Machine Learning pe uma campo da inteligência Artifical que visa explorar estudos e contruçes de algoritimos que possibilitam compreender de maneira autônoma. É possivel ser capaz com o ML de reconhecer e extrair padrôes de um grande volume de dados, contruindo dessa maneira um modelo de aprendizado. Esse aprendizado é baseado na observação de dados.
1. Aprendizado supervisionado: São apresentadas ao computador exemplos de entradas e saídas desejadas, fornecidas por um "professor". O objetivo é aprender uma regra geral que mapeia as entradas para as saídas.
2. Aprendizado não supoervisionado: Nenhum tipo de etiqueta é dado ao algoritmo de aprendizado, deixando-o sozinho para encontrar estrutura nas entradas fornecidas. O aprendizado não supervisionado pode ser um objetivo em si mesmo (descobrir novos padrões nos dados) ou um meio para atingir um fim.
3. Aprendizado por reforço: Um program de computador interage com um ambiente dinâmico, em que o programa deve desempenhar determinado objetivo (por exemplo, dirigir um veículo). É fornecido, ao programa, feedback quanto a premiações e punições, na medida em que é navegado o espaço do problema. Outro exemplo de aprendizado por reforço é aprender a jogar um determinado jogo apenas jogando contra um oponente.
Muitas de nossas atividades diaárias mais simpes são alimentadas por algoritmos de machine learning que podem incluir:
- Detecção de fraudes em compras de cartão de crédito.
- Resultados de pesquisa na Web
- Anúncio em tempo real, tanto em páginas da web como em dispositivos móveis
- Análise de sentimento baseada em texto
- Pontuação de cŕedito e melhores ofertas.
- Previsão de falhas em equipamentos.
- Novos modelos de precificação
- Detecção de invasão em uma determinada rede.
- Reconhecimento de determinado padrões de imagens.
- Filtragem de spams em e-mail
- Reconhecimento de vóz
- Veiculos Autonomos
- etc...
Conforme podemos imaginar, dados de treino são os dados que serão apresentados ao algoritmo de ML para criação do modelo. Estes dados costumam representar cerca de 70% da totalidade dos dados.
Serão apresentados ao modelo após a sua criação, simulando previsões reais que o modelo realizará, permitindo assim que o desempenho real seja verificado. Estes dados costumam representar cerca de 30% da totalidade dos dados.
É importante observar que a separação dos dados em treino e teste é uma etapa essencial, e que caso ela seja realizada de maneira errada, poderá resultar em problemas no modelo.
Imagine que você tenha dados sobre vinte mil carros, com algumas características e o valor deles. Você decide que irá utilizar quinze mil amostras para treinar seu modelo, e para isso seleciona as quinze mil primeiras linhas, deixando a últimas cinco mil para teste. Porém estas linhas estavam organizadas em ordem alfabética com base nos nomes dos carros. Percebem o problema? Alguns modelos de carros específicos estarão presentes apenas nos dados de treino, e outros apenas nos dados de teste.
Esta situação levará a um modelo deficiente, que não aprendeu com todos os tipos de dados que poderia e que também não será testado de maneira correta. Afinal, nos dados de teste haverão apenas modelos de carros que começam, digamos, com as letras S, T, U, V, X, Y, Z (final do alfabeto).
A solução para este problema está na aleatoriedade. Selecionando os dados de maneira aleatória não haverá padrão algum no momento da divisão dos dados, e cada observação terá a mesma probabilidade de ser selecionada.
Overfitting(sobreajuste ou superajuste) e Underfitting(sub-ajuste) em ML são classificações ou conceitos em ajuste do modelo.
Overfitting : Ocorre quando o modelo se adaptou muito bem aos dados com os quais está sendo treinado; porém, não generaliza bem para novos dados. Ou seja, o modelo "decorou" o conjunto de dados de treino, mas não aprendeu de fato oque diferencia aqueles dados para quando precisar enfrentar novos testes.
Underfitting : Ocorre quando o modelo não se adapta bem sequer aos dados com os quais foi treinado.
Veja no gráfico como são representados:
- Definindo o problema
- Conhecendo os dados
- Preparando os dados
- Escolhendo o método de mediação de desempenho
- Verificando os melhores algoritmos
- Encontrando os melhores resultados
- Apresentando os resultados finais

Os problemas de regressão existem quando precisamos prever um valor numérico específico. Este valor pode ser o preço de um produto, o peso ou altura de uma pessoas, a metragem de uma casa, e assim por diante. Nestas situações, o modelo poderá apresentar como resposta qualquer valor. Por exemplo, você pode apresentar produtos e seus preços para que o algorimo crie o modelo, e ainda que nestes produtos não exista nenhum preloi superior a R$ 100,00 o modelo poderá realizar previsões de preços superiores a este valor.
Os problemas de classificação são aqueles onde se busca encontrar uma classe, dentro das possibilidades limitadas existentes. Esta classe pode ser um aluno foi aprovado ou reprovado, se uma pessoa possui uma doença ou não, dentre outras tantas possibilidades, sendo que nestes casos ou a previsão será uma ou outra. As classes também podem possuir mais de duas opções, como separar pessoas em três grupos, A, B, C, ou 1, 2 e 3,ou ainda prever a marca de um determinado carro. Pensando naideia da marca de um carro é importante observarmos que, por mais opções de marcas que possam existir, esta quantidade sempre terá um valor finito, e o modelo nunca terácomo resultado uma marca ( ou informaçao alguma) que ele não conheça.
Viés define o quão flexivel seu modelo é em relação aos dados, já a variança determina a quantidade de erros que seu modelo possui. Um modelo ideal teria um baixo viés e baixa variância. Encontrar um meio-termo ideal entre viés e variaância não é uma tarefa fácil.

A árvore de decisão é um tipo de algoritmo de apoio, cuja dinâmica de funcionamento é baseada em um gráfico ou modelo de decisôes alinhado com as suas possíveis consequências. Além disso, o sistema de árvore leva em consideração resultados de eventos fortuitos, os custos e utilidades dos recursos. Sob a ótica da tomada de decisôes de um negócio, a árvore de decisões é representada por um número mínimo de perguntas. Com base nas respostas, avalia-se a probabilidade de tomar decisões acertadas.

A regressão linear é chamada "linear" porque se considera que a relação da resposta às variáveis é uma função linear de alguns parâmetros. Os modelos de regressão que não são uma função linear dos parâmetros se chamam modelos de regressão não-linear. Sendo uma das primeiras formas de análise regressiva a ser estudada rigorosamente, e usada extensamente em aplicações práticas. Isso acontece porque modelos que dependem de forma linear dos seus parâmetros desconhecidos, são mais fáceis de ajustar que os modelos não-lineares aos seus parâmetros, e porque as propriedades estatísticas dos estimadores resultantes são fáceis de determinar.
Modelos de regressão linear são frequentemente ajustados usando a abordagem dos mínimos quadrados, mas que também pode ser montada de outras maneiras, tal como minimizando a "falta de ajuste" em alguma outra norma (com menos desvios absolutos de regressão), ou através da minimização de uma penalização da versão dos mínimos quadrados. Por outro lado, a abordagem de mínimos quadrados pode ser utilizado para ajustar a modelos que não são modelos lineares. Assim, embora os termos "mínimos quadrados" e "modelo linear" estejam intimamente ligados, eles não são sinônimos
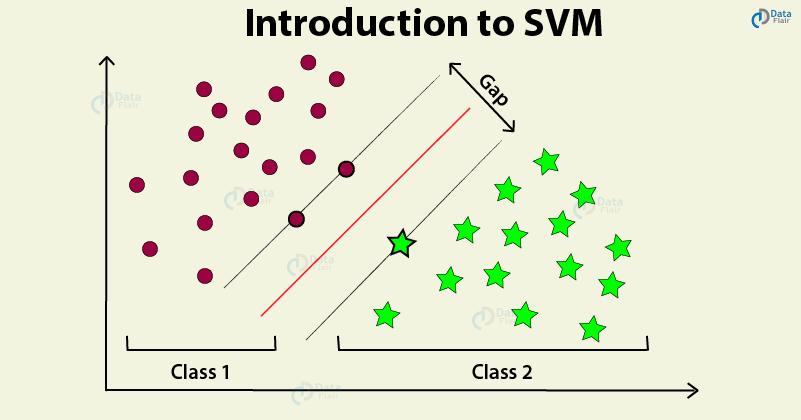
O Support Vector Machine (SVM) é um algoritmo binário de classificação. A metodologia é utilizada quando preciso desmembrar dois tipos de situações, que são linearmente separáveis. Com essa escala, podemos resolver diversos tipos de problemas.
O SVM já foi aproveitado, por exemplo, para reconhecimento de site de splice humano, detecção de gênero a partir de imagens, publicidades em displays, entre outras tarefas mais complexas.

A regressão logística é o algoritmo voltado para a medir a relação entre uma variável categórica e outras variáveis independentes. Uma forma estatística para modelar resultados binomiais. Na prática, esse poderoso algoritmo pode ser empregado em aplicações reais, como:
- Previsão de receitas de determinado produto;
- Pontuação de crédito;
- mensuração do índice de sucesso das campanhas de marketing, entre outras.

Baseada no Teorema de Bayes, essa técnica considera que todas as características contribuem de maneira independente para determinada resposta, ainda que umas dependam das outras. Trata-se de um método de classificação calculado por meio de probabilidades.
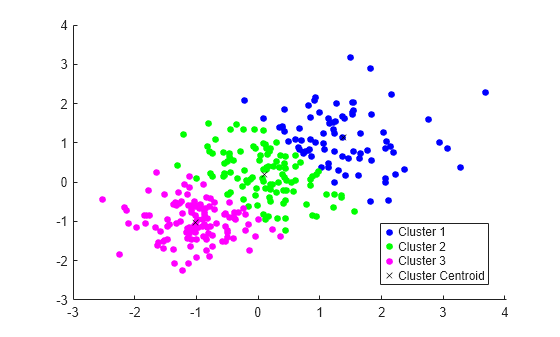
É a ferramenta que agrupa objetos de acordo com os aspectos apresentados em comum. Portanto, cada algoritmo de agrupamento sempre será diferente — podemos encontrar algoritmos de conectividade, de redes neurais, de densidade etc.