关系数据库表是用于存储和组织信息的数据结构,可以将表理解为由行和列组成的表格,类似于Excel的电子表格的形式。有的表简单,有的表复杂,有的表根本不用来存储任何长期的数据,有的表读取时非常快,但是插入数据时去很差;而我们在实际开发过程中,就可能需要各种各样的表,不同的表,就意味着存储不同类型的数据,数据的处理上也会存在着差异。
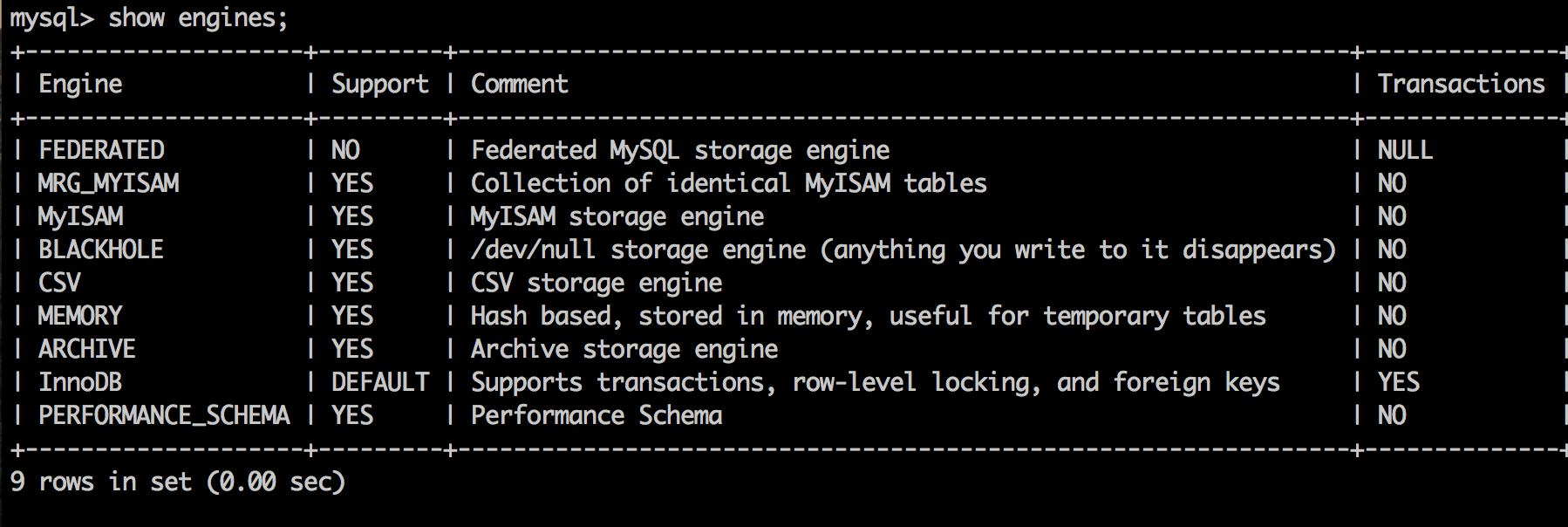
对于MySQL来说,它提供了很多种类型的存储引擎,我们可以根据对数据处理的需求,选择不同的存储引擎,从而最大限度的利用MySQL强大的功能。可以使用 show engines; 命令查看MySQL支持的引擎:
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。下图是MyISAM索引的原理图:
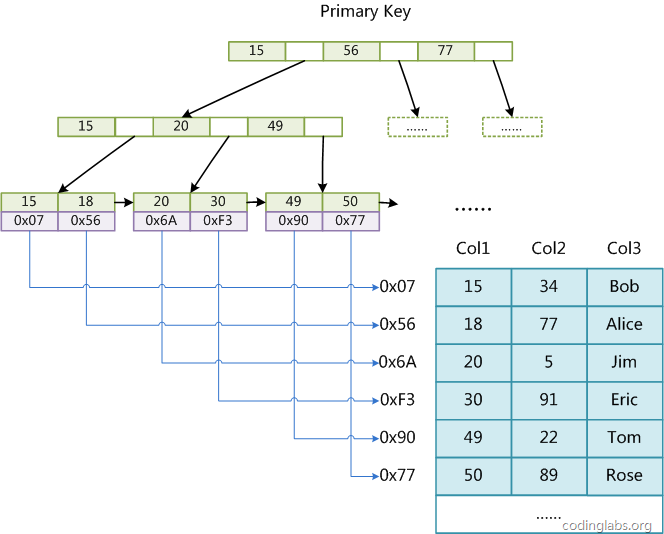
这里设表一共有三列,假设我们以Col1为主键,则上图是一个MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引文件仅仅保存数据记录的地址,这种索引方式叫做非聚集索引。在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。如果我们在Col2上建立一个辅助索引,则此索引的结构如下图所示:
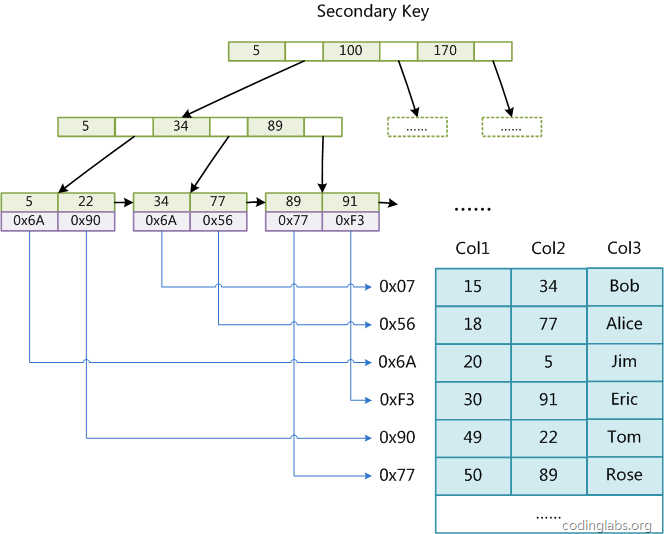
同样也是一颗B+Tree,data域保存数据记录的地址。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
MyISAM表是独立于操作系统的,说明可以轻松地将其从Windows服务器移植到Linux服务器。每当我们建立一个MyISAM引擎的表时,就会在本地磁盘上建立三个文件,文件名就是表名。例如,我建立了一个MyISAM引擎的tb_Demo表,那么就会生成以下三个文件:
- tb_demo.frm,存储表定义;
- tb_demo.MYD,存储数据;
- tb_demo.MYI,存储索引。
MyISAM存储引擎特别适合在以下几种情况下使用:
- 选择密集型的表。MyISAM存储引擎在筛选大量数据时非常迅速,这是它最突出的优点。
- 插入密集型的表。MyISAM的并发插入特性允许同时选择和插入数据。例如:MyISAM存储引擎很适合管理邮件或Web服务器日志数据。
InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同。
第一个重大区别是InnoDB的数据文件本身就是索引文件。从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
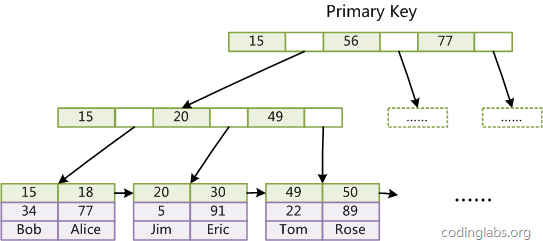
上图就是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引也叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是记录存储的地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域。例如,图11为定义在Col3上的一个辅助索引:
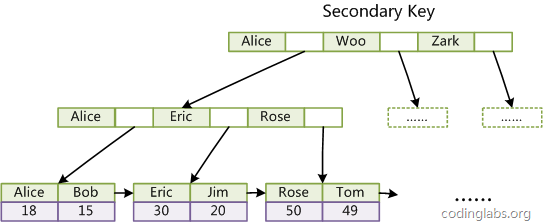
这里以英文字符的ASCII码作为比较准则。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
在使用InnoDB存储引擎时,如果没有特别的需要,请永远使用一个与业务无关的自增字段作为主键。如果从数据库索引优化角度看,使用InnoDB引擎而不使用自增主键绝对是一个糟糕的主意。
因为使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页。这样就会形成一个紧凑的索引结构,近似顺序填满。由于每次插入时也不需要移动已有数据,因此效率很高,也不会增加很多开销在维护索引上。
相比 MyISAM 来说,InnoDB 还支持:
- 事务(ACID);
- 外键约束;
- 行锁定。
MySQL: InnoDB 还是 MyISAM?
MySQL索引背后的数据结构及算法原理
MySQL索引原理及慢查询优化
MySQL存储引擎介绍