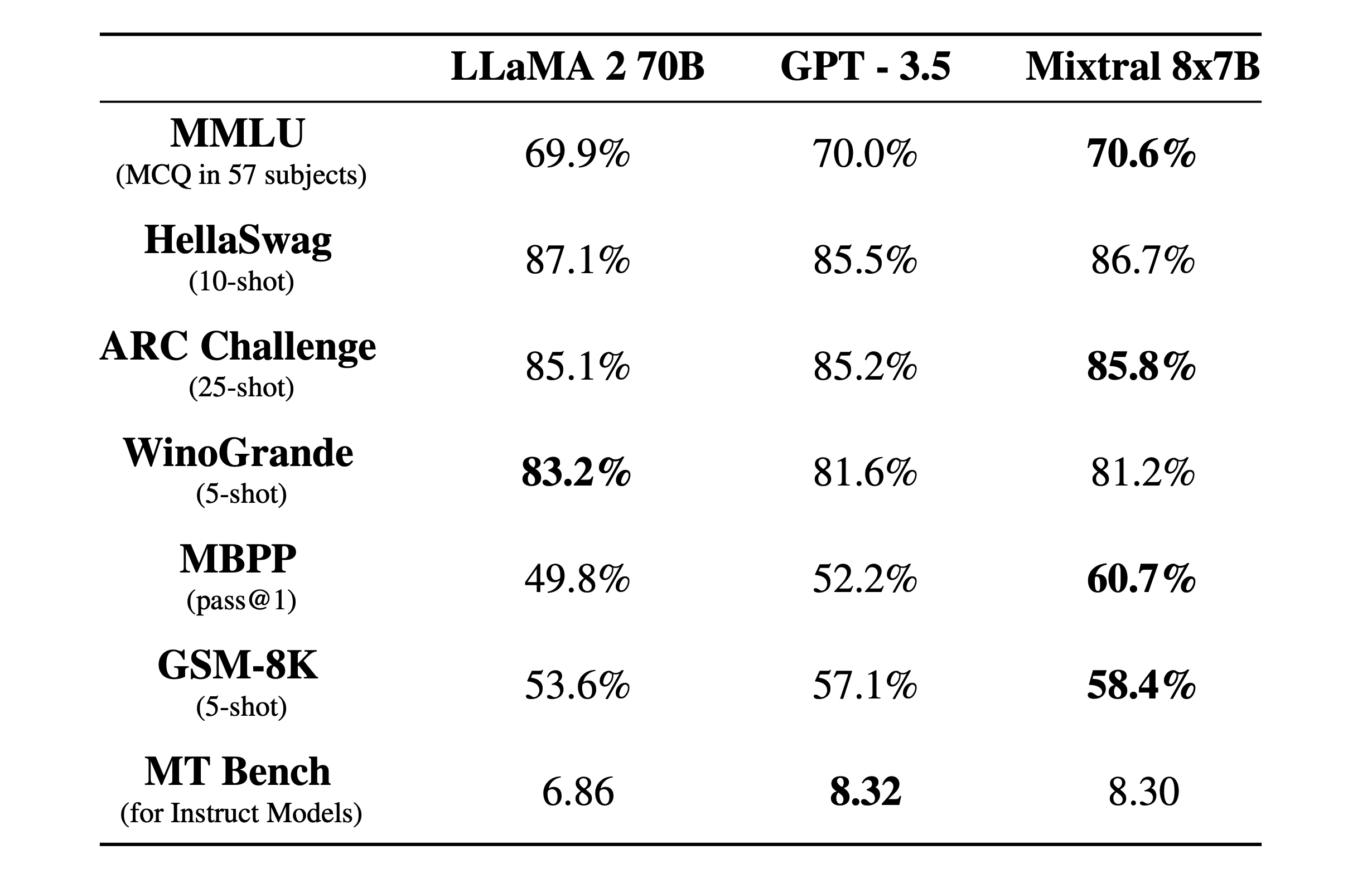
Note: Mixtral and Llama 70B are very large models that need expensive GPUs.
This notebook deploys oobabooga webui. Additionally, it sets up exllamav2 for faster inference and downloads a Llama2-13B model for you. It takes about 20 minutes to deploy on free tier notebooks.