The first question to ask is whether the data is too large to fit on one computer. If so, then Hadoop might be a good idea. If the data will all fit on one computer, then you don't need Hadoop. Just code up a solution without Hadoop.
The second question you need to ask is whether the problems you want to solve are amenable to a MapReduce solution.
Not all questions are. A familiarity with MapReduce design patterns will help you answer this question.
As a side note to this, you should always formulate the questions you want answered or the problems you want solved first.
Only after doing this, should you decide on a particular technology or technique such as Hadoop/MapReduce.
There are at least three ways to improve the index:
- Don't include HTML tags.
- Don't include entries that aren't words. That is, don't include gobbledygook.
- Don't include common English words, such as "a", "the", and so on.
I have implemented a solution that has these improvements:
One interesting question is:
- How long are the response times for a question posted on the forum?
Code [Average response time in minutes to question]
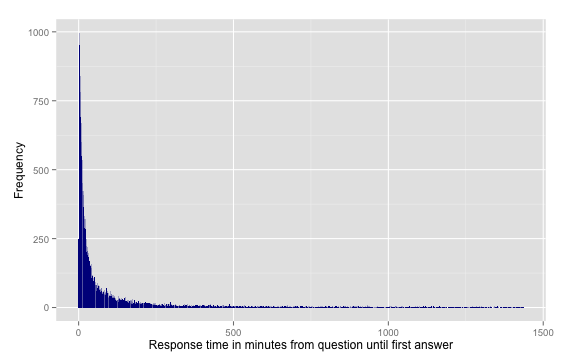
It would be interesting to have visualizations of the data we have obtained through our MapReduce programs. I have written R code to create such visualizations.
The R code is available here:
The generated plots are available here: