[TOC]
主要内容:自动微分,Tensorflow,CNN & RNN,GRU
读取参数$\rightarrow$前向计算中间值$\rightarrow$进行预测 反向微分,更改参数,优化模型
- 传统方法:求函数微分的解析式(手动);数值微分(不准确);符号微分(表达式爆炸)
- 自动微分:基于链式法则,把表达式写成图的形式,对图中的每个环节分别求导,最后再组合起来。
- 前向传播&反向传播
- 前向传播适用于输入少,输出多的情况算的是每个节点$\frac{\partial v_i}{\partial x}$,其中$v_i$是节点,$x$是输入,能得到每个输出对某一输入的偏导
- 反向传播适用于输出少,输入多算的是每个节点$\frac{\partial y}{\partial v_i}$,其中$y$是输出,最后能得到某一输出对每个输入的偏导。神经网络对某一输出对每个输入的偏导更感兴趣,因此更经常采用反向传播算法。

-
Google Deep Learning Library, Python on top of C++
-
tf1.0 $ \rightarrow$ tf2.0 不再需要tf.session()延迟进行运算
- “张量流”
- 自动微分
- 求导计算图(表达数据、参数之间的计算关系)
- 底层:Eigen:线性代数C++模板库
- 中层:c++与python的借口
- 顶层:训练库推断库
- tf2常用库:Keras
- dimension、length、shape、volume
-
- CNN: 自动驾驶、人脸识别;通过2D, 3D卷积核提取特征;LeNet,ResNet,VGG
- RNN: 时间序列数据处理:手写识别、语音识别、诗歌填词、代码生成、股价预测、天气预测、机器翻译、图片注释、对联撰写
-
- 卷积:局部区域的权重W共用,每个卷积层后通常紧跟着下采样层。
- Conv2D:二维卷积,超参数(卷积核个数,核大小,padding, strides)
- Pooling2D:(pooling_type, window_shape, padding, strides)不改变tensor的深度,只改变大小
- Dropout:解决过拟合
- Dense层:全连接层 (超参数:层数):input: L , weight: L*U, output: U
-
循环神经网络可以通过不停的将信息循环操作,保证信息持续存在,从而解决传统神经网络难以利用前面的事件信息来对后面事件进行分类处理的问题。
- keras.layers.RNN
- LSTM:增加了记忆单元
- keras.layer.LSTM
- 解决RNN远距离收敛慢、梯度爆炸的问题。

拓扑结构,划分为前馈网络、反馈网络、和记忆网络
多层全连接网络(Dense密集)
按batch输出时,输入数据变成多维(二维,一列表示一组样本) 排列结构:layer全1d 超参数:神经元个数为U 输入长度为L 参数共L*U个 最后对U个输出进行Softmax处理
-
相比LSTM,使用GRU能够达到相近的效果,并且更容易进行训练,能够很大程度上提高训练效率,因此很多时候会更倾向于使用GRU。
-
输入输出结构:同普通的RNN
有一个当前的输入**$x^t$** ,和上一个节点传递下来的隐状态(hidden state)$h^{t-1}$,这个隐状态包含了之前节点的相关信息。结合$x^t$ 和
$h^{t-1}$ ,,GRU会得到当前隐藏节点的输出$y^t$和传递给下一个节点的隐状态$h^t$

通过上一个传输下来的状态 和当前节点的输入
来获取两个门控状态。如下图2-2所示,其中
控制重置的门控(reset gate),
为控制更新的门控(update gate)。
Tips: 为*sigmoid*函数,通过这个函数可以将数据变换为0-1范围内的数值,从而来充当门控信号。
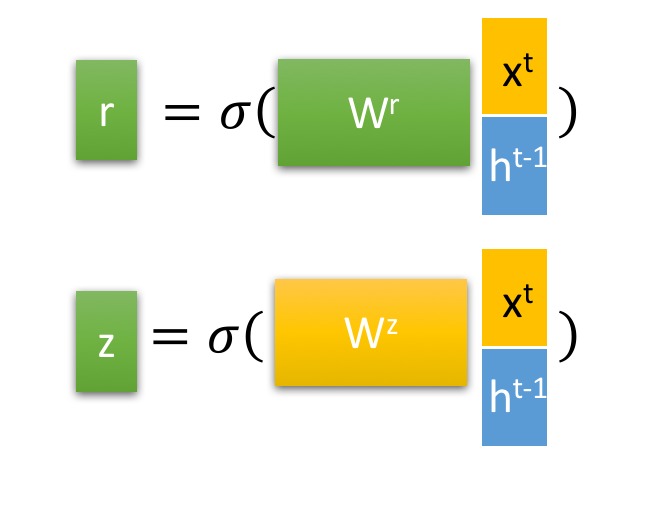
得到门控信号之后,首先使用重置门控来得到**“重置”之后的数据 ,再将
与输入
进行拼接,再通过一个tanh激活函数来将数据放缩到-1~1**的范围内。即得到如下图2-3所示的
。

这里的 主要是包含了当前输入的
数据。有针对性地对
添加到当前的隐藏状态,相当于”记忆了当前时刻的状态“。
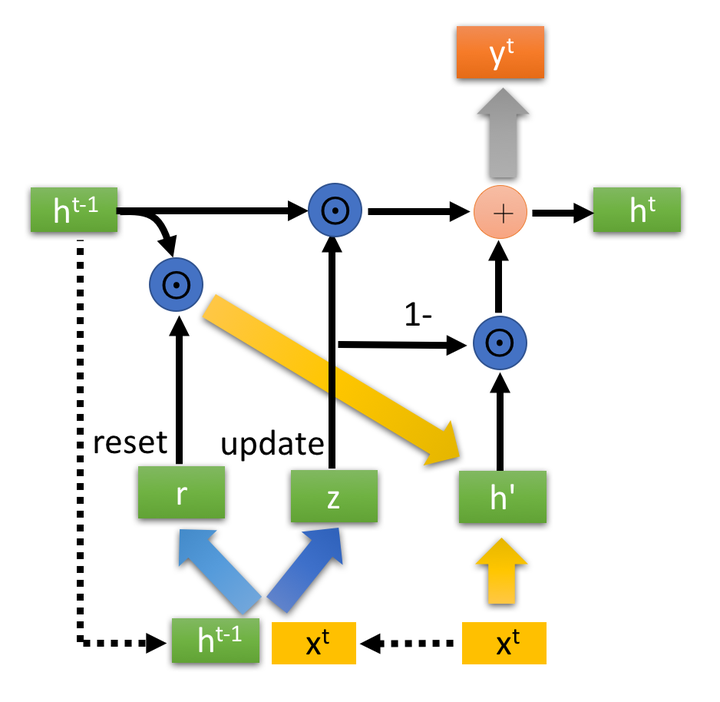
同时进行遗忘和记忆两个步骤。
更新表达式:
为更新门控(update gate)。
门控信号 的范围为0~1。越接近1,代表”记忆“下来的数据越多;而越接近0则代表”遗忘“的越多。
:表示对原本隐藏状态的选择性“遗忘”。这里的
相当于成遗忘门(forget gate),忘记
维度中一些不重要的信息。
: 表示对包含当前节点信息的
进行选择性”记忆“。
遗忘门与输入门组合构成更新门,新增重置门