众所周知 lockfree queue 无锁队列需要注意 spin 忙轮询的问题。当 ringbuffer 已满时,生产者会轮询判断是否可写,不调优的情况下会一直轮询。当 ringbuffer 无数据时,消费者进行轮询判断是否有数据可读,无其他策略优化下,无他就轮询判断。
当 lockfree queue 不可读或不可写时,可以选择一些策略优化忙轮询 spin 的问题。
这里拿 golang runtime mutex 来说,其内部实现有做方一些性能优化。在并发进行锁竞争时,先尝试 atomic cas,拿不到锁,则调用 procyield (cpu pause 空指令) 尝试拿锁,还不行,再尝试调用 osyield (syscall sched_yield) 拿锁。使用这些退避手段后依然无法拿锁,则调用 pthread_mutex_lock (syscall futex) 拿锁,这里拿不到锁则线程会挂起,根据 golang runtime pmg 的调度设计,阻塞的 m 没有释放 p 必然会影响 runtime 调度。当然 sysmon 会检测超时的 Psyscall mp,减轻 runtime 调度阻塞的问题。这里的锁是 runtime.mutex 而非 sync.Mutex,虽然会有锁竞争,但由于使用 runtime.mutex 的模块无慢逻辑的逻辑,所以无需担心。
下面为 runtime.mutex 的设计原理,golang 根据平台不同 runtime.mutex 有两种实现:
代码位置: runtime/lock_sema.go
const (
mutex_unlocked = 0
mutex_locked = 1
mutex_sleeping = 2
active_spin = 4
active_spin_cnt = 30
passive_spin = 1
)
func lock2(l *mutex) {
gp := getg()
if gp.m.locks < 0 {
throw("runtime·lock: lock count")
}
gp.m.locks++
// Speculative grab for lock.
v := atomic.Xchg(key32(&l.key), mutex_locked)
if v == mutex_unlocked {
return
}
wait := v
spin := 0
if ncpu > 1 {
spin = active_spin
}
for {
// Try for lock, spinning.
for i := 0; i < spin; i++ {
for l.key == mutex_unlocked {
if atomic.Cas(key32(&l.key), mutex_unlocked, wait) {
return
}
}
procyield(active_spin_cnt)
}
// Try for lock, rescheduling.
for i := 0; i < passive_spin; i++ {
for l.key == mutex_unlocked {
if atomic.Cas(key32(&l.key), mutex_unlocked, wait) {
return
}
}
osyield()
}
// Sleep.
v = atomic.Xchg(key32(&l.key), mutex_sleeping)
if v == mutex_unlocked {
return
}
wait = mutex_sleeping
futexsleep(key32(&l.key), mutex_sleeping, -1)
}
}runtime.mutex 的加锁过程有些繁琐,但其实现值得学习。
LMax disruptor 是社区中最有名气的 lockfree queue 无锁队列的实现,disruptor 内部有许多可选的等待策略,不同的等待策略在延迟和CPU资源的占用上有所不同。
- BusySpinWaitStrategy: 自旋轮询等待,延迟是最低的,但同时对 CPU 资源的占用也多。
- BlockingWaitStrategy: 使用锁和条件变量来实现通知,CPU资源的占用少,延迟大。
- SleepingWaitStrategy: 在多次循环尝试不成功后,选择让出 CPU 资源,等待下次调度,多次调度后仍不成功,尝试前睡眠一个纳秒级别的时间再尝试。这种策略平衡了延迟和 CPU 资源占用,延迟大小跟时间有关系。
- YieldingWaitStrategy: 在多次循环尝试不成功后,选择让出CPU,等待下次调。平衡了延迟和CPU资源占用,但延迟也比较均匀。
- PhasedBackoffWaitStrategy: 上面多种策略的综合,CPU资源的占用少,延迟大。
下面压测下 cpu pause 空指令的 cpu 表现.
测试代码:
package main
import (
"runtime"
_ "unsafe"
)
func init() {
if ncpu > 1 {
spin = active_spin
}
}
func main() {
for {
procyield(30)
}
}
//go:linkname procyield runtime.procyield
func procyield(cycles uint32)
//go:linkname osyield runtime.osyield
func osyield()通过 perf top 观察到的热度,通过 top 可以看到进程的 cpu 百分比为 100,尝试把 procyield 调整几千,cpu 单核依然满载。

runtime.osyield 本质是 sched_yield 系统调用。sched_yield 可以让当前进程暂停执行,让其它进程有机会获徖 CPU 时间片,简单说主动释放 cpu 资源,并插入到调度队列尾部。
package main
import (
"runtime"
_ "unsafe"
)
var (
ncpu = runtime.NumCPU()
spin = 0
active_spin = 4
passive_spin = 1
)
func init() {
if ncpu > 1 {
spin = active_spin
}
}
func main() {
var i = 0
for {
if i < spin {
procyield(30)
} else {
osyield()
}
i++
}
}
//go:linkname procyield runtime.procyield
func procyield(cycles uint32)
//go:linkname osyield runtime.osyield
func osyield()下面为 perf top 的统计结果,且通过 top 看到进程 cpu 使用率为 100%.
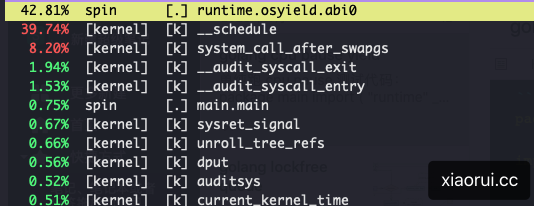
在无数据可读或不可写时,也可以采用休眠来解决死循环轮询问题。根据轮询压测可以测试出各时间区间的 cpu 表现。
轮询等待 10us 的 cpu 开销在 2% 左右,轮询等待 5us 的 cpu 开销在 10% 左右,当轮询的时间小于 5us,cpu 通常在 90% 以上。
测试代码如下:
package main
import (
"time"
_ "unsafe"
)
func main() {
for {
time.Sleep(5 * 1000) // 5us
}
}下面是实现了 channel 和 condition 两种退避阻塞策略.
// ChanBlockStrategy chan阻塞策略
type ChanBlockStrategy struct {
bc chan struct{}
b uint32
}
func NewChanBlockStrategy() *ChanBlockStrategy {
return &ChanBlockStrategy{
bc: make(chan struct{}),
}
}
func (s *ChanBlockStrategy) block() {
// 0:未阻塞;1:阻塞
if !atomic.CompareAndSwapUint32(&s.b, 0, 1) {
return
}
// 等待信号
<-s.bc
}
func (s *ChanBlockStrategy) release() {
if atomic.CompareAndSwapUint32(&s.b, 1, 0) {
// 表示可以释放,即chan是等待状态
s.bc <- struct{}{}
}
return
}
// ConditionBlockStrategy condition 阻塞策略
type ConditionBlockStrategy struct {
cond *sync.Cond
}
func NewConditionBlockStrategy() *ConditionBlockStrategy {
return &ConditionBlockStrategy{
cond: sync.NewCond(&sync.Mutex{}),
}
}
func (s *ConditionBlockStrategy) block() {
s.cond.L.Lock()
s.cond.Wait()
s.cond.L.Unlock()
}
func (s *ConditionBlockStrategy) release() {
s.cond.Broadcast()
}下面为 lockfree queue 采用退避策略,其流程大概如下。
先进行 cpu pause 空执行,然后执行 runtime.Gosched,最后执行 sleep 5s。为什么没采用 osyield,因为 osyield 是通过 sched_yield 系统调用实现的,该操作触发线程上下文切换,保存当前线程上下文到队列尾部,再由内核调度器重新调度可运行线程,切换的开销在 3us 左右。而 runtime.Gosched 的切换就简单的多,无需陷入内核做上下文切换,只需保存当前 g 的上下文信息,切 g0 重新调度新可运行 g 即可,调度切换开销在 100ns 左右。
而最后阻塞的策略选择休眠方法,轮询 sleep 5us 的 cpu 开销也就 2% 左右,主要优点是简单可控。在 lockfree queue 的场景下已经足够了。当然相比 channel 和 condition 阻塞策略来说,及时性差点意思。
package main
import (
"runtime"
"time"
_ "unsafe"
)
var (
ncpu = runtime.NumCPU()
spin = 0
active_spin = 4
passive_spin = 1
)
func init() {
if ncpu > 1 {
spin = active_spin
}
}
func main() {
var i = 0
for {
if i < spin {
procyield(30)
} else if i < spin+passive_spin {
runtime.Gosched()
} else {
time.Sleep(5 * 1000) // 5us
}
i++
}
}
//go:linkname procyield runtime.procyield
func procyield(cycles uint32)
//go:linkname osyield runtime.osyield
func osyield()本文讲解了 runtime.mutex 是如何一步步的拿锁的,其流程是先 cas,再 cpu pause,接着 osyield,最后使用 futex 阻塞拿锁。
lockfree queue 无锁队列通常在不可读不可写时,产生大量的无效 spin 判断,直到可读或可写。这样的 spin 逻辑会造成 cpu 飙高。为了优化这类 spin 忙轮询逻辑带来的 cpu 资源浪费。
disruptor 其内部实现了几种策略,BlockingWaitStrategy 使用条件变量来唤醒通知,SleepingWaitStrategy 则通过休眠等待的方式来让出 cpu 资源。YieldingWaitStrategy 则是通过 sched_yield 的方式切出调度。
参考 disruptor 的等待策略设计,本文使用 golang 实现并进行压测。