Runhouse is a unified interface into existing compute and data systems, built to reclaim the 50-75% of ML practitioners' time lost to debugging, adapting, or repackaging code for different environments.
- 🦸♀️ OSS maintainers who want to improve the accessibility, reproducibility, and reach of their code,
without having to build support or examples for every cloud or compute system (e.g. Kubernetes) one by one.
- See this in action in 🤗 Hugging Face (Transformers, Accelerate) and 🦜🔗 Langchain
- 👩🔬 ML Researchers and Data Scientists who don't want to spend or wait 3-6 months translating and packaging their work for production.
- 👩🏭 ML Engineers who want to be able to update and improve production services, pipelines, and artifacts with a Pythonic, debuggable devX.
- 👩🔧 ML Platform teams who want a versioned, shared, maintainable stack of services and data artifacts that research and production pipelines both depend on.
"Learn once, run anywhere"
Runhouse is like PyTorch + Terraform + Google Drive.
- Just as PyTorch lets you send a model or tensor
.to(device), Runhouse OSS lets you domy_fn.to('gcp_a100')ormy_table.to('s3'): send functions and data to any of your compute or data infra, all in Python, and continue to interact with them eagerly (there's no DAG) from your existing code and environment. Think of it as an expansion pack to Python that lets it take detours to remote machines or manipulate remote data. - Just as Terraform is a unified language for creation and destruction of infra, the Runhouse APIs are a unified interface into existing compute and data systems. See what we already support and what's on the roadmap, below.
- Runhouse resources can be shared across environments or teams, providing a Google Drive-like layer for accessibility, visibility, and management across all your infra and providers.
This allows you to:
- Call your preprocessing, training, and inference each on different hardware from inside a single notebook or script
- Slot that script into a single orchestrator node rather than translate it into an ML pipeline DAG of docker images
- Share any of those services or data artifacts with your team instantly, and update them over time
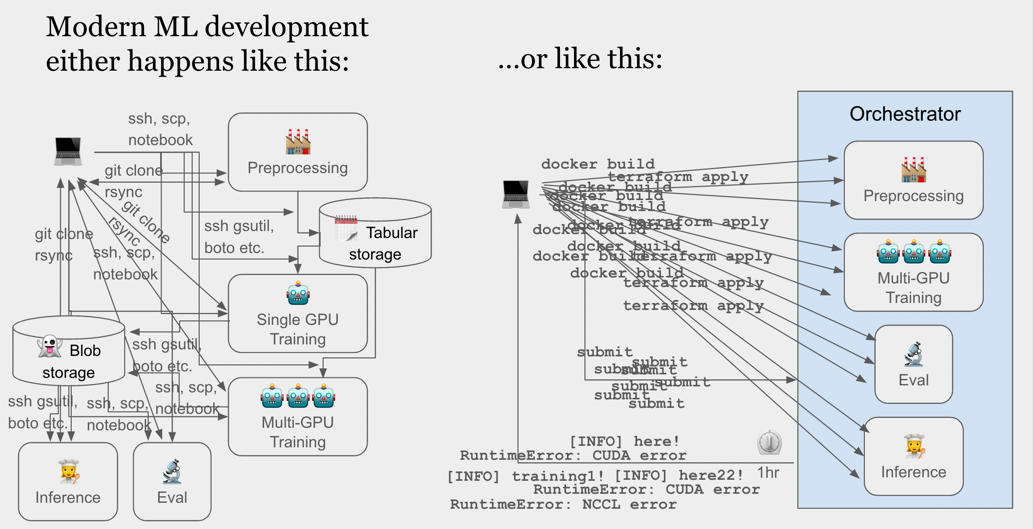
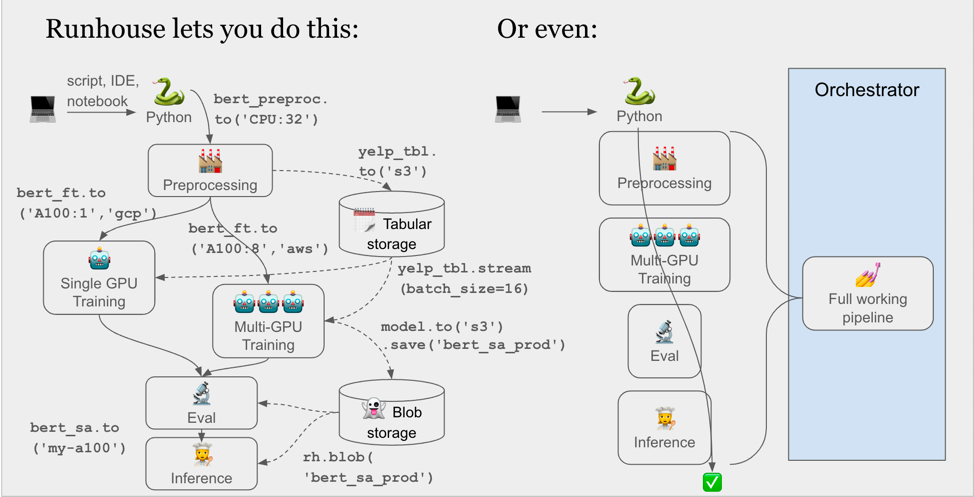
It wraps industry-standard tooling like Ray and the Cloud SDKs (boto, gsutil, etc. via SkyPilot) to give you production-quality features like queuing, distributed, async, logging, low latency, hardware efficiency, auto-launching, and auto-termination out of the box.
Here is all the code you need to stand up a stable diffusion inference service on a fresh cloud GPU.
import runhouse as rh
from diffusers import StableDiffusionPipeline
def sd_generate(prompt):
model = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-base").to("cuda")
return model(prompt).images[0]
gpu = rh.cluster(name="my-a100", instance_type="A100:1").up_if_not()
sd_generate = rh.function(sd_generate).to(gpu, env=["torch", "diffusers"])
# the following runs on our remote A100 gpu
sd_generate("An oil painting of Keanu Reeves eating a sandwich.").show()
sd_generate.save(name="sd_generate")On the data side, sync folders, tables, or blobs between local, clusters, and file storage. All this is done without bouncing off the laptop.
import runhouse as rh
folder_on_gpu = rh.folder(path="./instance_images").to(gpu, path="dreambooth/instance_images")
folder_on_s3 = folder_on_gpu.to("s3", path="dreambooth/instance_images")
folder_on_s3.save("dreambooth_outputs")Reuse your saved compute and data resources from anywhere, with a single line of Python.
sd_generate = rh.function(name="sd_generate")
image = sd_generate("A hot dog made of matcha.")
folder_on_s3 = rh.folder(name="dreambooth_outputs")
folder_on_local = folder_on_s3.to("here")These APIs work from anywhere with a Python interpreter and an internet connection. Notebooks, scripts, pipeline nodes, etc. are all fair game.
- An orchestrator / scheduler (Airflow, Prefect, Metaflow)
- A distributed compute DSL (Ray, Spark, Dask)
- An ML Platform (Sagemaker, Vertex, Azure ML)
- A model registry / experiment manager / MLOps framework (MLFlow, WNB, Kubeflow)
- Hosted compute (Modal, Banana, Replicate)
Please see the Getting Started guide.
tldr;
pip install runhouse
# Or "runhouse[aws]", "runhouse[gcp]", "runhouse[azure]", "runhouse[all]"
# [optional] to set up cloud provider secrets:
sky check
# [optional] login for portability:
runhouse login
You can unlock some unique portability features by creating an (always free) account and saving your secrets and resource metadata there. Log in from anywhere to access all previously saved secrets and resources, ready to be used with with no additional setup.
To log in, run runhouse login from the command line, or
rh.login() from Python.
Note: Secrets are stored in Hashicorp Vault (an industry standard for secrets management), and our APIs simply call Vault's APIs. We only ever store light metadata about your resources (e.g. my_folder_name -> [provider, bucket, path]) on our API servers, while all actual data and compute stays inside your own cloud account and never hits our servers. We plan to add support for BYO secrets management shortly. Let us know if you need it and which system you use.
Runhouse is an ambitious project to provide a unified API into many paradigms and providers for various types of infra. You can find our currently support systems and high-level roadmap below. Please reach out (first name at run.house) to contribute or share feedback!
- Compute
- On-prem
- Single instance - Supported
- Ray cluster - Supported
- Kubernetes - Planned
- Slurm - Exploratory
- Cloud VMs
- AWS - Supported
- GCP - Supported
- Azure - Supported
- Lambda - Supported
- Serverless - Planned
- On-prem
- Data
- Blob storage
- AWS - Supported
- GCP - Supported
- R2 - Planned
- Azure - Exploratory
- Tables
- Arrow-based (Pandas, Hugging Face, PyArrow, Ray.data, Dask, CuDF) - Supported
- SQL-style - Planned
- Lakehouse - Exploratory
- KVStores - Exploratory
- Blob storage
- Management
- Secrets
- Runhouse Den (via Hashicorp Vault) - Supported
- Custom (Vault, AWS, GCP, Azure) - Planned
- RBAC - Planned
- Telemetry - Planned
- Secrets
Docs: High-level overviews of the architecture, detailed API references, and basic API examples.
Tutorials Repo: A comprehensive walkthrough of Runhouse APIs through some popular ML examples, think Stable Diffusion, Dreambooth, BERT.
Funhouse Repo: Standalone Runhouse apps to try out fun ML ideas, think the latest Stable Diffusion models, text generation models, launching Gradio spaces, and even more!
Comparisons Repo: Comparisons of Runhouse with other ML solutions, with working code examples.
Message us on Discord, email us (first name at run.house), or create an issue.
We welcome contributions! Please check out contributing if you're interested.