| title | author | date | summary | tags | |||
|---|---|---|---|---|---|---|---|
天下武功唯快不破:在线 DDL 性能提升 10 倍 |
|
2023-02-23 |
“天下武功唯快不破”,解决 DDL 带来的问题,本质上只需要做到一点:降低 DDL 的执行耗时。 |
|
随着业务规模和单表容量的增大,DDL 变更这样普遍的运维操作耗时时间越来越长,给 DBA、研发、业务同学都带来了困扰。在 TiDB 6.5 版本中,在线 DDL 的性能提升 10 倍,可以让用户更加快速平稳地执行 DDL 操作,有效地提升业务发展速度。
本文由 PingCAP 架构师和产研团队撰写,介绍 TiDB Fast DDL 的性能实现数量级提升的原理,并给出 TiDB Cloud 与 Aurora、CockroachDB 以及 TiDB 和 OceanBase 的 Online DDL 的性能测试对比报告,欢迎大家试用并反馈。我们将始终如一地迭代演进,期待未来用户执行 DDL 操作像执行简单查询一样淡定坦然。
根据业务需求对表结构进行变更是个普遍的运维操作,常见的 DDL 操作包括给表新增列、或给某些列添加二级索引等。在过去的几年中,我们观察到,当业务规模越来越大,用户的单表容量也越来越大,而单次添加索引的操作耗时越来越长,甚至达到了天级,这种操作潜藏的风险让用户不得不焦躁地反复和研发、DBA 同学沟通确认,严重影响了业务的发展速度。此外,不少用户有同时变更多张表的诉求,排队的 DDL 变更让用户更加担忧。在为用户 case by case 解决了很多 DDL 带来的问题的同时我们也在不断的思考和讨论:集群规模越来越大,云上客户越来越多,究竟应该如何让客户少为 DDL 担忧,能够随时执行 DDL。
“天下武功唯快不破”,解决 DDL 带来的问题,本质上只需要做到一点:降低 DDL 的执行耗时。如果 DDL 可以在指定时间窗口内快速完成,那么 DDL 带来的诸多问题都将迎刃而解。于是我们提出了性能优化先行、兼容性和资源管控跟随的整体解决方案。相比之前版本,TiDB v6.5.0 支持多表 DDL 并行执行、支持 Fast DDL 在线添加索引提速 10x、支持单一 SQL 语句增删改多个列或索引、并支持轻量级 MDL 元数据锁彻底地解决了 DDL 变更过程中 DML 可能遇到的 information schema is changed 的问题。
接下来我们重点介绍 TiDB 的 Fast DDL 是如何实现在线添加索引的性能提升 10 倍的。我们通过分析发现,原生 Online DDL 方案中处理最慢的地方是扫描全表创建索引数据的阶段,而创建索引数据的最大性能瓶颈点是按照事务批量回填索引的方式,因此我们考虑从全量数据的索引创建模式、数据传输、并行导入三方面进行改造。
1 转变索引创建模式
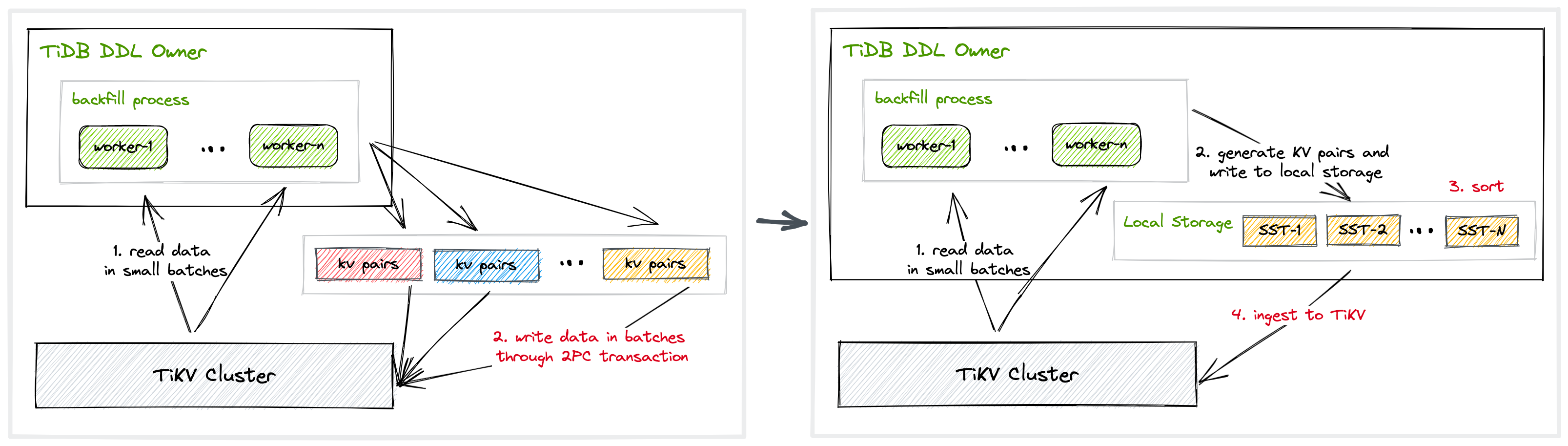
上图左侧展示了原生 Online DDL 方案中,创建索引的流程分为两部分:首先扫描全表数据,之后根据扫描的数据构造索引 KV 对,按照 tidb_ddl_reorg_batch_size 设置的大小分批次以事务方式提交索引记录到 TiKV。该方式存在两方面的性能开销:
- 索引记录在事务两阶段提交的时间开销:因为每个索引事务提交的数据 batch-size 通常在 256 或者更小,当索引记录比较多的时候,索引以事务方式提交回 TiKV 的总事务提交时间是非常可观的。
- 索引事务和用户事务提交冲突时回滚和重试的开销:原生方案在索引记录回填阶段采用事务方式提交数据,当该方式提交的索引记录与用户业务提交的索引记录存在冲突更新时,将触发用户事务或者索引回填事务回滚和重试,从而影响性能。
我们将原生方式中事务批量写入模式改进为文件批量导入的模式,如上图右侧所示:首先仍是扫描全表数据,之后根据扫描的数据构造索引 KV 对并存入 TiDB 的本地存储,在 TiDB 对于 KV 进行排序后,最终以 Ingest 方式将索引记录写入 TiKV。新方案消除了两阶段事务的提交时间开销以及索引回填事务与用户事务提交冲突回滚的开销。
2 优化数据传输
针对索引创建阶段的数据传输,我们做了极致的优化:原生方案中我们需要将每一行表记录返回到 TiDB,选出其中的索引需要的列,构造成为索引的 KV;新方案中,在 TiKV 层返回数据回 TiDB 之前我们先将索引需要的列取出,只返回创建索引真正需要的列,极大的降低了数据传输的总量,从而减少了整体创建索引的总时间。
3 实现并行导入
最后,我们通过并行导入的方式将索引记录以 Ingest 方式导入到 TiKV,并行导入提升了数据写回 TiKV 的效率,但同时也给 TiKV 在线处理负载带来了一定压力。我们正在研发系列流控手段,让并行导入能够既充分利用 TiKV 的空闲带宽,同时不给 TiKV 正常处理负载带来过大压力。
TiDB v6.5.0 版本上默认开启了 Fast DDL 功能,我们可以通过参数开启或者关闭该功能,开启该功能之后可以通过参数 tidb_ddl_reorg_worker_cnt 控制并发度从而控制 DDL 的速度; TiDB On-Premise 的集群则允许用户灵活调整系统参数 tidb_ddl_disk_quota 和 TiDB 的配置文件参数 --temp-dir 来控制存储临时文件空间的大小,从而进一步控制 DDL 的速度;TiDB Cloud 集群则已经是云上最优配置。
| 参数 | Scope | Type | Default | Description |
|---|---|---|---|---|
tidb_ddl_enable_fast_reorg |
GLOBAL | Boolean | ON |
控制是否开启添加索引加速功能,来提升创建索引回填过程的速度。 |
tidb_ddl_reorg_worker_cnt |
GLOBAL | Integer | 4 | 设置 DDL 操作 re-organize 阶段的并发度。 |
tidb_ddl_disk_quota |
GLOBAL | Interger | 107374182400 | 控制创建索引回填过程中使用到的本地存储空间大小,默认为 100 GB。 |
以 Sysbench 基准测试为例,在最常见的创建索引场景下,我们对比了 TiDB v6.1.0、Aurora、CockroachDB v22.2、TiDB v6.5.0 在云上费用相近时,不同数据量的表在 INT 数据类型的字段 k 上创建二级索引时 DDL 执行效率的提升比例。
| 数据库 | 版本 | 集群配置 | 费用 ( $/hour ) |
|---|---|---|---|
| TiDB | v6.1.0 / v6.5.0 | TiDB: ( 16c Core + 32GB ) * 2 ;TiKV: ( 16c Core + 64GB + 1TB) * 9 | 21.32 |
| Aurora | v3.02.2 | db.r5.8xlarge * 2 | 21 |
| CockroachDB | v22.2 | ( 16c Core + 60GB + 1TB ) * 6 | 21.17 |
- 空闲负载时,TiDB v6.5.0 在线加索引性能约是 TiDB v6.1.0 LTS 版本的 10 倍,CockroachDB v22.2 的 3 倍,Aurora 的 2.7 倍。
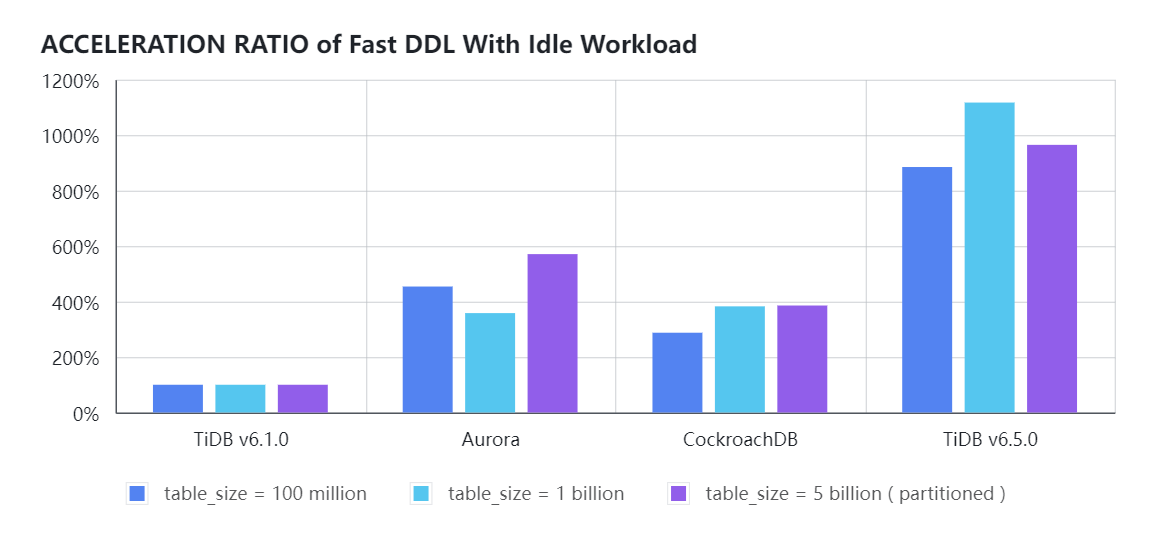
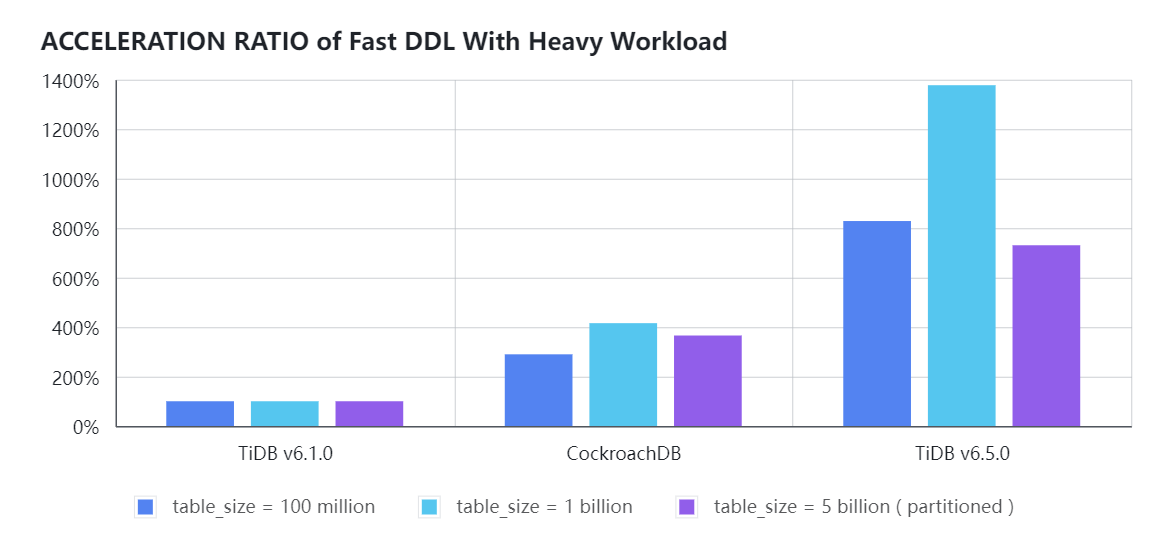
- Sysbench OLTP_READ_WRITE 负载模式,集群 QPS 约 10K时,TiDB v6.5.0 在线添加索引的性能约是 TiDB v6.1.0 LTS 版本的 8 ~ 13 倍, CockroachDB v22.2 的 3 倍;考虑到 Aurora 在线 DDL 会自动强制终止只读实例上的相关查询,多数客户通常使用 gh-ost / pt-osc / osc 在 Aurora 做 Schema 变更操作,因此就不再和 Aurora 对比带负载的性能测试结果。
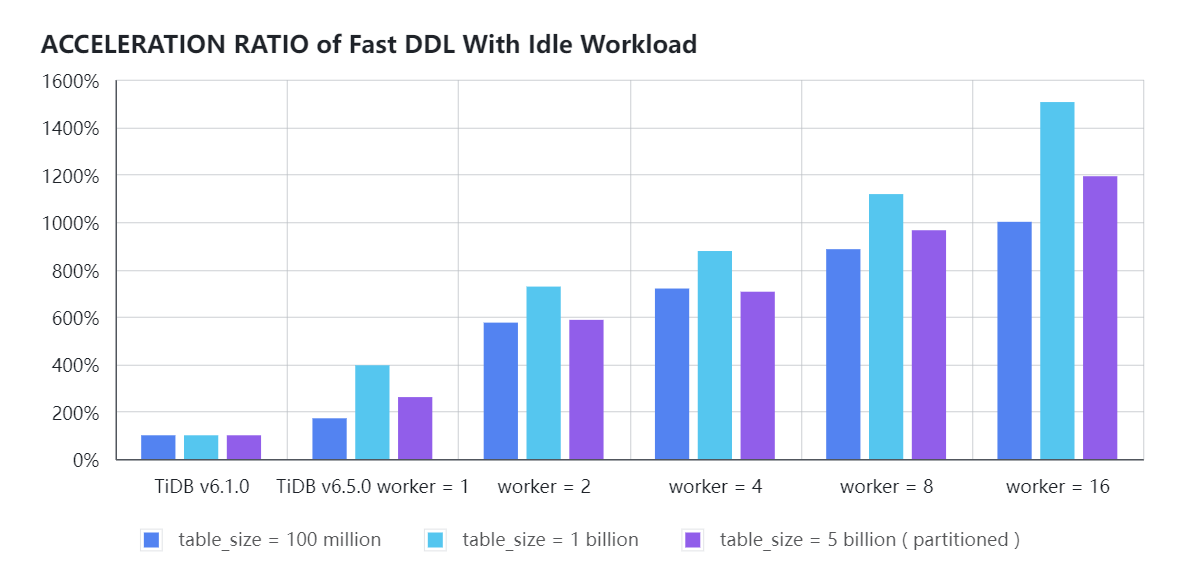
- 空闲负载时,并行参数
tidb_ddl_reorg_worker_cnt参数分别设置为 1、2、4、8 和 16 时,TiDB 在不同数据量的表中开启 FAST DDL 时在线添加索引的性能提升比例如下图所示:
仍以Sysbench 基准测试为例,在相同物理配置的集群上,我们对比了 TiDB 和 OceanBase 两款数据库最新版本下,不同数据量的表在 INT 数据类型的字段 k 上创建二级索引时 DDL 执行效率。
| 数据库 | 版本 | 集群配置 |
|---|---|---|
| TiDB | v6.5.0 | ( 18 Core 2.60GHz *2, 512 GB Mem, 3.84 TB NVME * 2 ) * 3;部署模式:TiDB、TiKV、PD 混合部署,NUMA 绑定 |
| OceanBase | 4.0 CE | ( 18 Core 2.60GHz *2, 512 GB Mem, 3.84 TB NVME * 2 ) * 3;部署模式:Clog 和 Data 使用各自独立的 NVME 磁盘,租户配置 69 个 CPU,210GB 内存 |
OceanBase 可以通过 /*+ PARALLEL(N) */ 来控制创建索引的并发度:
-- OceanBase 使用并发度3在线创建索引
CREATE /*+ PARALLEL(3) */ INDEX k_1 ON sbtest.sbtest1(k);如前文所述,TiDB 则可以通过 tidb_ddl_reorg_worker_cnt 参数来控制 DDL 的并发度:
-- TiDB 调整 DDL 操作的并发度为3
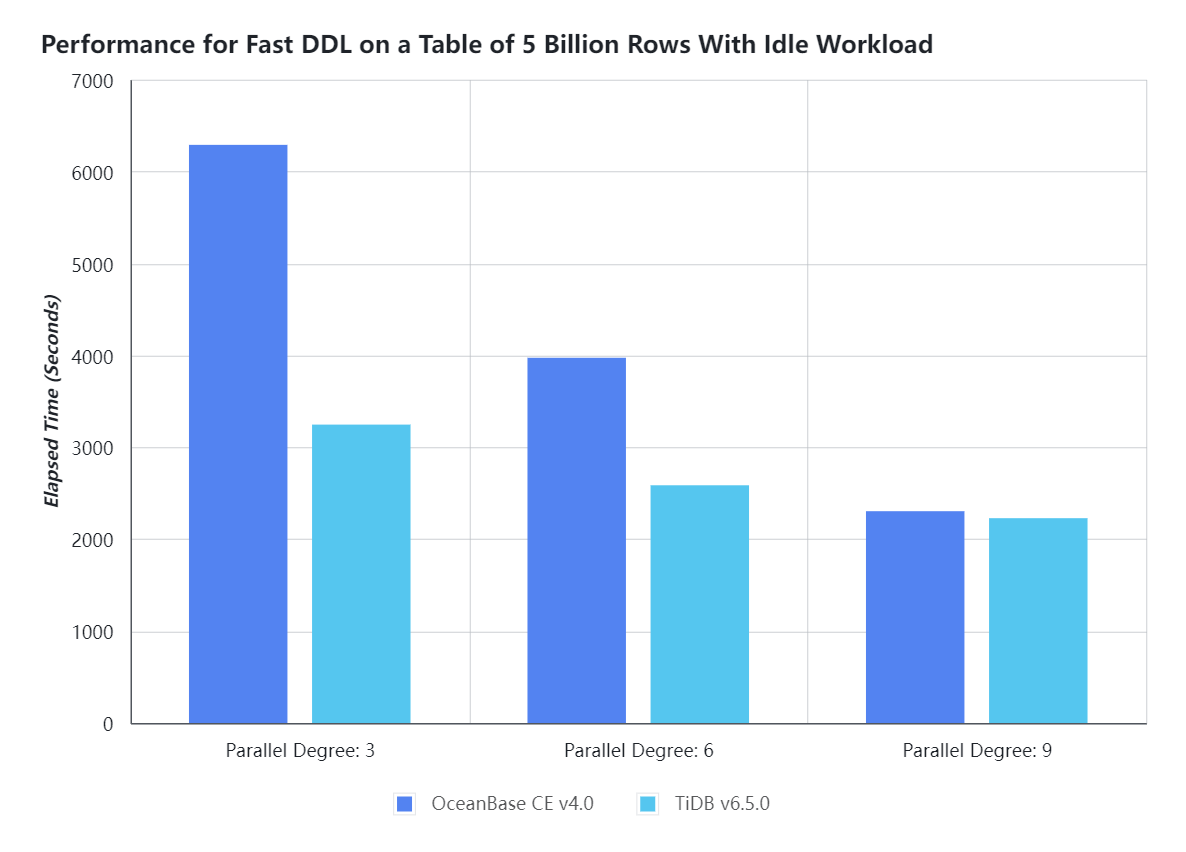
SET GLOBAL tidb_ddl_reorg_worker_cnt=3;- 空闲负载时,采用相同的并发度(分别设置并发度为 3、6、9 )在线添加索引,TiDB 需要的时间明显少于 OceanBase,尤其是在 OceanBase 默认并发度 3 时,TiDB 比 OceanBase 快将近 1 倍。
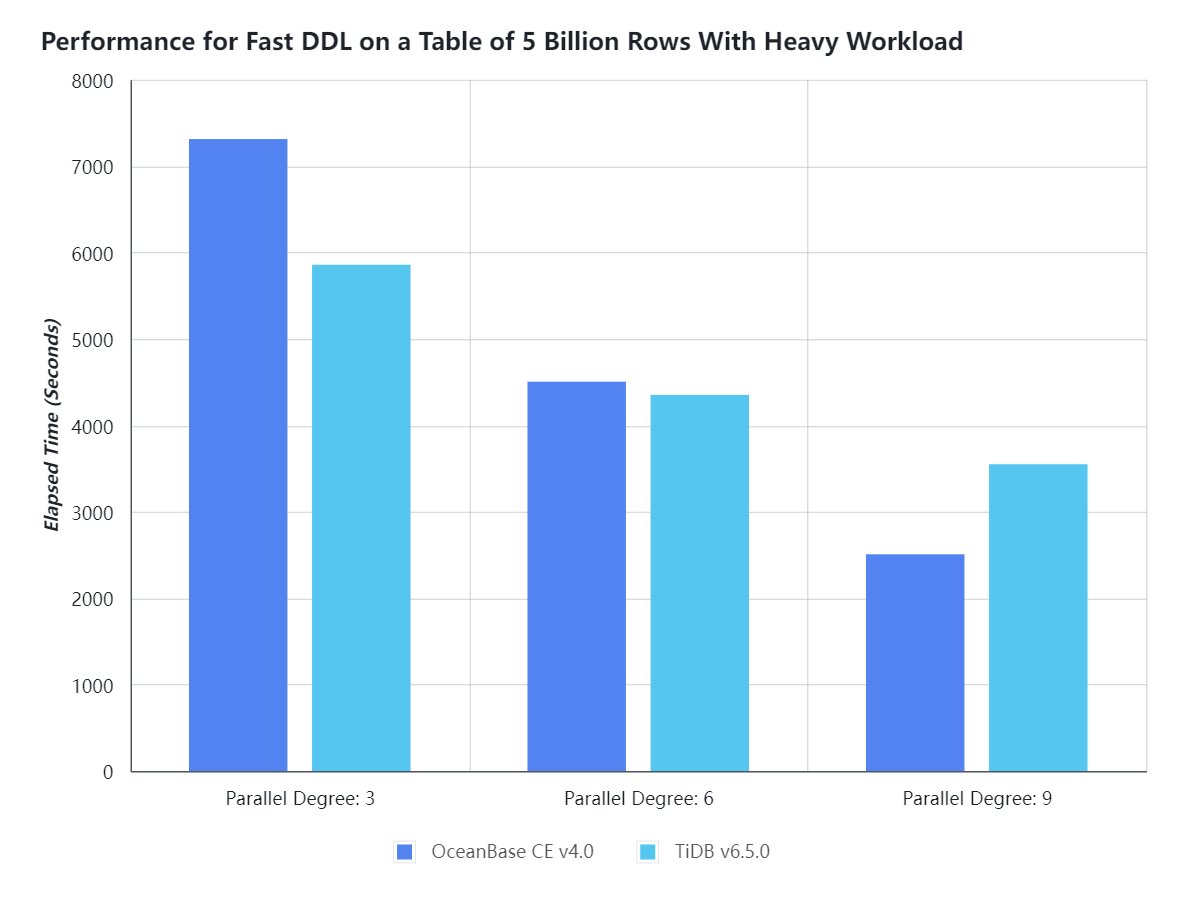
- Sysbench OLTP_READ_WRITE 负载模式,集群 QPS 约 60K,采用相同的并发度(分别设置并发度为 3、6、9 )在线添加索引,TiDB 和 OceanBase 的在线加索引耗时基本持平,互有优势:OceanBase 默认并发度配置下,TiDB 加索引速度略快;随着并发度的提升,OceanBase 的 DDL 速度提升略快。
TiDB 的 Fast DDL 当前仍存在如下 3 点限制,我们预计在 2023 年末发布的 LTS 版本解除这部分限制:
- 目前 Fast DDL 功能仅支持支持创建二级索引操作。
- 多表同时并行执行 DDL 任务时,考虑到并发的资源限制,仅有 1 个 DDL 任务启用 Fast DDL。
- 当前 Fast DDL 功能与 PITR (Point-in-time recovery) 功能不兼容,在使用 Fast DDL 功能时,需要手动做一次全量备份任务,确保 PITR 的备份基础数据的完整。
DDL 操作是数据库管理操作中最繁重的一种,而性能优化先行、资源管控跟随的整体解决方案能够切实解决 DDL 的繁重弊端。下个 LTS 版本的在线 DDL 的性能将 v6.5.0 基础上再提升一个数量级,并覆盖更多的 DDL 操作;结合资源管控和 TiDB Cloud 云上的弹性伸缩能力,TiDB Cloud 将提供更加全面、弹性、平滑、高速的多表并行 Fast DDL。相信经过未来若干版本的迭代,未来用户执行 DDL 操作可以像执行简单查询一样淡定坦然。欢迎各位和我们一起开启新的奇妙旅程。