VLMEvalKit (the python package name is vlmeval) is an open-source evaluation toolkit of large vision-language models (LVLMs). It enables one-command evaluation of LVLMs on various benchmarks, without the heavy workload of data preparation under multiple repositories. In VLMEvalKit, we adopt generation-based evaluation for all LVLMs (obtain the answer via generate / chat interface), and provide the evaluation results obtained with both exact matching and LLM(ChatGPT)-based answer extraction.
- [2024-02-07] We have supported two new models: MiniCPM-V and OmniLMM-12B. 🔥🔥🔥
- [2024-01-30] We have supported three new models: QwenVLMax, InternLM-XComposer2-7B, MMAlaya. 🔥🔥🔥
- [2024-01-30] We have merged all performance numbers on our leaderboards into a single json file: OpenVLM.json.
- [2024-01-27] We have supported the evaluation of MMMU_TEST. 🔥🔥🔥
- [2024-01-24] We have supported Yi-VL. 🔥🔥🔥
- [2024-01-21] We have updated results for LLaVABench (in-the-wild). 🔥🔥🔥
- [2024-01-14] We have supported AI2D and provided the script for data pre-processing. 🔥🔥🔥
- [2024-01-13] We have supported EMU2 / EMU2-Chat and DocVQA. 🔥🔥🔥
- [2024-01-11] We have supported Monkey / Monkey-Chat. 🔥🔥🔥
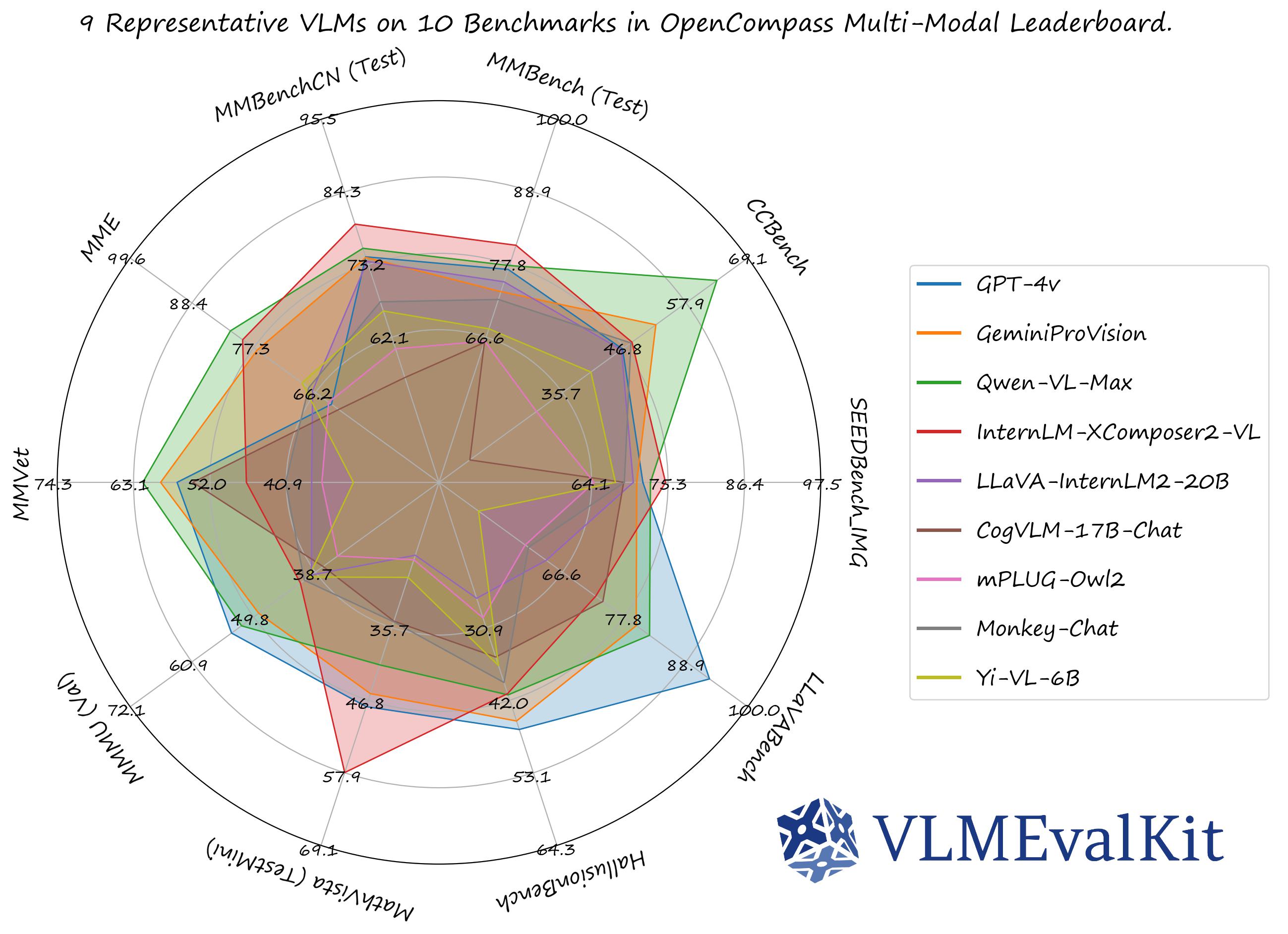
The performance numbers on our official multi-modal leaderboards can be downloaded from here!
OpenCompass Multi-Modal Leaderboard: Download All DETAILED Results.
Supported Dataset
| Dataset | Dataset Names (for run.py) | Inference | Evaluation | Results |
|---|---|---|---|---|
| MMBench Series: MMBench, MMBench-CN, CCBench |
MMBench-DEV-[EN/CN] MMBench-TEST-[EN/CN] CCBench |
✅ | ✅ | MMBench Series |
| MME | MME | ✅ | ✅ | MME |
| SEEDBench_IMG | SEEDBench_IMG | ✅ | ✅ | SEEDBench_IMG |
| MM-Vet | MMVet | ✅ | ✅ | MM-Vet |
| MMMU | MMMU_DEV_VAL/MMMU_TEST | ✅ | ✅ | MMMU |
| MathVista | MathVista_MINI | ✅ | ✅ | MathVista |
| ScienceQA_IMG | ScienceQA_[VAL/TEST] | ✅ | ✅ | ScienceQA |
| COCO Caption | COCO_VAL | ✅ | ✅ | Caption |
| HallusionBench | HallusionBench | ✅ | ✅ | HallusionBench |
| OCRVQA | OCRVQA_[TESTCORE/TEST] | ✅ | ✅ | VQA |
| TextVQA | TextVQA_VAL | ✅ | ✅ | VQA |
| ChartQA | ChartQA_VALTEST_HUMAN | ✅ | ✅ | VQA |
| AI2D | AI2D_TEST | ✅ | ✅ | |
| LLaVABench | LLaVABench | ✅ | ✅ | LLaVABench |
| DocVQA | DocVQA_VAL | ✅ | ✅ | |
| Core-MM | CORE_MM | ✅ |
Supported API Models
| GPT-4-Vision-Preview🎞️🚅 | GeminiProVision🎞️🚅 | QwenVLPlus🎞️🚅 | QwenVLMax🎞️🚅 |
|---|
Supported PyTorch / HF Models
🎞️: Support multiple images as inputs, via the multi_generate / interleave_generate interface.
🚅: Model can be used without any additional configuration / operation.
# Demo
from vlmeval.config import supported_VLM
model = supported_VLM['idefics_9b_instruct']()
# Forward Single Image
ret = model.generate('assets/apple.jpg', 'What is in this image?')
print(ret) # The image features a red apple with a leaf on it.
# Forward Multiple Images
ret = model.multi_generate(['assets/apple.jpg', 'assets/apple.jpg'], 'How many apples are there in the provided images? ')
print(ret) # There are two apples in the provided images.Before running the evaluation script, you need to configure the VLMs and set the model_paths properly.
After that, you can use a single script run.py to inference and evaluate multiple VLMs and benchmarks at a same time.
git clone https://github.com/open-compass/VLMEvalKit.git
cd VLMEvalKit
pip install -e .VLM Configuration: All VLMs are configured in vlmeval/config.py, for some VLMs, you need to configure the code root (MiniGPT-4, PandaGPT, etc.) or the model_weight root (LLaVA-v1-7B, etc.) before conducting the evaluation. During evaluation, you should use the model name specified in supported_VLM in vlmeval/config.py to select the VLM. For MiniGPT-4 and InstructBLIP, you also need to modify the config files in vlmeval/vlm/misc to configure LLM path and ckpt path.
Following VLMs require the configuration step:
Code Preparation & Installation: InstructBLIP (LAVIS), LLaVA (LLaVA), MiniGPT-4 (MiniGPT-4), mPLUG-Owl2 (mPLUG-Owl2), OpenFlamingo-v2 (OpenFlamingo), PandaGPT-13B (PandaGPT), TransCore-M (TransCore-M).
Manual Weight Preparation & Configuration: InstructBLIP, LLaVA-v1-7B, MiniGPT-4, PandaGPT-13B
We use run.py for evaluation. To use the script, you can use $VLMEvalKit/run.py or create a soft-link of the script (to use the script anywhere):
Arguments
--data (list[str]): Set the dataset names that are supported in VLMEvalKit (defined invlmeval/utils/dataset_config.py).--model (list[str]): Set the VLM names that are supported in VLMEvalKit (defined insupported_VLMinvlmeval/config.py).--mode (str, default to 'all', choices are ['all', 'infer']): Whenmodeset to "all", will perform both inference and evaluation; when set to "infer", will only perform the inference.--nproc (int, default to 4): The number of threads for OpenAI API calling.--verbose (bool, store_true)
Command
You can run the script with python or torchrun:
# When running with `python`, only one VLM instance is instantiated, and it might use multiple GPUs (depending on its default behavior).
# That is recommended for evaluating very large VLMs (like IDEFICS-80B-Instruct).
# IDEFICS-80B-Instruct on MMBench_DEV_EN, MME, and SEEDBench_IMG, Inference and Evalution
python run.py --data MMBench_DEV_EN MME SEEDBench_IMG --model idefics_80b_instruct --verbose
# IDEFICS-80B-Instruct on MMBench_DEV_EN, MME, and SEEDBench_IMG, Inference only
python run.py --data MMBench_DEV_EN MME SEEDBench_IMG --model idefics_80b_instruct --verbose --mode infer
# When running with `torchrun`, one VLM instance is instantiated on each GPU. It can speed up the inference.
# However, that is only suitable for VLMs that consume small amounts of GPU memory.
# IDEFICS-9B-Instruct, Qwen-VL-Chat, mPLUG-Owl2 on MMBench_DEV_EN, MME, and SEEDBench_IMG. On a node with 8 GPU. Inference and Evaluation.
torchrun --nproc-per-node=8 run.py --data MMBench_DEV_EN MME SEEDBench_IMG --model idefics_80b_instruct qwen_chat mPLUG-Owl2 --verbose
# Qwen-VL-Chat on MME. On a node with 2 GPU. Inference and Evaluation.
torchrun --nproc-per-node=2 run.py --data MME --model qwen_chat --verboseThe evaluation results will be printed as logs, besides. Result Files will also be generated in the directory $YOUR_WORKING_DIRECTORY/{model_name}. Files ending with .csv contain the evaluated metrics.
To implement a custom benchmark or VLM in VLMEvalKit, please refer to Custom_Benchmark_and_Model.
Example PRs to follow:
The codebase is designed to:
- Provide an easy-to-use, opensource evaluation toolkit to make it convenient for researchers & developers to evaluate existing LVLMs and make evaluation results easy to reproduce.
- Make it easy for VLM developers to evaluate their own models. To evaluate the VLM on multiple supported benchmarks, one just need to implement a single
generatefunction, all other workloads (data downloading, data preprocessing, prediction inference, metric calculation) are handled by the codebase.
The codebase is not designed to:
- Reproduce the exact accuracy number reported in the original papers of all 3rd party benchmarks. The reason can be two-fold:
- VLMEvalKit mainly uses generation-based evaluation for all VLMs (and optionally with LLM-based answer extraction). Meanwhile, some benchmarks may use different metrics (SEEDBench uses PPL-based evaluation, eg.). For these benchmarks, we will compare both scores in the corresponding README file. We encourage developers to support other different evaluation paradigms in the codebase.
- By default, we use the same prompt template for all VLMs to evaluate on a benchmark. Meanwhile, some VLMs may have their specific prompt templates (some may not covered by the codebase at this time). We encourage VLM developers to implement their own prompt template in VLMEvalKit, if that is not covered currently. That will help to improve the reproducibility.
If you use VLMEvalKit in your research or wish to refer to the published OpenSource evaluation results, please use the following BibTeX entry and the BibTex entry corresponding to the specific VLM / benchmark you used.
@misc{2023opencompass,
title={OpenCompass: A Universal Evaluation Platform for Foundation Models},
author={OpenCompass Contributors},
howpublished = {\url{https://github.com/open-compass/opencompass}},
year={2023}
}- opencompass: An LLM evaluation platform, supporting a wide range of models (LLaMA, LLaMa2, ChatGLM2, ChatGPT, Claude, etc) over 50+ datasets.
- MMBench: Official Repo of "MMBench: Is Your Multi-modal Model an All-around Player?"
- BotChat: Evaluating LLMs' multi-round chatting capability.
- LawBench: Benchmarking Legal Knowledge of Large Language Models.