: 데이터는 컴퓨터 디스크와 같은 매체에 저장된 사실을 말한다. 정보는 데이터를 처리해서 사람이 이해하기에 적합한 형태로 의미있게 만든 것이다.
: 정보와 데이터 사이의 갭을 줄이는 것
: 조직체의 응용 시스템들이 공유해서 사용하는 운용데이터들을 구조적으로 통합된 것. 데이터베이스의 구조는 사용되는 데이터 모델에 의해서 결정된다.
- 데이터의 대규모 저장소로서, 여러 부서에 속하는 여러 사용자에 의해 동시에 사용된다.
- 모든 데이터가 중복을 최소화하면서 통합된다.
- 한 조직체의 운영 데이터뿐만 아니라 그 데이터에 관한 설명(데이테베이스 스키마 or 메타데이터)까지 포함
- 데이터의 구조가 프로그램과 분리되어 데이터베이스에 저장되므로 프로그램과 데이터 간의 독립성 제공
- 효율적 접근이 가능하다.
: 데이터베이스를 정의하고, query를 지원하고, 리포터를 생성하는 등의 작업을 수행하는 소프트웨어.
- 데이터베이스 스키마는 전체적인 데이터베이스 구조를 뜻하며 자주 변경되지않는다. 또한 데이터베이스의 모든 가능한 상태를 미리 정의. **intension(내포)**라고 부른다.
- 데이터베이스 상태(state)는 특정 시점의 데이터베이스 내용을 의미하며, 시간이 지남에 따라 계속해서 바뀐다. **extension(외연)**이라 부른다.
- 데이터 독립성
- 융통성
- 효율적인 데이터접근
- 데이터에 대한 동시 접근
- 백업과 회복
- 중복을 줄이거나 제어해 일관성 유지
- 데이터 무결성
- 데이터 보안
- 쉬운 질의어(query)
- 다양한 사용자 인터페이스 제공
: 화일시스템은 DBMS가 등장하기 전부터 사용되어 왔다. 화일은 순차적인 레코드들로 구성되어있다. 화일을 접근하는 방식이 응용프로그램 내에 상세하게 표현되어 데이터에 대한 응용프로그램 의존도가 높다.
- 구입비용을 지출하지 않고도 사용할 수 있으며 속도가 빠르다.
: 데이터의 정의가 프로그램에 내포되어있고, 프로그램에서 데이터를 접근 하고 조작하는 것외에 별도의 제어가 없음.
- 데이터가 많은 화일에 중복해서 저장
- 다수 사용자들을 위한 동시성 제어 제공되지 않음
- query(질의어)가 제공되지 않음.
- 보안조치 미흡
- 회복기능이 없다.
- 프로그램-데이터의 독립성이 없어 유지보수비용이 크다.
- 데이터 모델링 개념 부족
- 무결성을 유지하기 어려움
- 프로그래머의 생산성이 낮다.
- 융통성이 부족
- 중복성과 불일치가 감소
- 사용자에게 보다 나은 서비스 제공
- 프로그램-데이터 독립성이 향상
- 개발과 유지보수 비용이 감소
- 표준화를 시행히기가 용이
- 보안 향상
- 무결성 향상
- 데이터베이스 회복
- 공유 및 동시 접근 가능
- 다양한 도구들 활용할 수 있다.
- 추가적인 하드웨어 구입비용이 들고, 자체의 구입비용도 비쌈
- 다수 사용자가 데이터베이스를 접근하기 때문에 비밀과 프라이버시 노출등의 단점 존재.
: 초기 투자비용 너무 클때, 오버헤드 클때, 응용이 단순하고 잘 정의 되어 변경되지않을 것으로 예상될 때, 엄격한 실시간 처리 요구사항이 있을때는 DBMS를 사용하지 않는 것이 바람직 할 수 도 있음.
: 데이터베이스의 구조를 기술하는데 사용되는 개념들의 집합인 구조, 연산자들, 무결성 제약조건들로 이루어진다. 각 데이터 모델은 공통된 목적을 가지고 있다. 데이터에대한 직관적인 뷰를 제공하는 동시에 이들간 사상을 제공 하는것이다.
-
고수준 or 개념적 데이터 모델 : 데이터베이스의 전체적인 논리구조 명시 ex) ER:Entity-Relationship(엔티티-관계) 데이터 모델, 객체지향 데이터 모델
-
표현(구현) 데이터 모델 ex) 계층 데이터 모델, 네트워크 데이터 모델, 관계데이터 모델
-
저수준 or 물리적 데이터 모델 : 시스템이 인식하는 것과 가까움. 데이테베이스에 데이터가 어떻게 저장되는지 기술 ex) Unifying, ISAM,VSAM
일반적으로 데이터베이스 시스템은 적어도 두 개(물리적, 논리적)의 데이터 모델을 갖는다.

- 장점 : 빠른 속도와 높은 효율성
- 단점 : 각각의 관계를 명시적으로 정의되어야 하며, 어떻게 데이터에 접근하는지 응용프로그램에 미리 정의 해야한다. 또한 레코드 구조와 응용프로그램 수정이 어려워 데이터 독립성이 매우 제한된다.
2.네트워크 DBMS
- 단점 : 레코드 구조와 응용프로그램 수정이 어려워 데이터 독립성이 매우 제한된다. 또한 한번에 한개의 레코드를 검색할 수 있다.
3.관계 DBMS
- 장점 : 모델이 간단하여 이해하기 쉽다.
4.객체지향 DBMS
- 장점 : 데이터와 프로그램을 그룹화하고, 복잡한 객체들을 이해하기 쉬우며, 유지보수 용이.
5.객체관계 DBMS

-
데이터 정의어(DDL : Data Definition Language) : DDL을 이용해 데이터베이스 스키마를 정의한다. DDL로 명시된 문장이 입력되면 DBMS는 스키마에 대한 명세를 시스템카탈로그 또는 데이터 사전에 저장한다. 시스템 카탈로그는 메타데이터(데이터에 관한 데이터)를 저장한다.
-
데이터 조작어(DML : Data Manipulation Language) : DML을 사용해 데이터베이스 내의 원하는 데이터를 검색, 수정, 삽입, 삭제한다.
-
데이터 제어어(DCL : Data Control Language) : DCL을 사용해 권한을 부여하거나 취소한다.

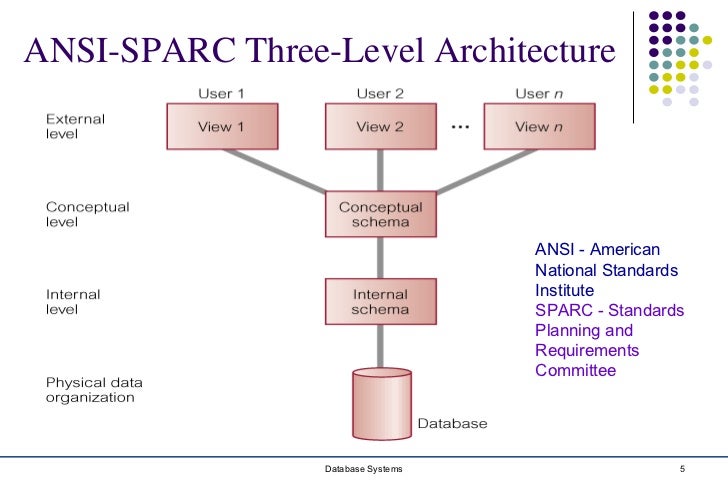
-
외부단계(External level) : 각 사용자의 뷰
외부단계들은 동일한 데이터에 대한 서로 다른 표현들을 제공할 수 있다.
-
개념단계(Conceptual level) : 사용자 공동체의 뷰
데이터베이스에 어떤 데이터가 저장되어 있으며, 데이터간의 관계, 무결성 제약조건들이 명시되어 있는지를 기술. 즉, 전체 데이터베이스의 논리적인 구조를 기술
-
내부단계(Internal level) : 물리적 또는 저장 뷰
데이터베이스에 어떤 데이터가 어떻게 저장되어있는지 기술. 효율성을 가장 중요하게 고려한다.
-
스키마 간의 사상
- 외부 / 개념 사상 : 외부단계의 뷰를 사용해 입력된 사용자 질의를 개념 단계의 스키마를 사용한 질의로 변환
- 개념 / 내부 사상 : 이를 다시 내부 단계 스키마로 변환해 디스크의 데이터베이스에 접근.
-
데이터 독립성 : 상위 단계의 스키마 정의에 영향을 주지 않으면서 스키마 정의를 변경할 수 있음을 의미.
- 논리적 데이터 독립성 : 개념스키마의 변화로부터 외부스키마가 영향으르 받지 않음을 의미
- 물리적 데이터 독립성 : 내부스키마의 변화가 개념적 스키마에 영향을 미치지 않으며, 외부스키마에도 영향을 미치지 않음을 의미.

- 트랙잭션 관리자 : 동시성 제어, 회복
-
중앙 집중식
-
분산식
-
클라이언트-서버 (가장 많이 사용됨.) : 기존의 데이터베이스를 보다 넓은 지역에서 접근할 수 있고, 성능이 향상되며, 하드웨어 비용이 절감된다.


