DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
Task: Text2Image
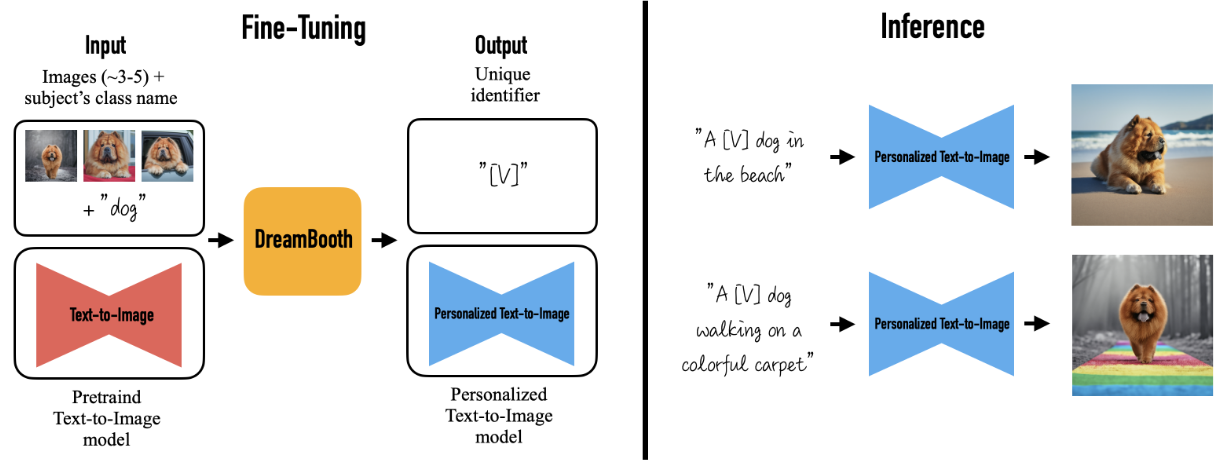
Large text-to-image models achieved a remarkable leap in the evolution of AI, enabling high-quality and diverse synthesis of images from a given text prompt. However, these models lack the ability to mimic the appearance of subjects in a given reference set and synthesize novel renditions of them in different contexts. In this work, we present a new approach for "personalization" of text-to-image diffusion models. Given as input just a few images of a subject, we fine-tune a pretrained text-to-image model such that it learns to bind a unique identifier with that specific subject. Once the subject is embedded in the output domain of the model, the unique identifier can be used to synthesize novel photorealistic images of the subject contextualized in different scenes. By leveraging the semantic prior embedded in the model with a new autogenous class-specific prior preservation loss, our technique enables synthesizing the subject in diverse scenes, poses, views and lighting conditions that do not appear in the reference images. We apply our technique to several previously-unassailable tasks, including subject recontextualization, text-guided view synthesis, and artistic rendering, all while preserving the subject's key features. We also provide a new dataset and evaluation protocol for this new task of subject-driven generation.
| Model | Dataset | Download |
|---|---|---|
| DreamBooth | - | - |
| DreamBooth (Finetune Text Encoder) | - | - |
| DreamBooth with Prior-Preservation Loss | - | - |
| DreamBooth LoRA | - | - |
| DreamBooth LoRA with Prior-Preservation Loss | - | - |
- Download data and save to
data/dreambooth/
The file structure will be like this:
data
└── dreambooth
└──imgs
├── alvan-nee-Id1DBHv4fbg-unsplash.jpeg
├── alvan-nee-bQaAJCbNq3g-unsplash.jpeg
├── alvan-nee-brFsZ7qszSY-unsplash.jpeg
└── alvan-nee-eoqnr8ikwFE-unsplash.jpeg
- Start training with the following command:
bash tools/dist_train.sh configs/dreambooth/dreambooth.py 1
# or
bash tools/dist_train.sh configs/dreambooth/dreambooth-lora.py 1

'dreambooth' |

'dreambooth-lora' |
We support tomesd now! It is developed for stable-diffusion-based models referring to ToMe, an efficient ViT speed-up tool based on token merging. To work on with tomesd in mmagic, you just need to add tomesd_cfg to model in DreamBooth. The only requirement is torch >= 1.12.1 in order to properly support torch.Tensor.scatter_reduce() functionality. Please do check it before running the demo.
model = dict(
type='DreamBooth',
...
tomesd_cfg=dict(ratio=0.5),
...
val_prompts=val_prompts)For more details, you can refer to Stable Diffusion Acceleration.
Our codebase for the stable diffusion models builds heavily on diffusers codebase and the model weights are from stable-diffusion-1.5.
Thanks for the efforts of the community!
@article{ruiz2022dreambooth,
title={Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation},
author={Ruiz, Nataniel and Li, Yuanzhen and Jampani, Varun and Pritch, Yael and Rubinstein, Michael and Aberman, Kfir},
journal={arXiv preprint arXiv:2208.12242},
year={2022}
}