Promscale is a stateless service, thus it can run safely with multiple replicas. A load-balancer can simply route Promscale requests to any replica.
Promscale supports running Prometheus in High Availability (HA). This means that you can have multiple Prometheus instances running as "HA pairs". Such "HA pairs" (what we will call clusters from now on) are simply two or more identical Prometheus instances running on different machines/containers. These instances scrape the same targets and should thus have very similar data (the differences occur because scrapes happen at slightly different times). You can think of a cluster as a group of similar Prometheus instances that are all scraping the same targets and replicas as individual Prometheus instance in that group.
Promscale supports de-duplicating data coming from such HA clusters upon ingest. It does this by electing a leader Prometheus instance and only ingesting data from that leader. If the leader Prometheus stops sending data to Promscale for any reason, Promscale will fail-over to the other Prometheus instance.
Promscale supports having multiple clusters sending data to the same set of Promscale instances. It will elect one leader per cluster.
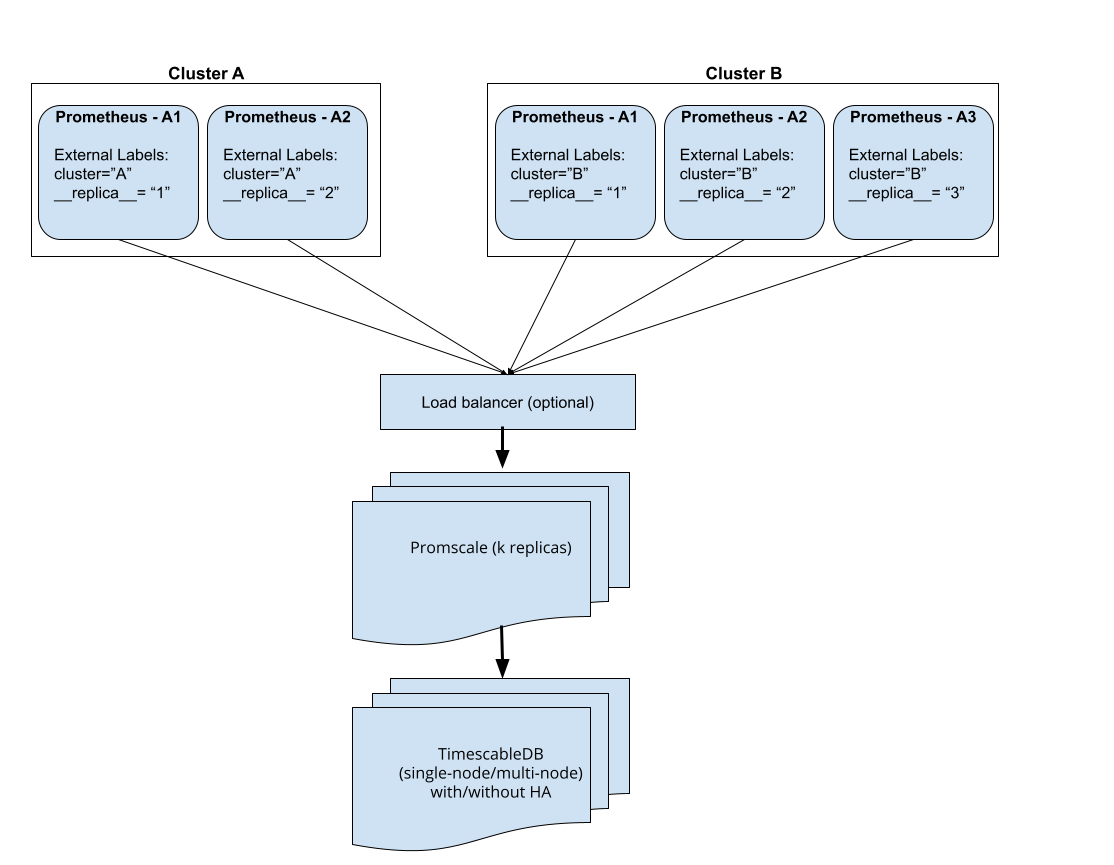
To set up Promscale to process data from Prometheus running in HA mode,
Prometheus must be configured to communicate which cluster it belongs to
using external labels. In particular, each Prometheus should send a cluster
label to indicate which cluster it's in and a __replica__ label that
provides a unique identifier for the Prometheus instance with the cluster.
Two Prometheus instances running as part of a HA cluster, MUST send the same
cluster label and different __replica__ labels.
In Kubernetes environments, it is often useful to set the __replica__
label to the pod name, and the cluster name as the Prometheus deployment/statefulset name. When using the Prometheus Operator this can be done
with the following settings:
replicaExternalLabelName: "__replica__"
prometheusExternalLabelName: "cluster"
In bare metal and other environments, you need to configure external labels with the cluster and replica names in each Prometheus instance config as mentioned below:
global:
external_labels:
__replica__: <REPLICA_NAME> (This should be unique name of the Prometheus instance)
cluster: <CLUSTER_NAME> (This should be the name of the Prometheus deployment, which should be common across the Prometheus replica instances.)
After Prometheus instances are configured to send the correct labels,
Promscale simply needs to be started with the -metrics.high-availability CLI flag.
Internally, Promscale will elect a single replica per cluster to be the
current leader. Only data sent from that replica will be ingested. If that
leader-replica stops sending data, then a new replica will be elected as the
leader.