例子:你想数出一摞牌中有多少张黑桃。直观方式是一张一张检查并且数出有多少张是黑桃。
MapReduce方法则是:
- 给在座的所有玩家中分配这摞牌
- 让每个玩家数自己手中的牌有几张是黑桃,然后把这个数目汇报给你
- 你把所有玩家告诉你的数字加起来,得到最后的结论
谷歌在2004年发表了可以分析大量数据的 MapReduce 算法。MapReduce通过把计算量分配给不同的计算机群,能够解决大部分和大数据有关的分析问题。Hadoop提供了最受欢迎的利用MapReduce算法来管理大数据的开源方式。
MapReduce合并了两种经典函数:
映射(Mapping):对集合里的每个目标应用同一个操作。即,如果你想把表单里每个单元格乘以二,那么把这个函数单独地应用在每个单元格上的操作就属于mapping。化简(Reducing ):遍历集合中的元素来返回一个综合的结果。即,输出表单里一列数字的和这个任务属于reducing。
大规模数据处理时,Hadoop 在三个层面上的基本构思如下:
- 如何对付大数据处理:
分而治之。对相互间不具有计算依赖关系的大数据,实现并行最自然的办法就是采取分而治之的策略; - 上升到抽象模型:
Mapper与Reducer。MPI等并行计算方法缺少高层并行编程模型,为了克服这一缺陷,MapReduce借鉴了Lisp函数式语言中的思想,用Map和Reduce两个函数提供了高层的并行编程抽象模型; - 上升到构架:
统一构架,为程序员隐藏系统层细节。MPI等并行计算方法缺少统一的计算框架支持,程序员需要考虑数据存储、划分、分发、结果收集、错误恢复等诸多细节;为此,MapReduce设计并提供了统一的计算框架,为程序员隐藏了绝大多数系统层面的处理细节。
什么样的计算任务可进行并行化计算?
并行计算的第一个重要问题是如何划分计算任务或者计算数据以便对划分的子任务或数据块同时进行计算。
但一些计算问题恰恰无法进行这样的划分!(Nine women cannot have a baby in one month!)。例如Fibonacci函数,前后数据项之间存在很强的依赖关系!只能串行计算!
结论:不可分拆的计算任务或相互间有依赖关系的数据无法进行并行计算!
一个大数据若可以分为具有同样计算过程的数据块,并且这些数据块之间不存在数据依赖关系,则提高处理速度的最好办法就是并行计算。例如:假设有一个巨大的2维数据需要处理(比如求每个元素的开立方),其中对每个元素的处理是相同的,并且数据元素间不存在数据依赖关系,可以考虑不同的划分方法将其划分为子数组,由一组处理器并行处理。
函数式程序设计(functional programming)语言Lisp是一种列表处理语言(List processing),提供了类似于Map和Reduce的操作:
- Map: 对一组数据元素进行某种重复式的处理
- Reduce: 对Map的中间结果进行某种进一步的结果整合
MapReduce 借鉴了函数式程序设计语言 Lisp 中的思想,定义了如下的Map和Reduce两个抽象的编程接口,由用户去编程实现:
map: (k1; v1) → [(k2; v2)] 输入:键值对(k1; v1)表示的数据 处理:文档数据记录(如文本文件中的行,或数据表格中的行)将以“键值对”形式传入map函数;map函数将处理这些键值对,并以另一种键值对形式输出处理的一组键值对中间结果[(k2; v2)] 输出:键值对[(k2; v2)]表示的一组中间数据
reduce: (k2; [v2]) → [(k3; v3)] 输入:由map输出的一组键值对[(k2; v2)] 将被进行合并处理将同样主键下的不同数值合并到一个列表[v2]中,故reduce的输入为(k2; [v2]) 处理:对传入的中间结果列表数据进行某种整理或进一步的处理,并产生最终的某种形式的结果输出[(k3; v3)] 。 输出:最终输出结果[(k3; v3)]
Map和Reduce为程序员提供了一个清晰的操作接口抽象描述。具体流程如下:
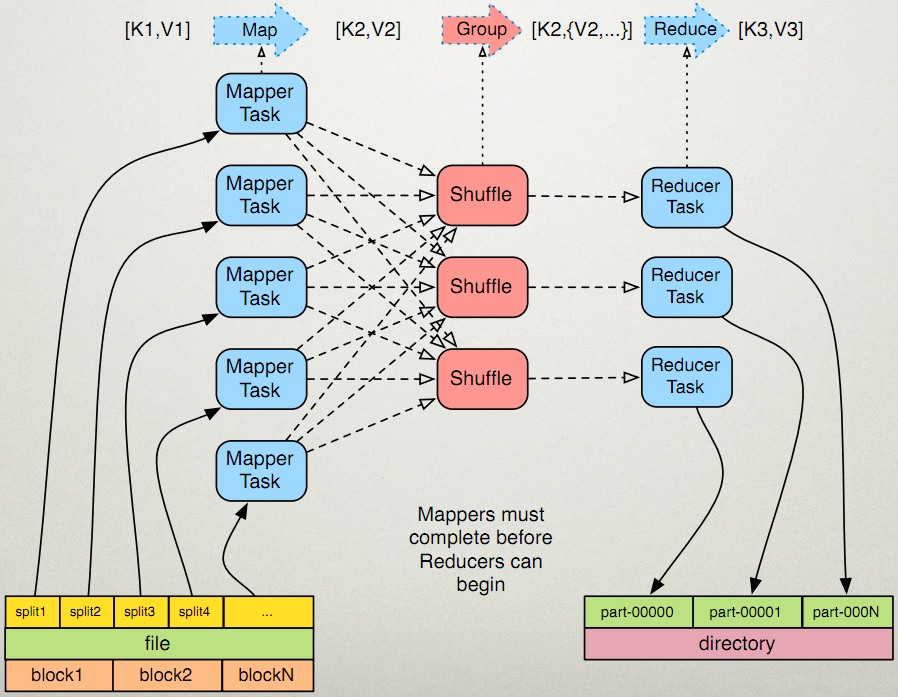
可以发现:
- 各个map函数对所划分的数据并行处理,从不同的输入数据产生不同的中间结果输出。
- 进行reduce处理之前,必须等到所有的map函数做完,因此在进入reduce前需要有一个同步障(barrier)。这个阶段负责对map的中间结果数据进行收集整理(aggregation & shuffle)处理,以便reduce更有效地计算最终结果。
- 各个reduce也各自并行计算,各自负责处理不同的中间结果数据集合。
- 最终汇总所有reduce的输出结果即可获得最终结果。
Hadoop 通过抽象模型和计算框架把需要做什么(what)与具体怎么做(how)分开了,为程序员提供一个抽象和高层的编程接口和框架。程序员仅需要关心其应用层的具体计算问题,仅需编写少量的处理应用本身计算问题的程序代码。
如何具体完成这个并行计算任务所相关的诸多系统层细节被隐藏起来,交给计算框架去处理:从分布代码的执行,到大到数千小到单个节点集群的自动调度使用。
MapReduce提供一个统一的计算框架,可完成:
- 计算任务的划分和调度
- 数据的分布存储和划分
- 处理数据与计算任务的同步
- 结果数据的收集整理(sorting, combining, partitioning,…)
- 系统通信、负载平衡、计算性能优化处理
- 处理系统节点出错检测和失效恢复
如何简单解释 MapReduce 算法
MapReduce原理与设计思想
Spark:一个高效的分布式计算系统
Hadoop Map/Reduce 执行流程详解