基于 badger
v4.0.1进行源码分析
golang badger kv 存储引擎实现原理系列的文章地址 (更新中)
https://github.com/rfyiamcool/notes#golang-badger
基于 lsm-tree 实现的存储引擎都会存在写放大问题, 写放大的是因为 lsmtree 中某个 level 的容量到达上限, 就会触发 compact 合并, 如果需要合并的数据量大, 需要花费更多的磁盘 IO 来读老 sstable 和写入新 sstable, 这样会影响当前 kv 存储引擎的读写性能.
wiscKey 是一种基于 kv 分离存储优化 lSM-tree 写放大的方法. 使用 wisckey 方法可以减少 lsm tree 中每层的数据量, 降低 compact 合并的频次, 也减少 compact 合并带来的性能开销.
比如, levelN 空间太大需要 compact 下沉到 levelN+1, 但如果 lsm tree 的数据有不少大 value 的 KV, 那么做合并时会有更多的 disk io 开销. 而使用 wisckey kv 存储分离后, 真正的 value 写到一个 vlog 日志文件里, lsm tree 只需要存 vlog 的地址即可, 这样各个的 sstable 可以存更多 kv 数据, 做 compact 合并时开销也相比无 wisckey 要低.
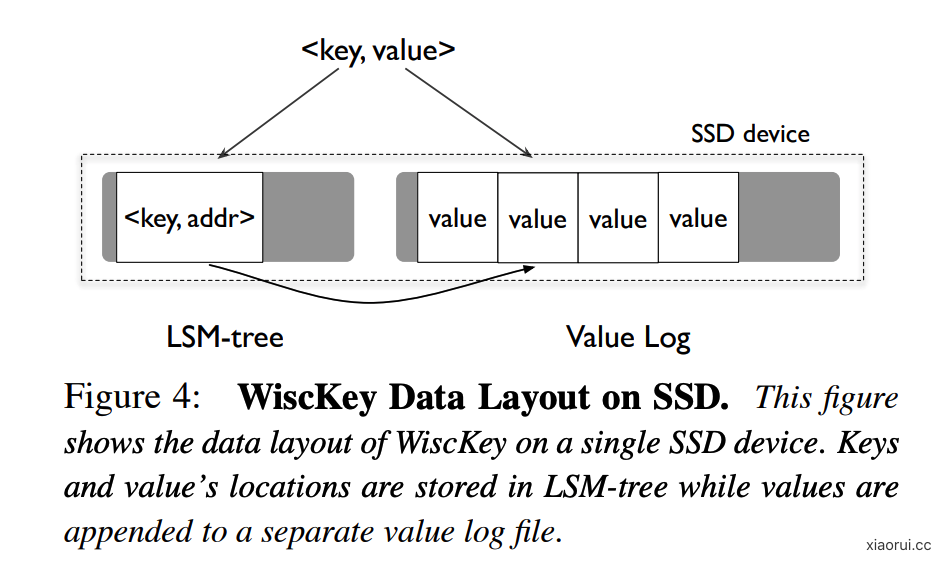
下图为 badgerDB 使用 wisckey 论文方法实现的 lsm tree 存储设计.
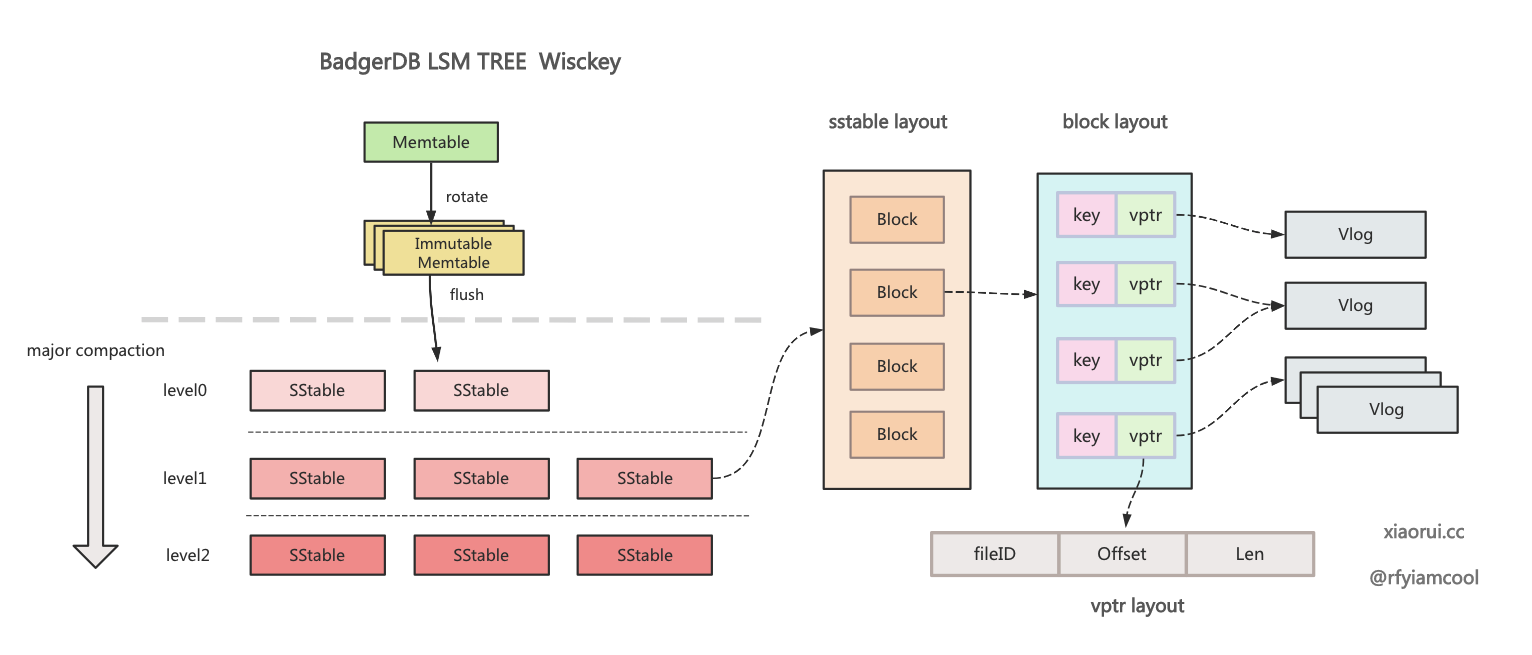
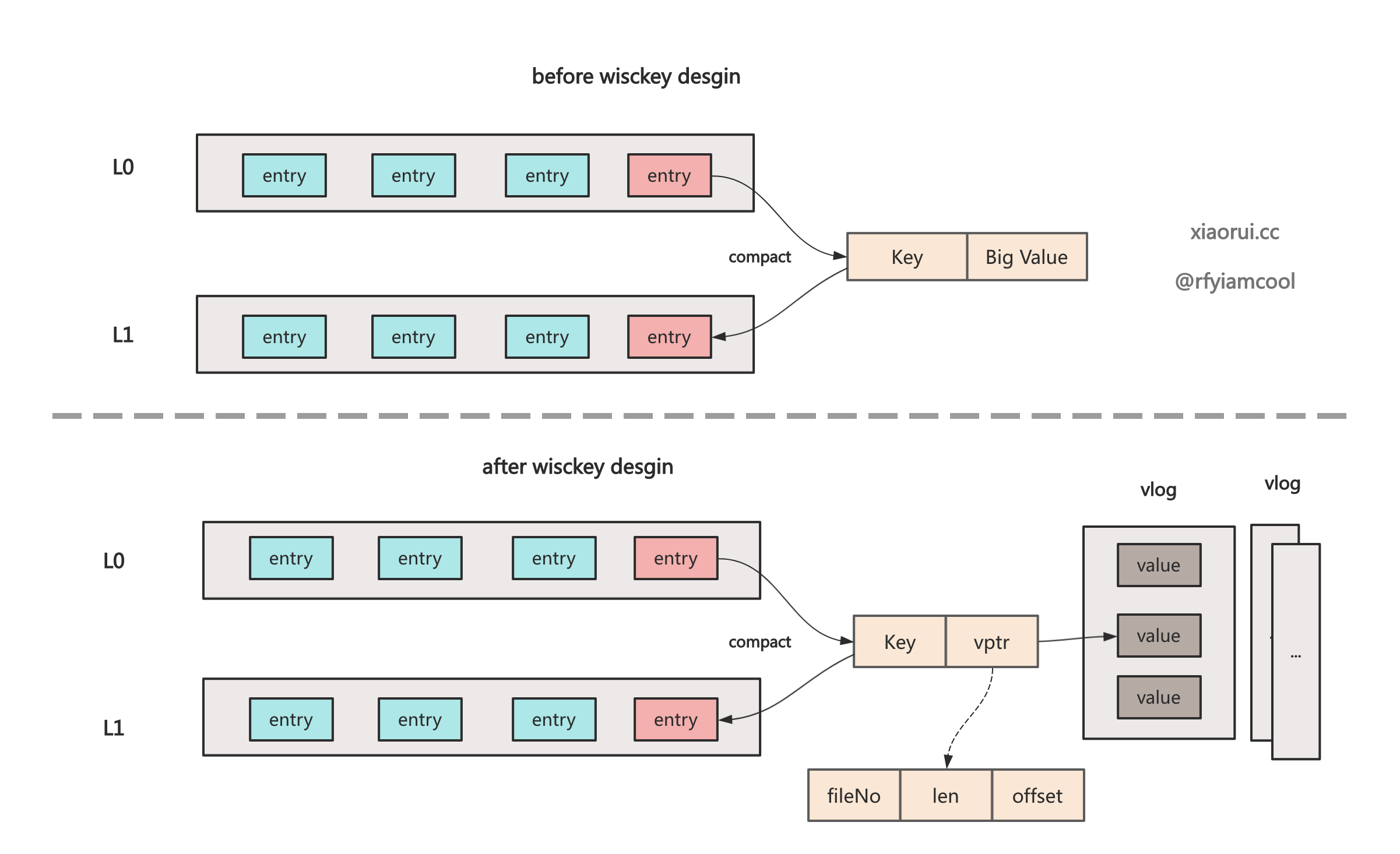
badger 的 wisckey vlog 的实现原理颇为复杂, 其设计目的是为了避免大 value 在 sstable compact 合并时带来的写放大问题.
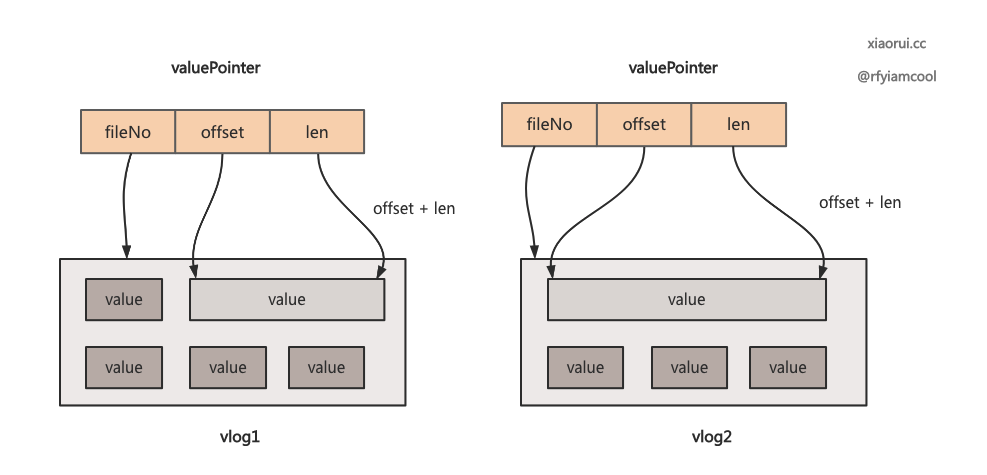
wisckey kv 写流程是这样, 写入时会把大于 1MB 的 value 写到活动的 vlog 里, 在 memtable 和 sstable 只需要存 vptr (fid, len, offset) 就可以了.
查询流程大概这样, 直接按照 vptr 的 fid 定位文件, len + offset 找到对应的 value. 但更新和删除操作就显得繁琐了, 因为后面还涉及到 vlog 空间整理和 gc 回收.
leveldb, rocksdb 本身是没有实现 wisckey kv 分离, 但不少公司基于 rocksdb 开发了含有 wisckey 的存储引擎, 比如 pingcap 的 titan 和字节的 TerarkDB, 但跟 badgerDB 实现上都有些不同, 篇幅有限, 按下不表.
wisckey kv 分离的论文. https://www.usenix.org/system/files/conference/fast16/fast16-papers-lu.pdf
write 写方法实现了 badger 的 wisckey kv 分离存储的逻辑, 其内部实现流程如下.
- 遍历传入的 request 数组, 判断是否满足了大 value 的阈值, 不满足忽略.
- 对满足大 value 的 entry 进行编码, 然后写到 vlog mmap 空间里.
- 如果当前的 vlog 超过了 1GB 的阈值或者 kv 个数超过了 100w 条, 则需要同步刷盘, 且重建新文件.
- 退出前需要进行 sync 刷盘, 当前提前是开启了 SyncWrites 同步选项.
// write is thread-unsafe by design and should not be called concurrently.
func (vlog *valueLog) write(reqs []*request) error {
// 内存模式直接返回
if vlog.db.opt.InMemory {
return nil
}
// 验证是否满足写的条件.
if err := vlog.validateWrites(reqs); err != nil {
return y.Wrapf(err, "while validating writes")
}
// 获取当前 fid 的 logfile 对象
vlog.filesLock.RLock()
maxFid := vlog.maxFid
curlf := vlog.filesMap[maxFid]
vlog.filesLock.RUnlock()
defer func() {
// 如果开启同步写选项, 则需要同步刷盘.
if vlog.opt.SyncWrites {
// 这里的 sync 是 mmap msync 同步刷盘.
if err := curlf.Sync(); err != nil {
vlog.opt.Errorf("Error while curlf sync: %v\n", err)
}
}
}()
// 把数据写到缓冲 buffer 里.
write := func(buf *bytes.Buffer) error {
if buf.Len() == 0 {
return nil
}
// 记录当前最新的 offset
n := uint32(buf.Len())
endOffset := vlog.writableLogOffset.Add(n)
if int(endOffset) >= len(curlf.Data) {
// 扩大 file 空间, 这里涉及到文件空洞的概念.
if err := curlf.Truncate(int64(endOffset)); err != nil {
return err
}
}
// 把 buf 的数据写到 curlf.Data 里.
start := int(endOffset - n)
y.AssertTrue(copy(curlf.Data[start:], buf.Bytes()) == int(n))
// 记录 endOffset
curlf.size.Store(endOffset)
return nil
}
// 落盘方法
toDisk := func() error {
// 如果超过了单个 vlog 的空间阈值或者 kv 个数, 则进行重建文件.
// ValueLogFileSize 默认为 1GB, ValueLogMaxEntries 默认为 100w 条.
if vlog.woffset() > uint32(vlog.opt.ValueLogFileSize) ||
vlog.numEntriesWritten > vlog.opt.ValueLogMaxEntries {
if err := curlf.doneWriting(vlog.woffset()); err != nil {
return err
}
// 重建一个新文件.
newlf, err := vlog.createVlogFile()
if err != nil {
return err
}
curlf = newlf
}
return nil
}
buf := new(bytes.Buffer)
for i := range reqs {
b := reqs[i]
b.Ptrs = b.Ptrs[:0] // 把 slice len 置为 0.
var written, bytesWritten int
valueSizes := make([]int64, 0, len(b.Entries))
// 遍历 request 的所有 kv entry.
for j := range b.Entries {
buf.Reset()
e := b.Entries[j]
valueSizes = append(valueSizes, int64(len(e.Value)))
// 不满足大 value 的阈值, 给个空 vtpr
if e.skipVlogAndSetThreshold(vlog.db.valueThreshold()) {
b.Ptrs = append(b.Ptrs, valuePointer{})
continue
}
// 构建 vptr 对象
var p valuePointer
// 赋值 fil
p.Fid = curlf.fid
// 赋值当前的 offset
p.Offset = vlog.woffset()
tmpMeta := e.meta
// 没明白为什么需要擦除事务的meta
// badger vlog 里不存储事务的标记, 因为
e.meta = e.meta &^ (bitTxn | bitFinTxn)
// 编码数据, 把 hedaer 和 kv 编码后写到传入的 buffer 里.
plen, err := curlf.encodeEntry(buf, e, p.Offset)
if err != nil {
return err
}
// 还原最初的 meta
e.meta = tmpMeta
// 赋值 vptr 的 len 字段
p.Len = uint32(plen)
// 把 vptr 追加到 ptrs
b.Ptrs = append(b.Ptrs, p)
// 写操作
if err := write(buf); err != nil {
return err
}
written++
bytesWritten += buf.Len()
}
// 尝试执行持久化落盘操作.
if err := toDisk(); err != nil {
return err
}
}
// 尝试执行持久化落盘操作.
return toDisk()
}func (lf *logFile) doneWriting(offset uint32) error {
// 如果开启同步写选项, 进行同步刷盘
if lf.opt.SyncWrites {
// unix.msync 进行同步写盘.
if err := lf.Sync(); err != nil {
return y.Wrapf(err, "Unable to sync value log: %q", lf.path)
}
}
lf.lock.Lock()
defer lf.lock.Unlock()
// 使用 truncate 来改变 file 文件的大小, 这里涉及到文件空洞的概念.
if err := lf.Truncate(int64(offset)); err != nil {
return y.Wrapf(err, "Unable to truncate file: %q", lf.path)
}
return nil
}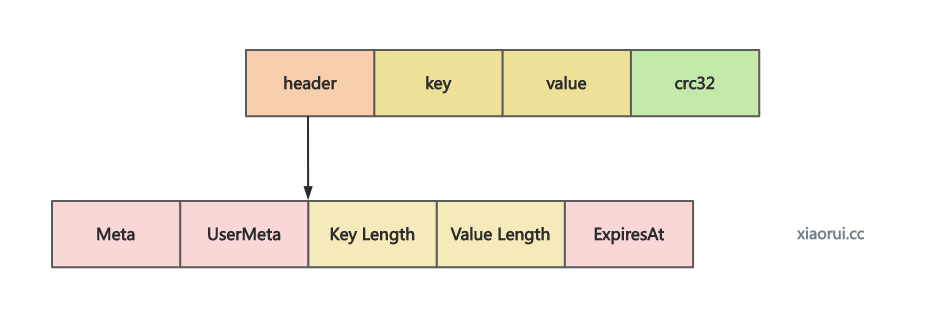
对 entry 进行编码后写到传入的 buf 空间里.
func (lf *logFile) encodeEntry(buf *bytes.Buffer, e *Entry, offset uint32) (int, error) {
// 构建 header struct
h := header{
klen: uint32(len(e.Key)),
vlen: uint32(len(e.Value)),
expiresAt: e.ExpiresAt,
meta: e.meta,
userMeta: e.UserMeta,
}
hash := crc32.New(y.CastagnoliCrcTable)
writer := io.MultiWriter(buf, hash)
// 编码 header
var headerEnc [maxHeaderSize]byte
sz := h.Encode(headerEnc[:])
// 把 header 写到 buf 里.
y.Check2(writer.Write(headerEnc[:sz]))
// 把 key 和 value 写到 buffer 里
if lf.encryptionEnabled() {
eBuf := make([]byte, 0, len(e.Key)+len(e.Value))
eBuf = append(eBuf, e.Key...)
eBuf = append(eBuf, e.Value...)
if err := y.XORBlockStream(
writer, eBuf, lf.dataKey.Data, lf.generateIV(offset)); err != nil {
return 0, y.Wrapf(err, "Error while encoding entry for vlog.")
}
} else {
y.Check2(writer.Write(e.Key))
y.Check2(writer.Write(e.Value))
}
// 把 crc 校验码写到 buffer
// write crc32 hash.
var crcBuf [crc32.Size]byte
binary.BigEndian.PutUint32(crcBuf[:], hash.Sum32())
y.Check2(buf.Write(crcBuf[:]))
return len(headerEnc[:sz]) + len(e.Key) + len(e.Value) + len(crcBuf), nil
}Read 是 vlog 提供的读取接口, 可通过传入 vptr 来获取 vlog 中对应的数据.
// vptr 的数据结构
type valuePointer struct {
Fid uint32
Len uint32
Offset uint32
}
func (vlog *valueLog) Read(vp valuePointer, _ *y.Slice) ([]byte, func(), error) {
// 通过传入的 vp 获取对应 fid 的 logfile 对象, 并通过 vtpr 的 offset 和 len 读取到数据.
buf, lf, err := vlog.readValueBytes(vp)
// 对 lf 进行加锁, 回调方法为释放锁.
cb := vlog.getUnlockCallback(lf)
if err != nil {
return nil, cb, err
}
// 如果开启 checksum 校验, 则需要验证 crc 校验码.
if vlog.opt.VerifyValueChecksum {
// 获取 hash 计算器
hash := crc32.New(y.CastagnoliCrcTable)
// 把 header + kv 写入到 hash 计算器
if _, err := hash.Write(buf[:len(buf)-crc32.Size]); err != nil {
return nil, nil, y.Wrapf(err, "failed to write hash for vp %+v", vp)
}
// 获取 checksum 校验码
checksum := buf[len(buf)-crc32.Size:]
// 如果通过 hash 计算的 crc 跟写入的 crc 不一致, 则返回异常.
if hash.Sum32() != y.BytesToU32(checksum) {
return nil, nil, y.Wrapf(y.ErrChecksumMismatch, "value corrupted for vp: %+v", vp)
}
}
// 构建 header 对象.
var h header
// 通过 buf 解码 header, 并返回 header body length
headerLen := h.Decode(buf)
// headerLen 之后的数据就是 kv 和 crc 了
kv := buf[headerLen:]
// 如果有开启加密, 则进行解密.
if lf.encryptionEnabled() {
kv, err = lf.decryptKV(kv, vp.Offset)
if err != nil {
return nil, cb, err
}
}
// 不可能小于 klen + vlen 的数值
if uint32(len(kv)) < h.klen+h.vlen {
return nil, nil, errors.Errorf("Invalid read: Len: %d read at:[%d:%d]",
len(kv), h.klen, h.klen+h.vlen)
}
// 根据 klen 和 vlen 计算出 value, 返回 value 和 释放 logfile 锁的回调方法.
return kv[h.klen : h.klen+h.vlen], cb, nil
}
readValueBytes 用来获取 valuePointer 对应的 logfile 和对应的 value, 这里的 value 不是 key 真正的 value, 而是 log entry, 含有 header、key、value、crc32 的结构体.
func (vlog *valueLog) readValueBytes(vp valuePointer) ([]byte, *logFile, error) {
lf, err := vlog.getFileRLocked(vp)
if err != nil {
return nil, nil, err
}
buf, err := lf.read(vp)
return buf, lf, err
}getFileRLocked 用来获取 fid 对应的 logfile 对象.
func (vlog *valueLog) getFileRLocked(vp valuePointer) (*logFile, error) {
vlog.filesLock.RLock()
defer vlog.filesLock.RUnlock()
// 获取 fid 对应的 logfile 对象
ret, ok := vlog.filesMap[vp.Fid]
if !ok {
return nil, errors.Errorf("file with ID: %d not found", vp.Fid)
}
maxFid := vlog.maxFid
if !vlog.opt.ReadOnly && vp.Fid == maxFid {
currentOffset := vlog.woffset()
// vptr 的 offset 偏移量大于当前 vlog 的最大 offset, 返回异常.
if vp.Offset >= currentOffset {
return nil, errors.Errorf(
"Invalid value pointer offset: %d greater than current offset: %d",
vp.Offset, currentOffset)
}
}
ret.lock.RLock()
return ret, nil
}logFile.read 用来获取 logfile 日志里 vptr 的数据.
func (lf *logFile) read(p valuePointer) (buf []byte, err error) {
var nbr int64
offset := p.Offset
size := int64(len(lf.Data))
valsz := p.Len
lfsz := lf.size.Load()
// 异常的条件
if int64(offset) >= size || int64(offset+valsz) > size ||
int64(offset+valsz) > int64(lfsz) {
err = y.ErrEOF
} else {
// 返回 [offset: offset+len] 区间的数据.
buf = lf.Data[offset : offset+valsz]
nbr = int64(valsz)
}
return buf, err
}为什么需要对 vlog 进行垃圾回收?
badger 在写大 value 时, 根据 wisckey 设计在 lsm tree 里只写 vptr, 而不需要把整个大 value 都写到 lsm tree 中, 大 value 会写到 value log 日志里.
当这些 key 发生变更时, 以前的旧数据就属于脏数据了, vlog 中会存有各版本的数据. 随着长期的更新数据, 脏数据累计越来越多, 势必造成存储空间的浪费. 所以需要 gc 垃圾回收来解决 vlog 中的脏数据.
gc 实现过程
badger 的实现跟 wisckey 论文差不多, 遍历 vlog 中的每个数据, 拿 vlog 中的数据跟 lsm tree 的数据做对比, 把 fid 和 offset 一样的数据放到缓冲池里, 最后调用 badger 的批量写接口把缓冲池里的数据写进去, 接着尝试删除该 vlog.
badger 存储引擎内部默认没有开启协程去做 wisckey vlog 的空间回收, 需要上层代码自己来周期性的定时 gc 垃圾回收.
下面是自定义定时器调用 wisckey vlog gc 垃圾回收的方法, 另外执执行垃圾回收一定要在业务低峰期来执行, 且频率不能高.
func() {
ticker := time.NewTicker(30 * time.Minute)
defer ticker.Stop()
for range ticker.C {
again:
err := db.RunValueLogGC(0.7)
if err == nil {
goto again
}
}
}RunValueLogGC 方法是 badger 进行 wisckey vlog 垃圾回收的入口方法, 其内部会判断 ratio 值的合理性, 数值需要在 0 - 1 之间. badger 文档中有使用 0.7 作为 discardRatio 比率.
func (db *DB) RunValueLogGC(discardRatio float64) error {
if db.opt.InMemory {
return ErrGCInMemoryMode
}
// 判断比率
if discardRatio >= 1.0 || discardRatio <= 0.0 {
return ErrInvalidRequest
}
// 选择一个 lgofile 进行空间回收.
return db.vlog.runGC(discardRatio)
}
func (vlog *valueLog) runGC(discardRatio float64) error {
select {
case vlog.garbageCh <- struct{}{}:
defer func() {
// 排空
<-vlog.garbageCh
}()
// 获取符合 GC 空间回收要求的 logfile 文件
lf := vlog.pickLog(discardRatio)
if lf == nil {
return ErrNoRewrite
}
// 执行 gc 空间回收
return vlog.doRunGC(lf)
default:
return ErrRejected
}
}
func (vlog *valueLog) doRunGC(lf *logFile) error {
// 执行 vlog 的重写操作
if err := vlog.rewrite(lf); err != nil {
return err
}
// Remove the file from discardStats.
vlog.discardStats.Update(lf.fid, -1)
return nil
}pickLog 用来遍历获取 discard 值最大的 logfile. 每个 vlog 都会记录 discardStats 统计信息, discard 值的代表 vlog 文件中的脏数据占用的空间大小.
func (vlog *valueLog) pickLog(discardRatio float64) *logFile {
vlog.filesLock.RLock()
defer vlog.filesLock.RUnlock()
LOOP:
// 获取脏数据最多的 file id.
fid, discard := vlog.discardStats.MaxDiscard()
// 没有被删除的数据.
if fid == 0 {
vlog.opt.Debugf("No file with discard stats")
return nil
}
// 通过 filesMap 获取 logfile 对象
lf, ok := vlog.filesMap[fid]
// 如果被删除, 则继续尝试获取最大的 discard 的 logfile
if !ok {
vlog.discardStats.Update(fid, -1)
goto LOOP
}
// 验证 value log 是否有效
fi, err := lf.Fd.Stat()
if err != nil {
return nil
}
// 如果脏数据空间 < (总空间 * discardRatio), 则认为小于阈值, 暂不需要回收, 直接跳出.
if thr := discardRatio * float64(fi.Size()); float64(discard) < thr {
return nil
}
// 返回 logfile
if fid < vlog.maxFid {
lf, ok := vlog.filesMap[fid]
y.AssertTrue(ok)
return lf
}
// 直接给空.
return nil
}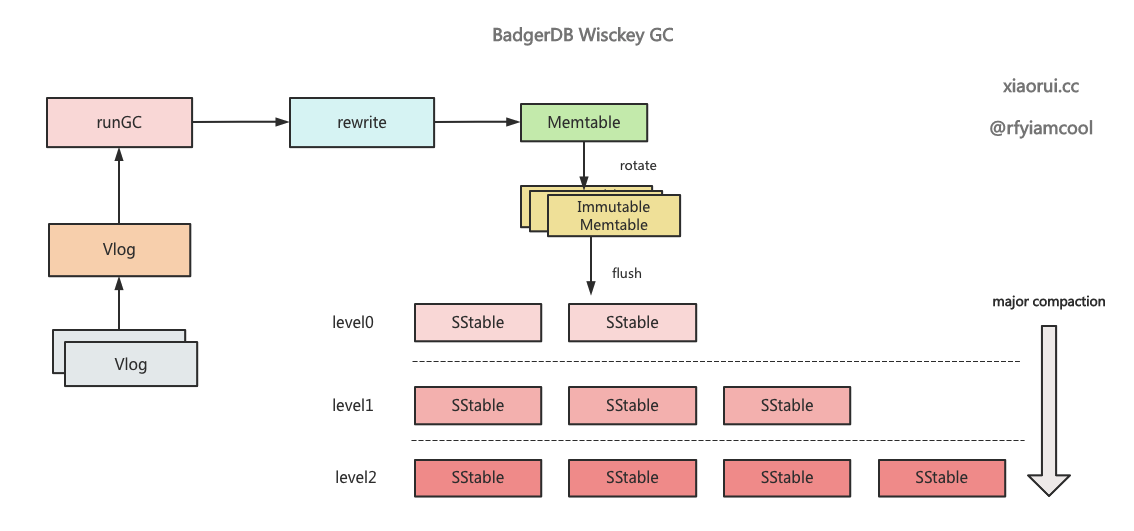
rewrite 重写方法用来实现 wisckey 论文里的垃圾回收, 也可以理解为空间的合并整理.
func (vlog *valueLog) rewrite(f *logFile) error {
vlog.filesLock.RLock()
for _, fid := range vlog.filesToBeDeleted {
if fid == f.fid {
vlog.filesLock.RUnlock()
return errors.Errorf("value log file already marked for deletion fid: %d", fid)
}
}
// 获取最新的 valuelog fid
maxFid := vlog.maxFid
y.AssertTruef(f.fid < maxFid, "fid to move: %d. Current max fid: %d", f.fid, maxFid)
vlog.filesLock.RUnlock()
vlog.opt.Infof("Rewriting fid: %d", f.fid)
wb := make([]*Entry, 0, 1000)
var size int64
var count, moved int
fe := func(e Entry) error {
// 从 lsm tree 里获取 key 的数据.
vs, err := vlog.db.get(e.Key)
if err != nil {
return err
}
// ...
if discardEntry(e, vs, vlog.db) {
return nil
}
// 如果 lsm tree 的 value 为空, 则返回错误.
if len(vs.Value) == 0 {
return errors.Errorf("Empty value: %+v", vs)
}
// 解析 value 到 vptr 结构上, 得到 key 的 fid, len, offset 三个字段.
var vp valuePointer
vp.Decode(vs.Value)
// 如果从 lsm tree 中获取到的 fid 比当前 valueLog 的 fid 更新, 则忽略.
// 说明该 key 更新过, 老 vlog 的数据必然是旧的, 直接忽略即可.
if vp.Fid > f.fid {
return nil
}
// 如果 lsm tree 拿到的 vlog entry 的 offset 还大, 说明该 key 更新过, 该 vlog 里有更新的数据.
if vp.Offset > e.offset {
return nil
}
// 如果 fid 和 offset 一致, 则重新写到 lsm tree 里.
if vp.Fid == f.fid && vp.Offset == e.offset {
moved++
// 构建 entry 对象
ne := new(Entry)
ne.meta = e.meta &^ (bitValuePointer | bitTxn | bitFinTxn)
ne.UserMeta = e.UserMeta
ne.ExpiresAt = e.ExpiresAt
ne.Key = append([]byte{}, e.Key...)
ne.Value = append([]byte{}, e.Value...)
es := ne.estimateSizeAndSetThreshold(vlog.db.valueThreshold())
es += int64(len(e.Value))
// 满足 maxBatchCoutn 或者 maxBatchSize 时, 进行尝试批量写入.
if int64(len(wb)+1) >= vlog.opt.maxBatchCount ||
size+es >= vlog.opt.maxBatchSize {
// 使用 db 的批量写方法重新走一遍 badger 的写流程.
if err := vlog.db.batchSet(wb); err != nil {
return err
}
size = 0
wb = wb[:0] // 对象复用, 只是重置 slice.len
}
// 追加到 wb 缓冲池里
wb = append(wb, ne)
size += es
} else {
// 其他条件, 直接忽略即可.
}
return nil
}
// logfile 实现了迭代器, 把数据依次传递到回调方法里.
_, err := f.iterate(vlog.opt.ReadOnly, 0, func(e Entry, vp valuePointer) error {
return fe(e)
})
if err != nil {
return err
}
batchSize := 1024
var loops int
for i := 0; i < len(wb); {
loops++
if batchSize == 0 {
vlog.db.opt.Warningf("We shouldn't reach batch size of zero.")
return ErrNoRewrite
}
end := i + batchSize
if end > len(wb) {
end = len(wb)
}
// 使用 db 的批量写方法重新走一遍 badger 的写流程.
if err := vlog.db.batchSet(wb[i:end]); err != nil {
if err == ErrTxnTooBig {
// Decrease the batch size to half.
batchSize = batchSize / 2
continue
}
return err
}
i += batchSize
}
// 既然这个 value log 的数据整理完了, 那么就可以删除这个 value log 了.
var deleteFileNow bool
{
vlog.filesLock.Lock()
// 如果已删除, 直接跳出
if _, ok := vlog.filesMap[f.fid]; !ok {
vlog.filesLock.Unlock()
return errors.Errorf("Unable to find fid: %d", f.fid)
}
// 如果 count 为 0 直接删除, 否则暂添加到 filesToBeDeleted 集合中, 后台再异步删除.
if vlog.iteratorCount() == 0 {
delete(vlog.filesMap, f.fid)
deleteFileNow = true
} else {
vlog.filesToBeDeleted = append(vlog.filesToBeDeleted, f.fid)
}
vlog.filesLock.Unlock()
}
if deleteFileNow {
// 删除 value log.
if err := vlog.deleteLogFile(f); err != nil {
return err
}
}
return nil
}把缓冲池里的待写入数据重新提交到 badger 的写接口, 也就是需要被重写的 kv 重新走一遍 badger 写流程. 简述下 badger 写流程, 先写 wisckey vlog, 再写 wal, 接着把数据写到 memtable, 后面等到 flush 协程把活跃的 memtable 添加到 immutable tables 集合里, 按照策略把 immutable memtable 刷盘到 Level0 层, 后面就是 compact 合并压缩重排的事情了.
func (db *DB) batchSet(entries []*Entry) error {
req, err := db.sendToWriteCh(entries)
if err != nil {
return err
}
return req.Wait()
}到此 badgerDB wisckey 读写流程及垃圾回收的原理分析完了.