Commit 3aab05e
authored
Rollup merge of #122614 - notriddle:notriddle/search-desc, r=GuillaumeGomez
rustdoc-search: shard the search result descriptions
## Preview
This makes no visual changes to rustdoc search. It's a pure perf improvement.
<details><summary>old</summary>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240317_AiDc61_2EM,240317_AiDcM0_2EN>
Waterfall diagram:
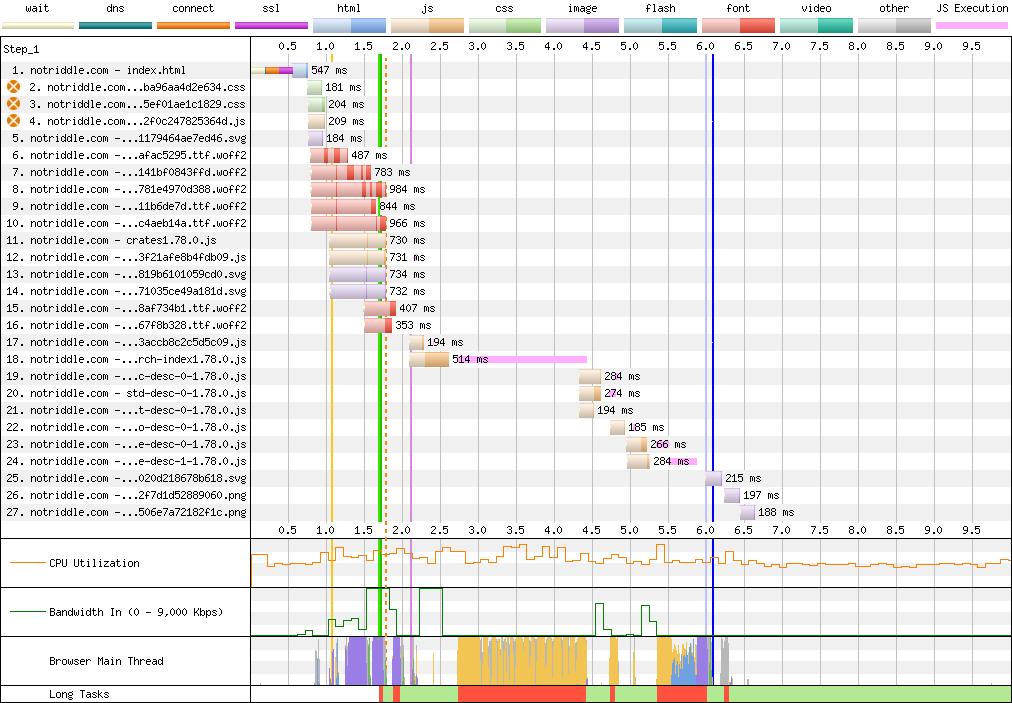
</details>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc2/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240322_BiDcCH_13R,240322_AiDcJY_104>

## Description
r? `@GuillaumeGomez`
The descriptions are, on almost all crates[^1], the majority of the size of the search index, even though they aren't really used for searching. This makes it relatively easy to separate them into their own files.
Additionally, this PR pulls out information about whether there's a description into a bitmap. This allows us to sort, truncate, *then* download.
This PR also bumps us to ES8. Out of the browsers we support, all of them support async functions according to caniuse.
https://caniuse.com/async-functions
[^1]:
<https://microsoft.github.io/windows-docs-rs/>, a crate with
44MiB of pure names and no descriptions for them, is an outlier
and should not be counted. But this PR should improve it, by replacing a long line of empty strings with a compressed bitmap with a single Run section. Just not very much.
## Detailed sizes
```console
$ cat test.sh
set -ex
cp ../search-index*.js search-index.js
awk 'FNR==NR {a++;next} FNR<a-3' search-index.js{,} | awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}' | sed -E "s:\\\\':':g" > search-index.json
jq -c '.t' search-index.json > t.json
jq -c '.n' search-index.json > n.json
jq -c '.q' search-index.json > q.json
jq -c '.D' search-index.json > D.json
jq -c '.e' search-index.json > e.json
jq -c '.i' search-index.json > i.json
jq -c '.f' search-index.json > f.json
jq -c '.c' search-index.json > c.json
jq -c '.p' search-index.json > p.json
jq -c '.a' search-index.json > a.json
du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
$ bash test.sh
+ cp ../search-index1.78.0.js search-index.js
+ awk 'FNR==NR {a++;next} FNR<a-3' search-index.js search-index.js
+ awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}'
+ sed -E 's:\\'\'':'\'':g'
+ jq -c .t search-index.json
+ jq -c .n search-index.json
+ jq -c .q search-index.json
+ jq -c .D search-index.json
+ jq -c .e search-index.json
+ jq -c .i search-index.json
+ jq -c .f search-index.json
+ jq -c .c search-index.json
+ jq -c .p search-index.json
+ jq -c .a search-index.json
+ du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
64K t.json
800K n.json
8.0K q.json
4.0K D.json
16K e.json
192K i.json
544K f.json
4.0K c.json
36K p.json
20K a.json
```
These are, roughly, the size of each section in the standard library (this tool actually excludes libtest, for parsing-json-with-awk reasons, but libtest is tiny so it's probably not important).
t = item type, like "struct", "free fn", or "type alias". Since one byte is used for every item, this implies that there are approximately 64 thousand items in the standard library.
n = name, and that's now the largest section of the search index with the descriptions removed from it
q = parent *module* path, stored parallel to the items within
D = the size of each description shard, stored as vlq hex numbers
e = empty description bit flags, stored as a roaring bitmap
i = parent *type* index as a link into `p`, stored as decimal json numbers; used only for associated types; might want to switch to vlq hex, since that's shorter, but that would be a separate pr
f = function signature, stored as lists of lists that index into `p`
c = deprecation flag, stored as a roaring bitmap
p = parent *type*, stored separately and linked into from `i` and `f`
a = alias, as [[key, value]] pairs
## Search performance
http://notriddle.com/rustdoc-html-demo-11/perf-shard/index.html
For example, in stm32f4:
<table><thead><tr><th>before<th>after</tr></thead>
<tbody><tr><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 617
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 198
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 282
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 426
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 673
```
</td><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 716
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 207
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 289
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 418
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 687
```
</td></tr><tr><td>
```
user: 005.345 s
sys: 002.955 s
wall: 006.899 s
child_RSS_high: 583664 KiB
group_mem_high: 557876 KiB
```
</td><td>
```
user: 004.652 s
sys: 000.565 s
wall: 003.865 s
child_RSS_high: 538696 KiB
group_mem_high: 511724 KiB
```
</td></tr>
</table>
This perf tester is janky and unscientific enough that the apparent differences might just be noise. If it's not an order of magnitude, it's probably not real.
## Future possibilities
* Currently, results are not shown until the descriptions are downloaded. Theoretically, the description-less results could be shown. But actually doing that, and making sure it works properly, would require extra work (we have to be careful to avoid layout jumps).
* More than just descriptions can be sharded this way. But we have to be careful to make sure the size wins are worth the round trips. Ideally, data that’s needed only for display should be sharded while data needed for search isn’t.
* [Full text search](https://internals.rust-lang.org/t/full-text-search-for-rustdoc-and-doc-rs/20427) also needs this kind of infrastructure. A good implementation might store a compressed bloom filter in the search index, then download the full keyword in shards. But, we have to be careful not just of the amount readers have to download, but also of the amount that [publishers](https://gist.github.com/notriddle/c289e77f3ed469d1c0238d1d135d49e1) have to store.File tree
14 files changed
+831
-239
lines changed- src
- ci/docker/host-x86_64/mingw-check
- librustdoc
- html
- render
- search_index
- static
- js
- tools/rustdoc-js
- tests/rustdoc
14 files changed
+831
-239
lines changed| Original file line number | Diff line number | Diff line change | |
|---|---|---|---|
| |||
4783 | 4783 | | |
4784 | 4784 | | |
4785 | 4785 | | |
| 4786 | + | |
| 4787 | + | |
4786 | 4788 | | |
4787 | 4789 | | |
4788 | 4790 | | |
| |||
| Original file line number | Diff line number | Diff line change | |
|---|---|---|---|
| |||
60 | 60 | | |
61 | 61 | | |
62 | 62 | | |
63 | | - | |
| 63 | + | |
64 | 64 | | |
65 | 65 | | |
66 | 66 | | |
| Original file line number | Diff line number | Diff line change | |
|---|---|---|---|
| |||
9 | 9 | | |
10 | 10 | | |
11 | 11 | | |
| 12 | + | |
| 13 | + | |
12 | 14 | | |
13 | 15 | | |
14 | 16 | | |
| |||
| Original file line number | Diff line number | Diff line change | |
|---|---|---|---|
| |||
184 | 184 | | |
185 | 185 | | |
186 | 186 | | |
187 | | - | |
188 | | - | |
| 187 | + | |
189 | 188 | | |
190 | 189 | | |
191 | | - | |
| 190 | + | |
192 | 191 | | |
193 | | - | |
| 192 | + | |
194 | 193 | | |
195 | 194 | | |
196 | | - | |
197 | | - | |
198 | | - | |
199 | | - | |
200 | | - | |
201 | | - | |
202 | | - | |
203 | | - | |
204 | | - | |
205 | | - | |
206 | | - | |
207 | | - | |
208 | | - | |
209 | | - | |
210 | | - | |
211 | | - | |
212 | | - | |
213 | | - | |
214 | | - | |
215 | | - | |
216 | | - | |
217 | | - | |
218 | | - | |
219 | | - | |
220 | | - | |
| 195 | + | |
221 | 196 | | |
222 | 197 | | |
223 | 198 | | |
| |||
| Original file line number | Diff line number | Diff line change | |
|---|---|---|---|
| |||
| 1 | + | |
| 2 | + | |
1 | 3 | | |
2 | 4 | | |
3 | 5 | | |
| |||
17 | 19 | | |
18 | 20 | | |
19 | 21 | | |
| 22 | + | |
| 23 | + | |
| 24 | + | |
| 25 | + | |
| 26 | + | |
| 27 | + | |
| 28 | + | |
| 29 | + | |
| 30 | + | |
| 31 | + | |
| 32 | + | |
| 33 | + | |
| 34 | + | |
| 35 | + | |
| 36 | + | |
| 37 | + | |
| 38 | + | |
| 39 | + | |
| 40 | + | |
| 41 | + | |
| 42 | + | |
| 43 | + | |
| 44 | + | |
| 45 | + | |
| 46 | + | |
| 47 | + | |
| 48 | + | |
| 49 | + | |
| 50 | + | |
| 51 | + | |
| 52 | + | |
| 53 | + | |
| 54 | + | |
| 55 | + | |
20 | 56 | | |
21 | 57 | | |
22 | 58 | | |
23 | 59 | | |
24 | 60 | | |
25 | | - | |
| 61 | + | |
26 | 62 | | |
27 | 63 | | |
28 | 64 | | |
| |||
319 | 355 | | |
320 | 356 | | |
321 | 357 | | |
322 | | - | |
323 | 358 | | |
324 | 359 | | |
325 | 360 | | |
| |||
328 | 363 | | |
329 | 364 | | |
330 | 365 | | |
| 366 | + | |
| 367 | + | |
| 368 | + | |
| 369 | + | |
| 370 | + | |
331 | 371 | | |
332 | 372 | | |
333 | 373 | | |
| |||
409 | 449 | | |
410 | 450 | | |
411 | 451 | | |
412 | | - | |
413 | 452 | | |
414 | 453 | | |
415 | 454 | | |
| |||
432 | 471 | | |
433 | 472 | | |
434 | 473 | | |
435 | | - | |
436 | 474 | | |
437 | 475 | | |
438 | 476 | | |
| |||
444 | 482 | | |
445 | 483 | | |
446 | 484 | | |
447 | | - | |
| 485 | + | |
| 486 | + | |
448 | 487 | | |
449 | 488 | | |
450 | 489 | | |
| |||
455 | 494 | | |
456 | 495 | | |
457 | 496 | | |
458 | | - | |
459 | 497 | | |
460 | 498 | | |
461 | | - | |
462 | 499 | | |
463 | | - | |
464 | 500 | | |
465 | 501 | | |
466 | | - | |
| 502 | + | |
467 | 503 | | |
468 | 504 | | |
| 505 | + | |
| 506 | + | |
469 | 507 | | |
470 | 508 | | |
471 | 509 | | |
472 | 510 | | |
473 | 511 | | |
474 | 512 | | |
475 | 513 | | |
476 | | - | |
477 | | - | |
| 514 | + | |
| 515 | + | |
| 516 | + | |
| 517 | + | |
| 518 | + | |
| 519 | + | |
| 520 | + | |
| 521 | + | |
| 522 | + | |
| 523 | + | |
| 524 | + | |
| 525 | + | |
| 526 | + | |
| 527 | + | |
| 528 | + | |
| 529 | + | |
| 530 | + | |
| 531 | + | |
| 532 | + | |
| 533 | + | |
| 534 | + | |
| 535 | + | |
| 536 | + | |
| 537 | + | |
| 538 | + | |
| 539 | + | |
| 540 | + | |
| 541 | + | |
| 542 | + | |
| 543 | + | |
| 544 | + | |
| 545 | + | |
| 546 | + | |
| 547 | + | |
| 548 | + | |
| 549 | + | |
| 550 | + | |
| 551 | + | |
| 552 | + | |
| 553 | + | |
| 554 | + | |
| 555 | + | |
| 556 | + | |
478 | 557 | | |
479 | 558 | | |
480 | 559 | | |
481 | | - | |
482 | 560 | | |
483 | 561 | | |
484 | 562 | | |
485 | 563 | | |
| 564 | + | |
| 565 | + | |
486 | 566 | | |
487 | 567 | | |
488 | 568 | | |
489 | 569 | | |
490 | 570 | | |
491 | 571 | | |
492 | 572 | | |
493 | | - | |
| 573 | + | |
| 574 | + | |
494 | 575 | | |
495 | 576 | | |
496 | 577 | | |
| |||
0 commit comments