Cuda tried allocating an enormous amount of memory (1936GiB) #10528
Comments
|
👋 Hello @BilboBaguette, thank you for your interest in YOLOv5 🚀! Please visit our ⭐️ Tutorials to get started, where you can find quickstart guides for simple tasks like Custom Data Training all the way to advanced concepts like Hyperparameter Evolution. If this is a 🐛 Bug Report, please provide screenshots and minimum viable code to reproduce your issue, otherwise we can not help you. If this is a custom training ❓ Question, please provide as much information as possible, including dataset images, training logs, screenshots, and a public link to online W&B logging if available. For business inquiries or professional support requests please visit https://ultralytics.com or email support@ultralytics.com. RequirementsPython>=3.7.0 with all requirements.txt installed including PyTorch>=1.7. To get started: git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # installEnvironmentsYOLOv5 may be run in any of the following up-to-date verified environments (with all dependencies including CUDA/CUDNN, Python and PyTorch preinstalled):
Status
If this badge is green, all YOLOv5 GitHub Actions Continuous Integration (CI) tests are currently passing. CI tests verify correct operation of YOLOv5 training, validation, inference, export and benchmarks on MacOS, Windows, and Ubuntu every 24 hours and on every commit. |


|
@BilboBaguette 👋 Hello! Thanks for asking about CUDA memory issues. YOLOv5 🚀 can be trained on CPU, single-GPU, or multi-GPU. When training on GPU it is important to keep your batch-size small enough that you do not use all of your GPU memory, otherwise you will see a CUDA Out Of Memory (OOM) Error and your training will crash. You can observe your CUDA memory utilization using either the
CUDA Out of Memory SolutionsIf you encounter a CUDA OOM error, the steps you can take to reduce your memory usage are:
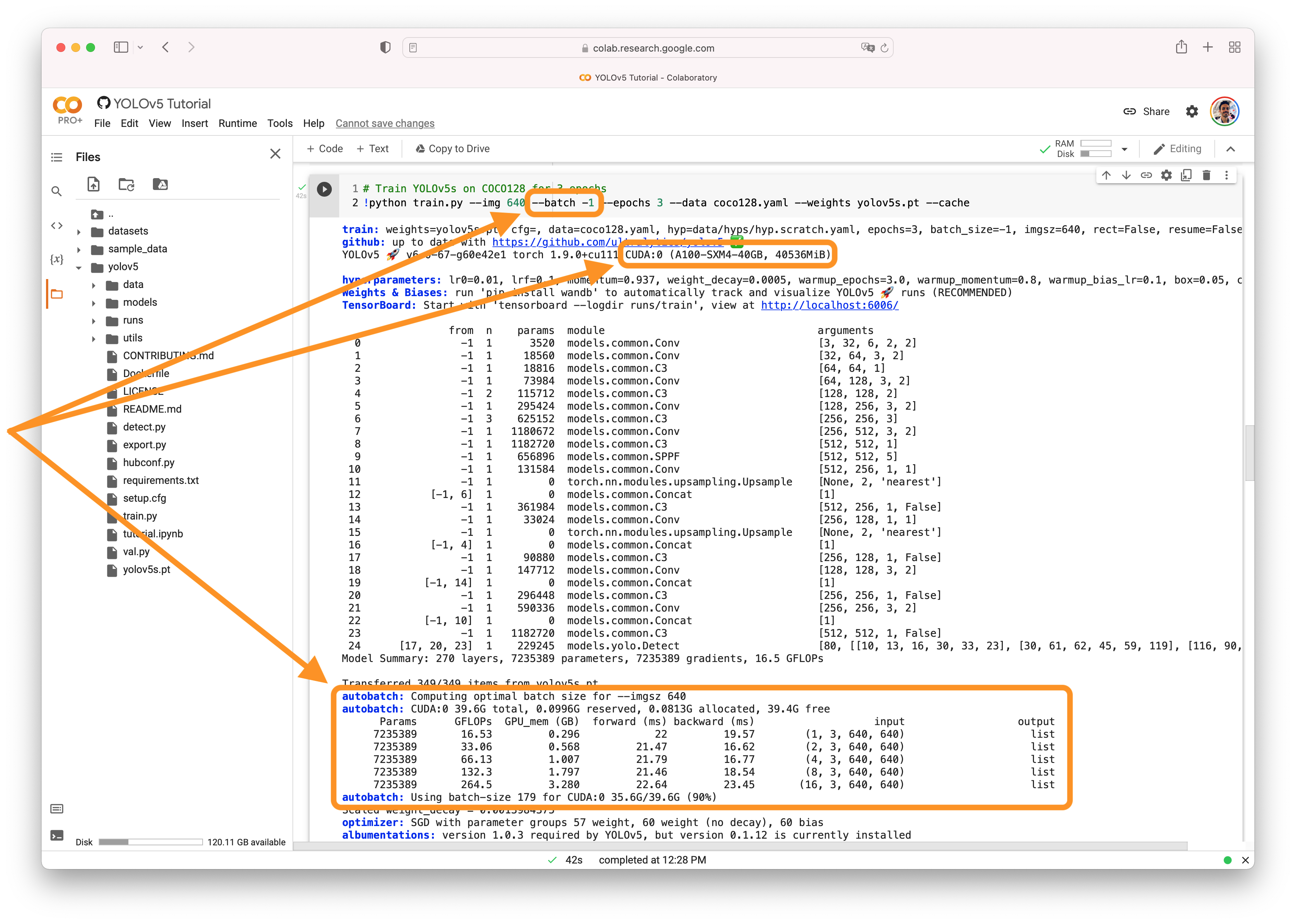
AutoBatchYou can use YOLOv5 AutoBatch (NEW) to find the best batch size for your training by passing
Good luck 🍀 and let us know if you have any other questions! |

|
👋 Hello, this issue has been automatically marked as stale because it has not had recent activity. Please note it will be closed if no further activity occurs. Access additional YOLOv5 🚀 resources:
Access additional Ultralytics ⚡ resources:
Feel free to inform us of any other issues you discover or feature requests that come to mind in the future. Pull Requests (PRs) are also always welcomed! Thank you for your contributions to YOLOv5 🚀 and Vision AI ⭐! |
我将这个参数改成了 -1,自动处理,已经解决此问题 |
|
@Adreaming5101 太好了!感谢您分享解决方案。如果您有其他问题,请随时告诉我们。祝您使用 YOLOv5 顺利! ✨ |
Search before asking
YOLOv5 Component
Training
Bug
Hi, new to YOLO, I am getting this error message when training YOLOv5x6:
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 1936.00 GiB (GPU 1; 11.17 GiB total capacity; 2.15 GiB already allocated; 7.62 GiB free; 3.02 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
For context, I am trying to train YOLOv5x6 on the PubLayNet datatset (article here, github here) to compare the results with the DocLayNet dataset that has already been tested on YOLOv5x6 (article here, github here)
I am doing this using base image size of 640, batch size of 8 and running distributed data parallel mode on 2 K80 GPUs.
During training, memory usage is normal as can be seen below:
But about 80% through the first epoch I get the above error message. Any clues as to why the model would try to allocate such an enormous amount of memory and how to fix it ?
Environment
Minimal Reproducible Example
No response
Additional
No response
Are you willing to submit a PR?
The text was updated successfully, but these errors were encountered: